


Organizations generate and manage enormous volumes of contracts across procurement, compliance, vendor management, legal operations, and financial workflows. These agreements contain business-critical information such as renewal dates, payment terms, liability clauses, confidentiality obligations, governing jurisdictions, and service-level commitments. Despite their operational importance, much of this information remains trapped inside PDFs, scanned files, email attachments, and static repositories that are difficult to search, validate, or automate.
Extract contract metadata workflows address this by transforming unstructured legal agreements into structured, machine-readable data. Modern systems combine layout-aware parsing, machine learning, semantic extraction, and schema mapping to identify contractual information while preserving the relationships between clauses, obligations, and context. The goal is no longer simply digitizing contracts, but building operational systems that turn legal documents into structured intelligence supporting analytics, compliance oversight, workflow automation, and downstream integration.
For organizations already modernizing workflows such as invoice automation, mortgage document processing, or financial document extraction, contract metadata extraction becomes a natural extension of broader enterprise automation initiatives.
Why Contract Metadata Extraction Is Difficult
Contract documents introduce challenges that differ significantly from standard OCR workflows. Unlike invoices or structured forms, contracts are highly variable in structure, formatting, terminology, and drafting style. Two agreements serving the same operational purpose may organize information differently, use entirely different legal language, or distribute key obligations across multiple sections and appendices.
Traditional OCR systems can recognize text, but they cannot reliably interpret contractual meaning. A payment term may appear under “Commercial Terms,” “Compensation,” “Billing Obligations,” or “Fees and Charges” depending on the drafting convention. Renewal conditions are frequently embedded within lengthy paragraphs rather than isolated as standalone fields. Termination provisions may span multiple sections with cross-references to amendments or appendices.
This variability creates operational complexity for legal teams and downstream systems. Metadata extraction workflows must distinguish between similar but materially different contractual conditions. An automatic renewal clause requires different handling from a conditional renewal clause. A liability limitation provision carries different legal implications than a general indemnification clause. These distinctions are operationally significant because they directly affect compliance obligations, vendor risk exposure, procurement controls, and contract lifecycle workflows.
Document structure introduces additional complexity. Enterprise agreements frequently contain multi-column layouts, embedded tables, scanned signatures, handwritten annotations, appendices, exhibits, nested clauses, and cross-referenced amendments distributed across separate files. Without layout-aware parsing and structural reconstruction, extracted text loses the contextual relationships that define contractual meaning.
This is why production-grade contract metadata extraction systems increasingly resemble broader intelligent document processing platforms rather than standalone OCR tools. Similar architectural principles are already visible across workflows such as OCR for insurance documents, real estate document automation, and enterprise finance extraction systems, where structural understanding matters more than character recognition alone.
What Contract Metadata Means in Enterprise Workflows
Unlike invoices or structured forms, contracts are highly variable in structure, formatting, terminology, and drafting style. A payment term may appear under "Commercial Terms," "Compensation," or "Fees and Charges" depending on drafting convention. Renewal conditions are often buried in lengthy paragraphs. Termination provisions may span multiple sections with cross-references to amendments or appendices.
Traditional OCR systems can recognize text but cannot interpret contractual meaning. An automatic renewal clause requires different handling from a conditional one. A liability limitation carries different implications than a general indemnification clause. These distinctions directly affect compliance obligations, vendor risk exposure, and procurement controls across contract lifecycle management (CLM) and financial OCR automation workflows.
Enterprise agreements also frequently contain multi-column layouts, embedded tables, scanned signatures, and cross-referenced amendments across separate files. Without layout-aware parsing, extracted text loses the contextual relationships that define contractual meaning. This is why production-grade extraction systems increasingly resemble broader enterprise search systems rather than standalone OCR tools.
The diagram below illustrates how metadata extraction fits into a full contract lifecycle workflow, from ingestion through compliance monitoring and renewal.
