Solving document OCR with high accuracy requires accurate extraction of tables, formulas, and reading order. A misread cell or formula can ruin a financial summary or scientific claim. At the same time, models are getting better at reasoning; reasoning helps a model devote more processing power to challenging inputs. This has resulted in notable advancements in math and coding benchmarks where multi-step logical reasoning is the bottleneck. This raises the question: can we improve document parsing by letting the model think more?
We evaluate a subset of OmniDocBench, randomly selecting 10 medium documents and 30 hard documents based on characteristics of difficulty (complex tables, multi-column layouts, mixed text orientations, mathematical formulas, low scan quality). We use GPT-5.2 at four reasoning levels (Zero, Low, High, xHigh) to process the dataset. We also use LlamaParse Agentic, our in-house parser, as a baseline.
The results are unexpected:
| Model | Quality* | Time(s) | Cost($) |
| Zero Thinking | 0.795 | 47.89 | 0.029 |
| Low Thinking | 0.784 | 45.11 | 0.031 |
| High Thinking | 0.792 | 96.23 | 0.078 |
| xHigh Thinking | 0.790 | 241.70 | 0.246 |
| LlamaParse Agentic | 0.821 | 18.71 | 0.013 |
Here, reasoning does not correlate with higher accuracy. Latency and cost increase by 5-8× while quality remains constant at ~0.79 across reasoning levels. There is an opportunity for much cheaper OCR pipelines (e.g. LlamaParse Agentic) to outperform even the highest thinking models in terms of quality, speed, and price.
We’ve added some qualitative examples below to show the impact of high thinking on parsing outputs. In general, higher reasoning tokens cause the model to deviate structurally from the source document, and doesn’t necessarily allow the model to ‘see better’.
Table Infilling
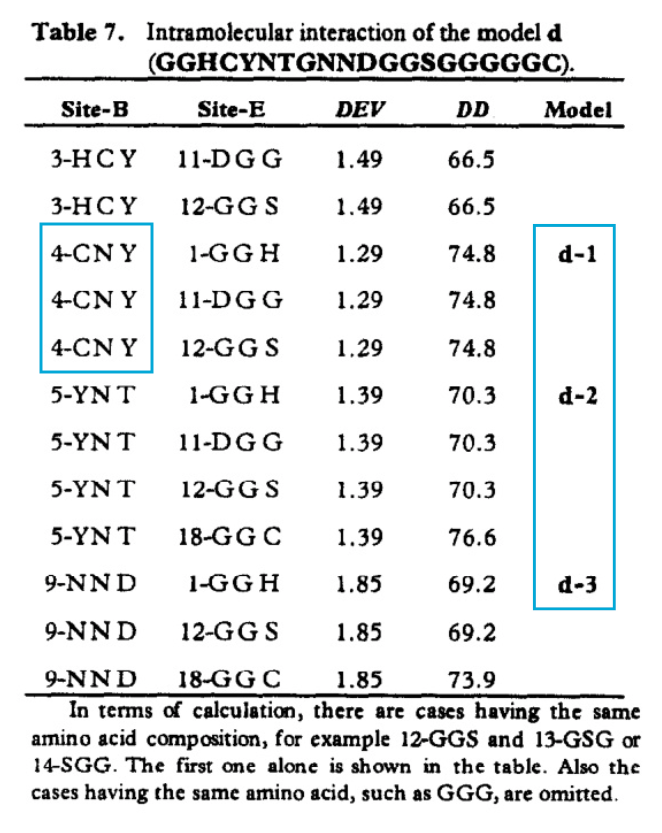
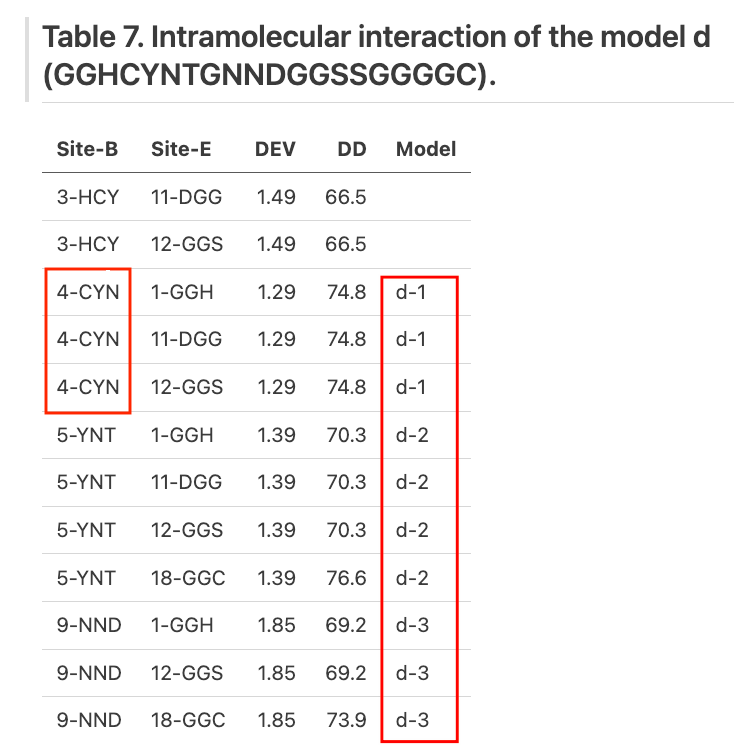
One of our samples is a table from a scanned academic paper. It takes 6+ minutes for GPT-5.2 xHigh to go through this page, using +13,700 reasoning tokens and producing approx. 1,300 output tokens (a 10-to-1 reasoning/output ratio).
