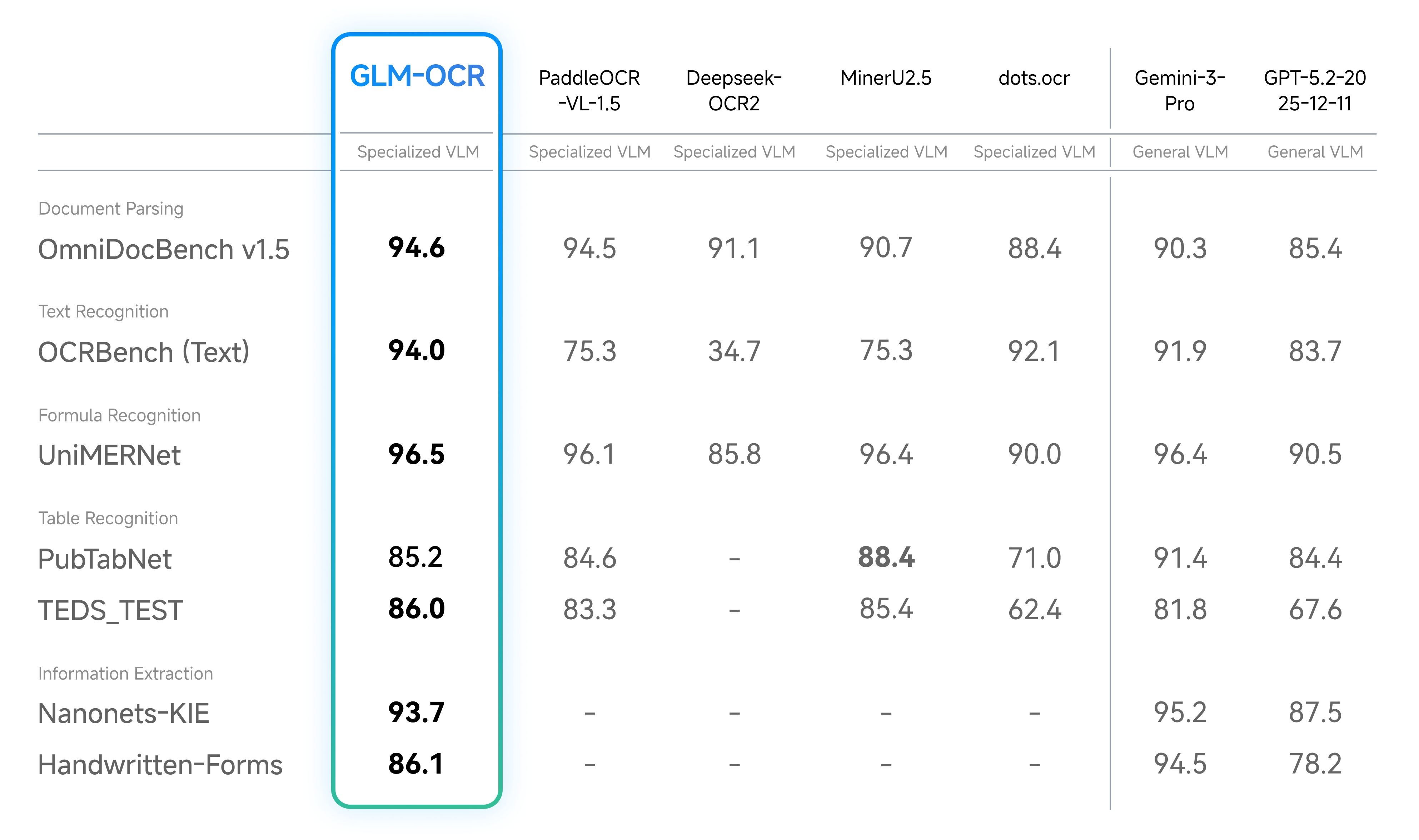
We’ve seen a whirlwind of advancements in document OCR VLMs in the past month, from Deepseek-OCR2 to PaddleOCR-VL-1.5 to GLM-OCR. The latest model, GLM-OCR, set a new SOTA benchmark on OmniDocBench v1.5 with 94.6% accuracy, beating not only OSS models but also recent frontier models like Gemini 3 Pro and GPT-5.2.