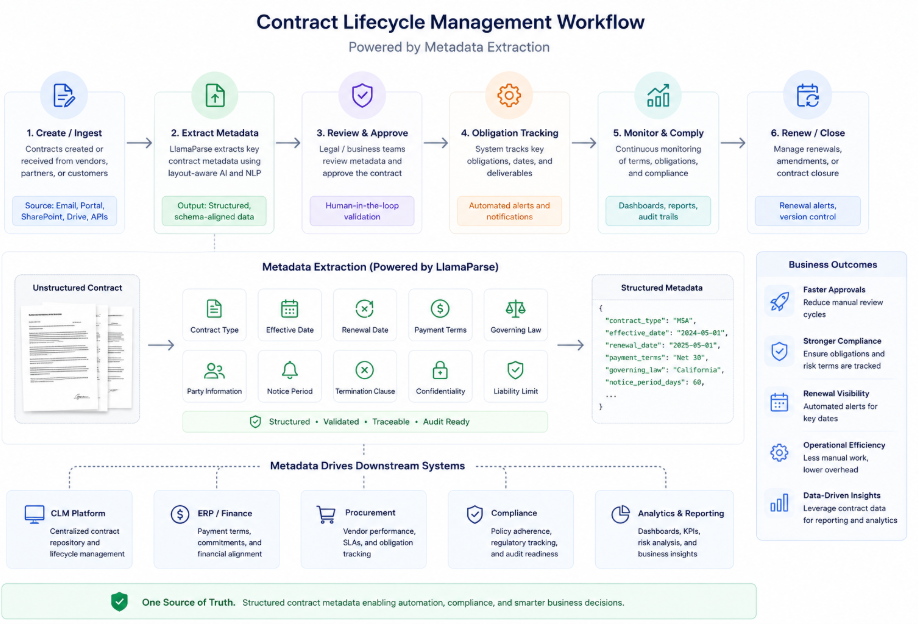
How Contract Metadata Extraction Works
Modern metadata extraction workflows operate through multiple coordinated stages rather than a single OCR step. Each stage contributes to reconstructing contractual information in a structured and operationally reliable form.
Document Ingestion and Normalization
The workflow begins with document ingestion. Contracts may arrive through email attachments, procurement systems, legal repositories, third-party uploads, or scanned archives. These documents frequently exist in inconsistent formats including digitally generated PDFs, scanned image files, photographs, and compressed archives.
A production-ready ingestion layer normalizes these inputs into standardized representations before downstream processing begins. File conversion, orientation correction, image normalization, and metadata identification help ensure consistent parsing behavior across heterogeneous document sources. Without normalization, layout-aware extraction models often produce inconsistent outputs because the same contractual structure may appear differently depending on scan quality or file encoding.
Layout-Aware Parsing
Once normalized, the document enters the parsing stage. Layout-aware models analyze structural components such as clause sections, headings, tables, footnotes, appendices, signature blocks, metadata regions, and amendment references.
Unlike traditional OCR systems that flatten documents into sequential text streams, layout-aware parsing preserves structural relationships throughout extraction. This allows the system to understand where obligations appear within the hierarchy of the agreement rather than treating all extracted text equally.
This architectural approach is increasingly common across enterprise OCR workflows, including systems designed for structured document automation, financial document intelligence, and enterprise search indexing.
Clause Detection and Semantic Extraction
After structural parsing, semantic extraction models identify contractual clauses and metadata fields. Machine learning models analyze legal language patterns to detect payment obligations, confidentiality clauses, governing law provisions, indemnification terms, renewal conditions, notice periods, and service-level commitments.
Rather than relying solely on keyword matching, modern extraction systems use contextual reasoning to distinguish between similar legal constructs. This significantly improves extraction reliability across different contract types, jurisdictions, and drafting styles.
For example, the phrase “This agreement shall renew automatically unless terminated with sixty days written notice” must be interpreted differently from “This agreement may be renewed upon mutual written consent.” Although both mention renewal, their operational implications are materially different.
Schema Mapping and Validation
After extraction, metadata values are mapped into predefined schema fields. Validation workflows verify consistency across extracted metadata before synchronization with downstream systems.
Renewal dates may be validated against contract duration. Payment terms may be normalized into standardized billing structures. Governing law clauses may be mapped into jurisdiction taxonomies. Notice windows may be reconciled against termination conditions.
Confidence scoring mechanisms determine whether extracted metadata can proceed automatically or should enter human review workflows. This combination of machine learning and validation orchestration is essential for maintaining operational reliability within enterprise legal environments.
Real-World Challenges in Contract Metadata Extraction
Even with advanced AI-powered systems, production contract extraction workflows continue to face operational challenges that extend beyond OCR accuracy.
Legal Language Variability
Contracts rarely follow standardized drafting conventions. Similar obligations may be expressed using entirely different legal terminology across vendors, industries, and jurisdictions. Extraction systems must generalize across these variations without introducing semantic inaccuracies that could affect compliance or operational workflows.
Multi-Document Relationships
Enterprise workflows frequently involve amendments, exhibits, appendices, schedules, and supplemental agreements connected to a primary contract. Metadata extraction systems must reconcile information across multiple related documents while preserving auditability and version control.
Clause Ambiguity
Certain contractual obligations cannot be interpreted through deterministic logic alone. Liability caps, indemnification scopes, renewal conditions, and exception clauses frequently require contextual interpretation that varies depending on organizational policy, legal guidance, or jurisdiction.
Governance and Compliance Requirements
Legal workflows require traceability and defensibility. Every extracted metadata field must remain linked to its originating clause, confidence score, extraction history, and review workflow. This is particularly important in regulated industries where contractual obligations influence compliance reporting and operational governance.