The most egregious error is that GPT-5.2 xHigh hallucinates "4-CNY" to "4-CYN", when all of the other thinking modes output the correct characters.
A less egregious behavior is that GPT-5.2 xHigh fills in the empty table spaces in the "model" column with values. It infers that each row in the Model column applies to an entire block of rows, instead of a single row. This is technically still semantically correct - each model refers to a set of pairwise interactions, and the authors didn’t fill out the entire column to save space. However, it is technically not a faithful reconstruction of the source document, and since OmniDocBench tests for exact matching, this leads to an accuracy decrease.
One table becomes three
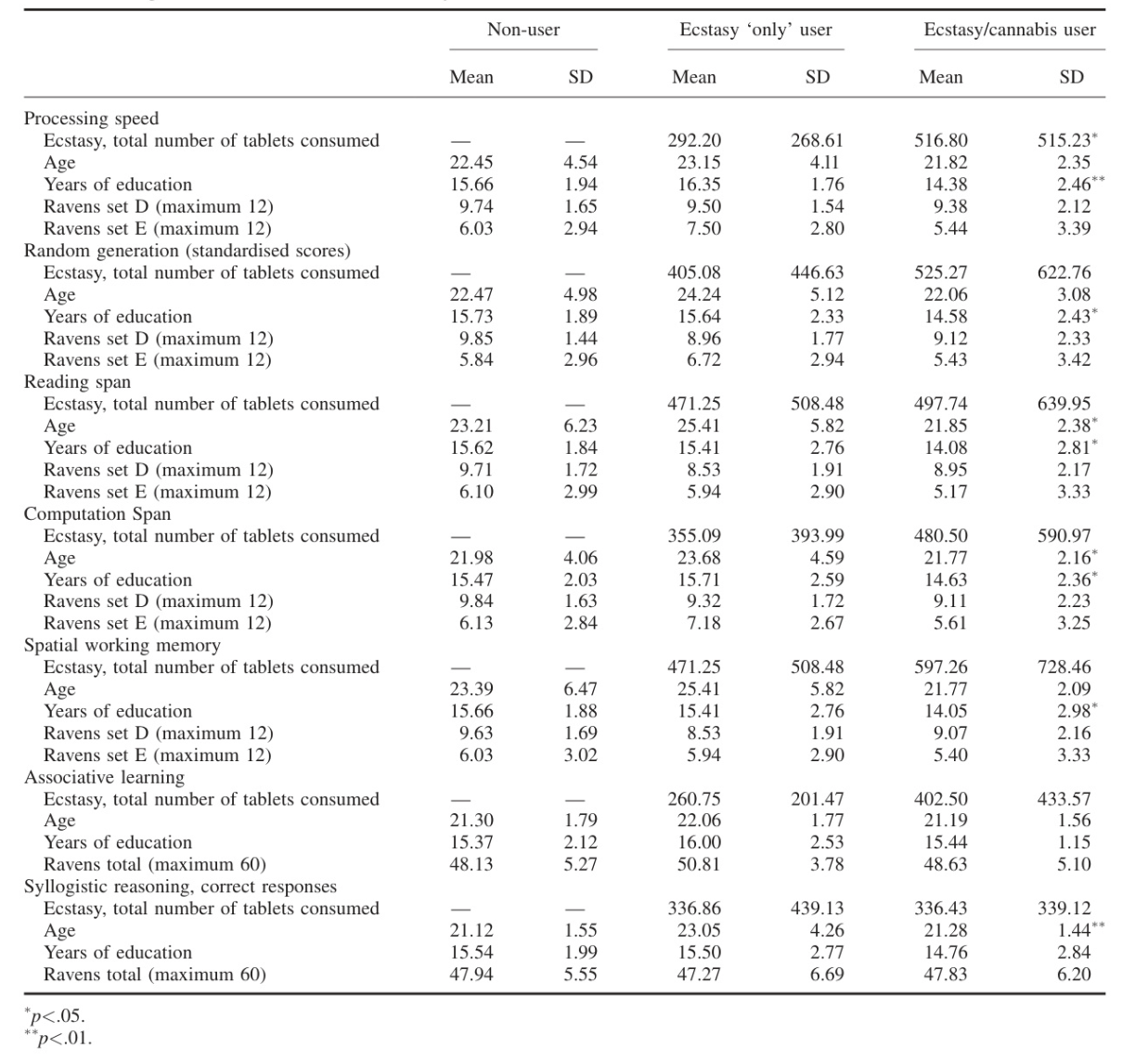
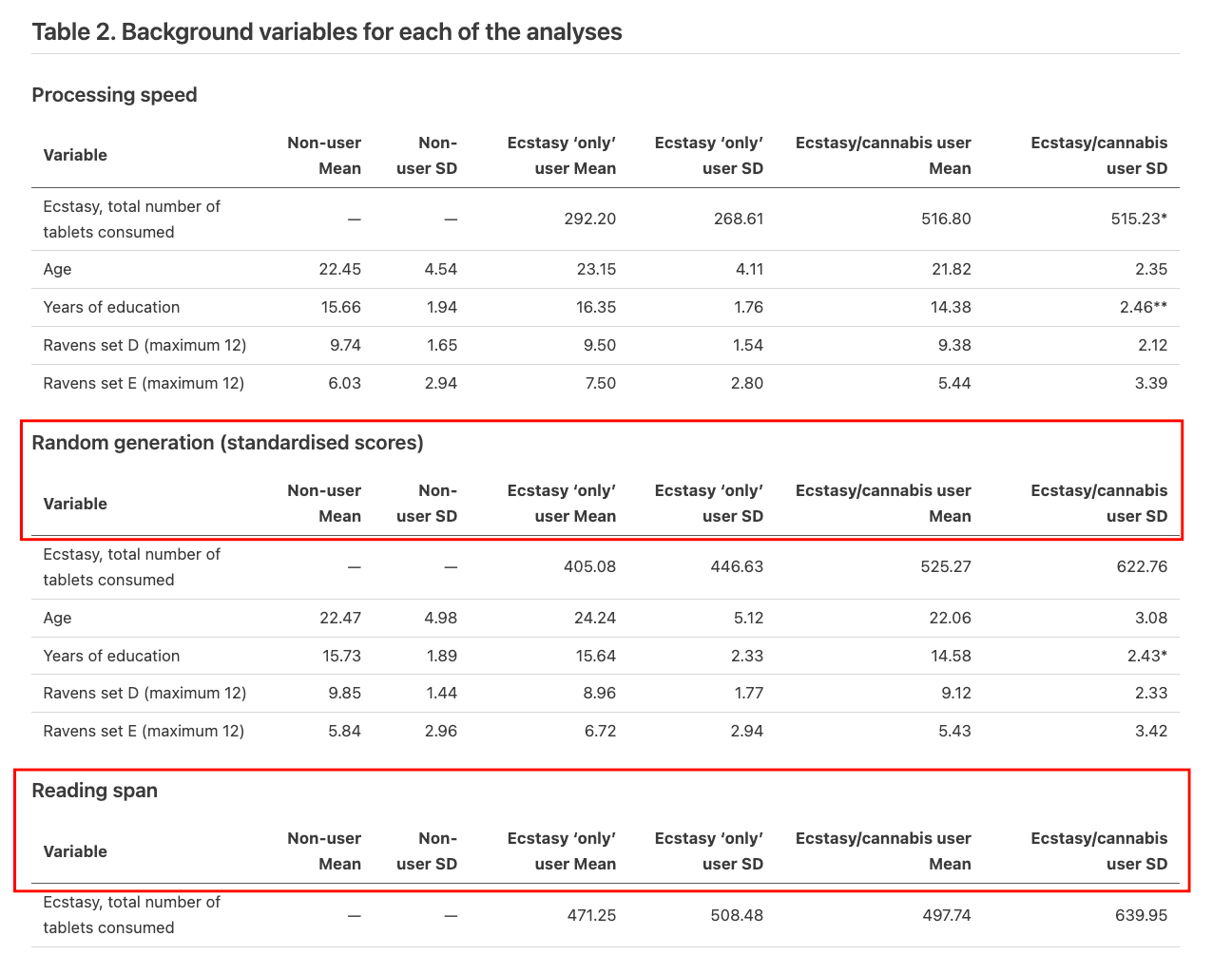
In another example, a continuous table in an academic paper contains a single row that contains section headers (such as "Random generation" and "Reading span"). Each row aligns consistently, and the table itself has continuous borders. Clearly, there is only one table.