Organizations modernizing broader document workflows such as enterprise OCR automation increasingly apply the same governance principles to legal metadata extraction systems.
Extract Contract Metadata with LlamaParse
LlamaParse provides a structured approach to extracting contract metadata from complex legal documents. Rather than functioning as a standalone OCR engine, LlamaParse integrates layout-aware parsing, semantic extraction, schema mapping, and validation orchestration within a unified platform.
Within LlamaParse, contracts are analyzed using layout-aware models that preserve document hierarchy, clause relationships, section structures, table alignment, and contextual dependencies throughout extraction. This ensures metadata fields remain aligned with their originating clauses instead of being flattened into disconnected text blocks.
LlamaParse also supports schema-aligned extraction workflows that allow organizations to define metadata categories most relevant to their operational requirements. Legal teams can configure extraction targets for payment obligations, confidentiality clauses, liability limitations, governing law, renewal conditions, and lifecycle milestones without building entirely custom pipelines from scratch.
A key advantage of LlamaParse is its configuration-driven architecture. Organizations do not need to develop and maintain complex extraction infrastructure manually. Instead, teams configure extraction behavior, validation logic, schema definitions, and workflow orchestration within an adaptable environment designed to handle real-world document variability.
Confidence scoring and human-in-the-loop review workflows further strengthen operational reliability. Ambiguous clauses can be routed for manual verification while high-confidence metadata proceeds automatically into downstream systems.
Because LlamaParse integrates with broader intelligent document processing workflows, extracted contract metadata can flow directly into CLM platforms, ERP systems, procurement workflows, compliance reporting systems, analytics environments, and enterprise search platforms.
Organizations already investing in automation initiatives such as finance document extraction, legal OCR software, or enterprise document intelligence can extend similar architectural principles into contract intelligence workflows.
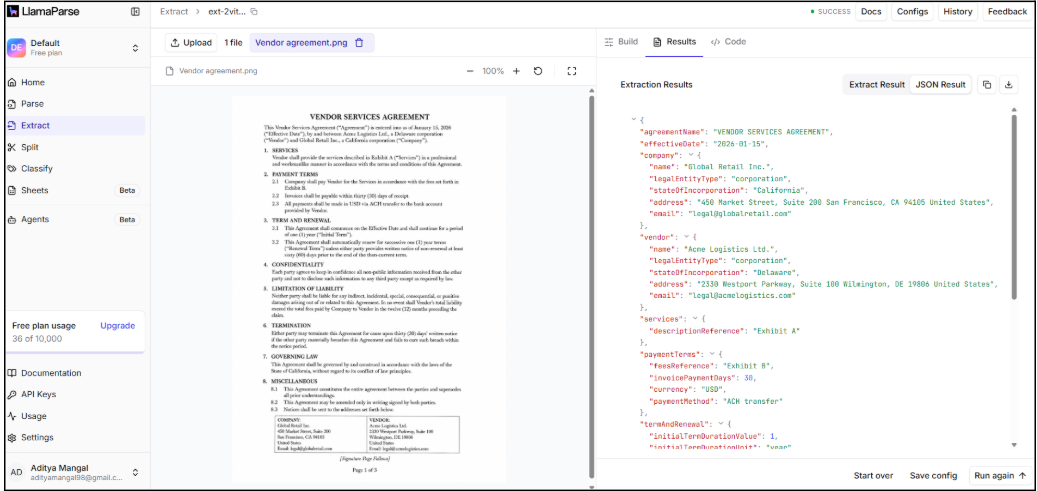
Practical Example: Extracting Metadata from a Vendor Agreement
To illustrate how extract contract metadata workflows operate in practice, consider a multi-page vendor services agreement processed within LlamaParse.

The agreement contains multiple metadata categories distributed across different sections, including effective dates, payment schedules, confidentiality obligations, liability limitations, renewal conditions, and termination clauses.
The workflow begins with ingestion and normalization. LlamaParse converts the uploaded document into a standardized representation optimized for layout-aware parsing and structural reconstruction.
Next, structural parsing reconstructs the hierarchy of the agreement. Headings, clause groups, subsections, appendices, and embedded tables are identified and linked contextually. This prevents extracted values from losing relationships with surrounding legal language.
Semantic extraction models then identify metadata fields throughout the contract. Consider the following contractual language:
“Invoices shall be payable within thirty (30) days of receipt.”
Rather than treating this as raw OCR text, LlamaParse extracts it into a structured schema-aligned representation that can integrate directly into downstream systems.