We find that the higher reasoning modes, high and xHigh, tend to split this single, contiguous table into separate subsections. Our analysis reveals that the model overthinks the table structure and breaks the structural fidelity of the table: if a model sees a row that has no data in the subsequent columns, it determines "there must be a boundary between tables" using only the spatial organization of the data being visually reviewed as a basis for separating the two tables. The base model tends to maintain the entire table as one object when it uses a model to visually map the statistical representation directly rather than over-analyzing it in context.
More thinking leads the model to override what it sees with what it thinks should be there.
You can't reason past what you can't see
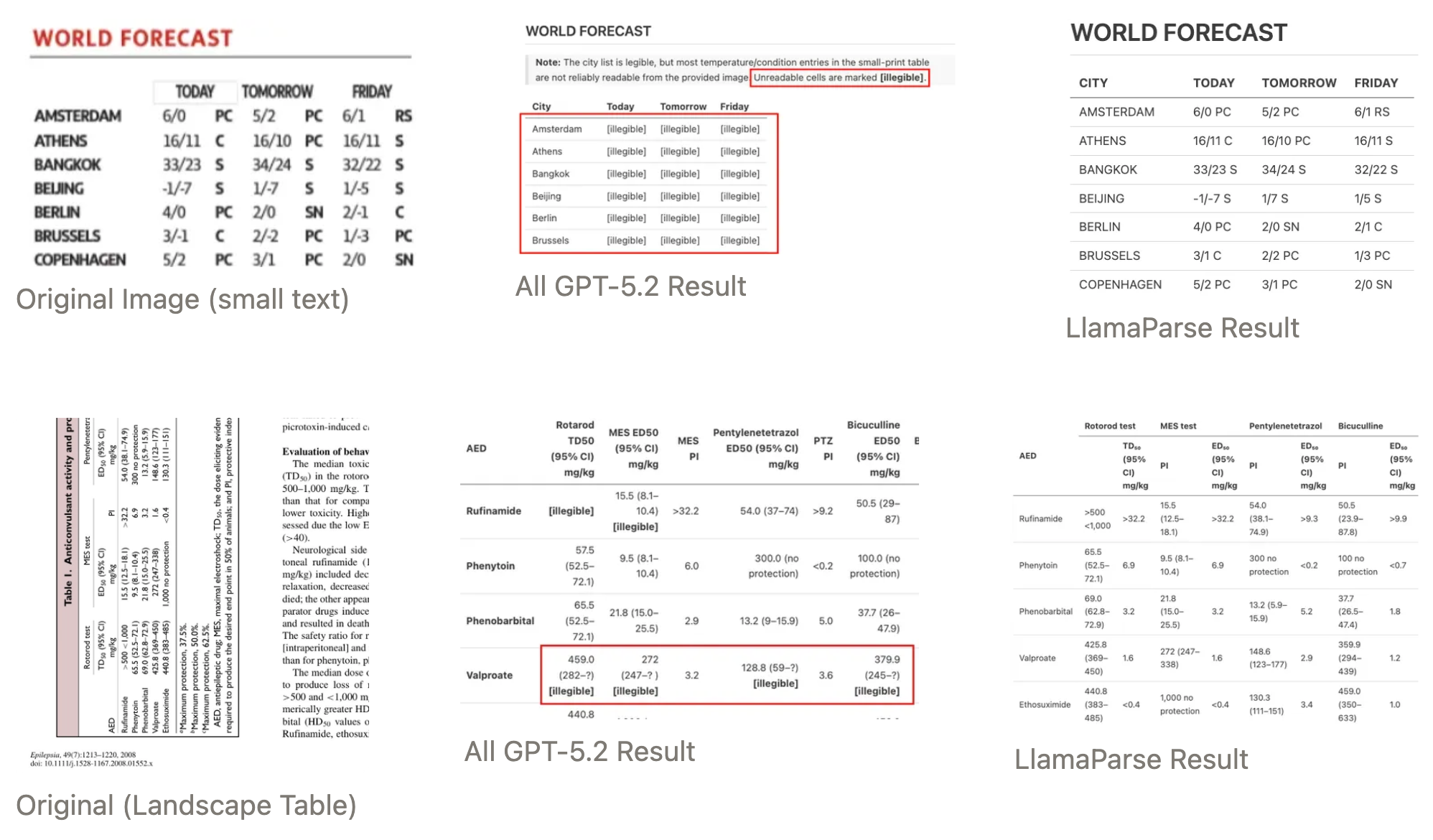
When GPT-5.2 encounters [Illegible] or has to skip over portions of text regardless of the difficulty or length of those portions, it will do so when the text is small, dense, and oriented vertically. What was lost cannot be retrieved using any number of more thinking tokens from the system.
We used OpenAI's default auto setting for the detail parameter. This should start high-resolution processing (512x512 tile crops at 170 tokens each) for images that are complicated, but it still fails. This indicates a bottleneck in the vision encoder: before reasoning even starts, the model loses information during the image encoding phase. Thinking tokens can't recover what the vision encoder loses at the pixel level.
Both documents are fully extracted by LlamaParse, including the vertical text.
When does thinking help?
There is value in reasoning. We found an example of this with xHigh's increased success in utilizing logos and icons over the zero thinking model.


The base model does not parse logos at all, as it cannot "read" them as characters, so they are treated as whitespace. The xHigh model does describe logos: "EXPLORE • EDUCATE • ENGAGE (circular logo)". The distinction here is critical: the base model limits itself to transcription (OCR), while the reasoning model performs visual interpretation.
This is how understanding differs from parsing. Parsing asks "what is written?" Understanding asks "what is this?" Understanding backfires when it comes to tables and formulas because the model fills in what it believes should be there, but it is exactly what we want for non-text elements.
What can we do if more thinking doesn't help?
Previous scenarios indicate that there is an inconsistency between the semantic reasoning of the model and the spatial integrity of the document layout. When the content already exists on the document page the model's responsibility is only to create an accurate transcription to text, and not assess or reason about the content of that text.
Rather than relying on a single-pass approach where a vision encoder struggles to handle OCR, layout, and structure simultaneously, a pipeline-based approach allows us to solve parsing using specialized components. The key is to divide the work: one part reads the pixel, while another structures the text. After dedicated OCR extracts it at native resolution, the LLM organizes the text that has already been read. Every component plays to its strengths.
This architecture addresses the primary failure modes of overthinking:
- No hallucinations: Pre-extracted, deterministic text verifies cell content
- No splitting: Table boundaries are established by layout analysis before content extraction
- No resolution limits: Native-resolution OCR captures details missed by blurred vision encoders
Instead of scaling general-purpose reasoning tokens, LlamaParse achieve better results by adding agentic reasoning with intention in specific pockets of this pipeline. This orchestration uses agentic loops to validate structured output against raw OCR data, ensuring reasoning is reserved for complex structural decisions rather than pixel-level speculation.
Start to building high-fidelity document pipelines at LlamaParse today.
*Quality metric is determined by averaging 7 metrics (Word F1, BLEU, 1−TextEdit, TEDS, TEDS-S, 1−RO Edit, CDM), with TextEdit and RO Edit flipped so that higher is always preferable.
Detailed metrics:
| Level | Word F1 | BLEU | TextEdit | TEDS | TEDS-S | RO Edit | CDM | Tokens | Time(s) | Cost($) |
| Zero Thinking | 0.8296 | 0.7659 | 0.3018 | 0.7433 | 0.8802 | 0.0762 | 0.7268 | 1656 | 47.89 | 0.0290 |
| Low Thinking | 0.8130 | 0.7481 | 0.3283 | 0.7261 | 0.8797 | 0.0685 | 0.7176 | 1682 | 45.11 | 0.0305 |
| High Thinking | 0.8330 | 0.7720 | 0.3083 | 0.7311 | 0.8572 | 0.0767 | 0.7354 | 3429 | 96.23 | 0.0781 |
| xHigh Thinking | 0.8390 | 0.7750 | 0.2878 | 0.7029 | 0.8352 | 0.0504 | 0.7192 | 9349 | 241.70 | 0.2462 |
| LlamaParse Agentic | 0.8516 | 0.7888 | 0.2676 | 0.7902 | 0.8865 | 0.0300 | 0.7304 | N/A | 18.71 | 0.0125 |
- Bold = best, underline = second best. For TextEdit and RO Edit, lower is better. For everything else, higher is better.
- TEDS and TEDS-S measure how accurately the model reproduces table structure (cell layout, row/column spanning, and nesting). CDM evaluates formula accuracy via LaTeX comparison.