Example structured output:
html
{
"agreementName": "VENDOR SERVICES AGREEMENT",
"effectiveDate": "2026-01-15",
"company": {
"name": "Global Retail Inc.",
"legalEntityType": "corporation",
"stateOfIncorporation": "California",
"address": "450 Market Street, Suite 200\nSan Francisco, CA 94105\nUnited States",
"email": "legal@globalretail.com"
},
"vendor": {
"name": "Acme Logistics Ltd.",
"legalEntityType": "corporation",
"stateOfIncorporation": "Delaware",
"address": "2330 Westport Parkway, Suite 100\nWilmington, DE 19806\nUnited States",
"email": "legal@acmelogistics.com"
},
"services": {
"descriptionReference": "Exhibit A"
},
"paymentTerms": {
"feesReference": "Exhibit B",
"invoicePaymentDays": 30,
"currency": "USD",
"paymentMethod": "ACH transfer"
},
"termAndRenewal": {
"initialTermDurationValue": 1,
"initialTermDurationUnit": "year",
"autoRenew": true,
"renewalTermDurationValue": 1,
"renewalTermDurationUnit": "year",
"nonRenewalNoticeDays": 60
},
"confidentialityClausePresent": true,
"limitationOfLiability": {
"excludesIndirectDamages": true,
"vendorLiabilityCapDescription": "Vendor's total liability shall not exceed the total fees paid by Company to Vendor in the twelve (12) months preceding the claim."
},
"termination": {
"terminationForCauseNoticeDays": 30,
"curePeriodRequired": true
},
"governingLaw": "California",
"governingLawExcludesConflictOfLaws": true,
"entireAgreementClausePresent": true,
"amendmentRequirement": "in writing signed by both parties"
}Validation workflows then verify extracted values against expected schema rules. Confidence scoring identifies uncertain clauses that may require human review before synchronization with downstream systems such as CLM platforms, procurement systems, compliance repositories, or ERP environments.
Because LlamaParse preserves structural relationships during parsing, metadata remains contextually aligned rather than fragmented into disconnected text segments.
Best Practices for Production Contract Metadata Workflows
Successful implementation requires more than selecting a contract data extraction tool. Organizations must design workflows that balance automation, governance, validation, and adaptability.
Schema design should be treated as a foundational architectural activity. Clearly defining metadata categories, clause structures, extraction priorities, and validation requirements improves consistency across contract types and legal workflows.
Validation logic should be incorporated early in the workflow rather than treated as a downstream correction mechanism. Cross-field consistency checks, clause-level verification, confidence scoring, and normalization workflows help prevent unreliable metadata from entering operational systems.
Human-in-the-loop workflows remain essential for edge cases and high-risk agreements. Automation should reduce manual review effort while preserving legal oversight for ambiguous contractual language and governance-sensitive obligations.
Organizations should also plan for continuous evolution. Contract templates, legal terminology, jurisdictional requirements, and compliance frameworks change over time. Production-ready systems must adapt to new document structures without requiring constant engineering maintenance or brittle rule updates.
Governance and traceability should remain central architectural considerations throughout implementation. Metadata extraction systems must preserve source references, confidence metrics, review histories, and audit trails to maintain operational defensibility and compliance readiness.
These governance requirements increasingly align with broader enterprise automation initiatives focused on intelligent document processing and structured operational workflows.
Conclusion
Extract contract metadata workflows are becoming increasingly important as organizations modernize legal operations and contract lifecycle management processes. Contracts contain operationally critical information, but much of that data remains inaccessible when stored within static repositories and unstructured document archives.
Modern extraction systems combine machine learning, layout-aware parsing, semantic analysis, structured validation, and workflow orchestration to transform legal agreements into structured operational data. This enables organizations to automate renewal tracking, monitor contractual obligations, strengthen compliance oversight, improve enterprise search, and reduce manual review effort across legal and procurement operations.
LlamaParse supports this transformation by providing a platform that integrates intelligent document processing, structured parsing, schema-aligned extraction, and validation orchestration within a unified environment. Rather than requiring organizations to build custom extraction infrastructure entirely from the ground up, LlamaParse enables teams to configure production-ready metadata extraction workflows capable of adapting to real-world legal document variability.
Because LlamaParse combines layout awareness, semantic extraction, configurable workflows, confidence scoring, and integration-ready outputs, organizations can operationalize contract intelligence without maintaining brittle rule-based pipelines or isolated OCR systems. This allows legal, procurement, compliance, and finance teams to work from structured, reliable contract data instead of manually reviewing large document repositories.
Organizations already investing in initiatives such as enterprise OCR, financial document extraction, and intelligent document processing can extend the same structured processing principles into contract intelligence workflows.
To explore how LlamaParse can support extract contract metadata workflows within your organization, request a tailored demonstration aligned with your legal, compliance, and operational requirements.