OmniDocBench has emerged as one of the default benchmarks for evaluating any model on document understanding. Besides the models above, it’s also used in the latest Gemini and Kimi 2.5 releases.
Yet document parsing is far from a solved problem. Even though the latest models like GLM-OCR are getting very high accuracy scores on OmniDocBench, there is a massive long tail of document edge cases where even the best visual understanding models still fail. The ‘unicorn’ document parsing benchmark metric should challenge the best models and push them to 100% parsing accuracy over any complex document type.
There are two issues with OmniDocBench:
- It is getting saturated and the dataset types are a bit too limited/easy
- It is too rigid in its evaluation metrics, penalizing innovation in much better, general parsers
To be clear, I think OmniDocBench has provided significant value as a document benchmark. Before its release, there really wasn’t a good parsing benchmark at all. Even though there has also been OlmOCR-Bench (which uses binary tests) and OCR-Bench v2, OmniDocBench remains as one of the only “reference” benchmarks for document understanding.
Quick Overview
OmniDocBench (CVPR 2025) is a benchmark published by Ouyang et al. at OpenDataLab back in 2025. Its document dataset spans nine different document sources, ranging from academic papers to textbooks to handwritten notes. Each document contains top-level annotations like layout bounding boxes and reading order, to fine-grained annotations on titles, text paragraphs, and tables. The original curation process has 981 samples, and v1.5 later expanded and adjusted the distribution.
Its evaluation pipeline consists of a set of continuous heuristics used to evaluate different elements. It uses Normalized Edit Distance for text, Tree-Edit-Distance-based similarity (TEDS) for tables, and Character Detection Matching (CDM) for formulas.
The overall score is computed as:
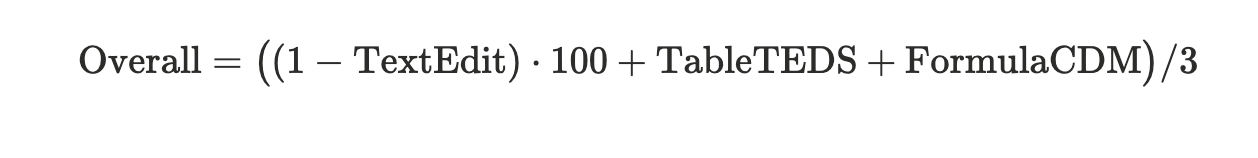
OmniDocBench is getting saturated
This is self-evident from the extremely high top-line scores from recent models. Both GLM-OCR and PaddleOCR-VL-1.5 have surpassed 94% in accuracy. For comparison, the latest SOTA result from frontier labs is Gemini 3 Pro at 90.3%. From a pure quantitative perspective, additional increases in OmniDocBench could reduce to “edge case fixing” and doesn’t represent “true” improvements in doc parsing accuracy.
The biggest reason for this is that the benchmark size is still small relative to the space of real-world documents. Even at 1355 pages, the benchmark covers 9 doc types and misses a lot more complex documents, particularly those relevant to specific domains. This includes complex financial presentations, market research reports, complex legal filings, insurance claims, and intake forms. The benchmark itself heavily weights towards data types like academic papers. It also heavily weights elements like text/tables/formulas, but it ignores other relevant elements like visuals, handwriting, and form fields.
OmniDocBench is too rigid in its evaluation metrics
OmniDocBench uses continuous metrics like BLEU and edit distance to measure similarity between parsed outputs and its ground-truth annotations. The issue with the benchmark evaluation methodology is it tends to punish small, harmless differences like punctuation, spacing, and line breaks. This is both due to the nature of continuous heuristic metrics, and also the fact that there is a “single fixed ground-truth”.
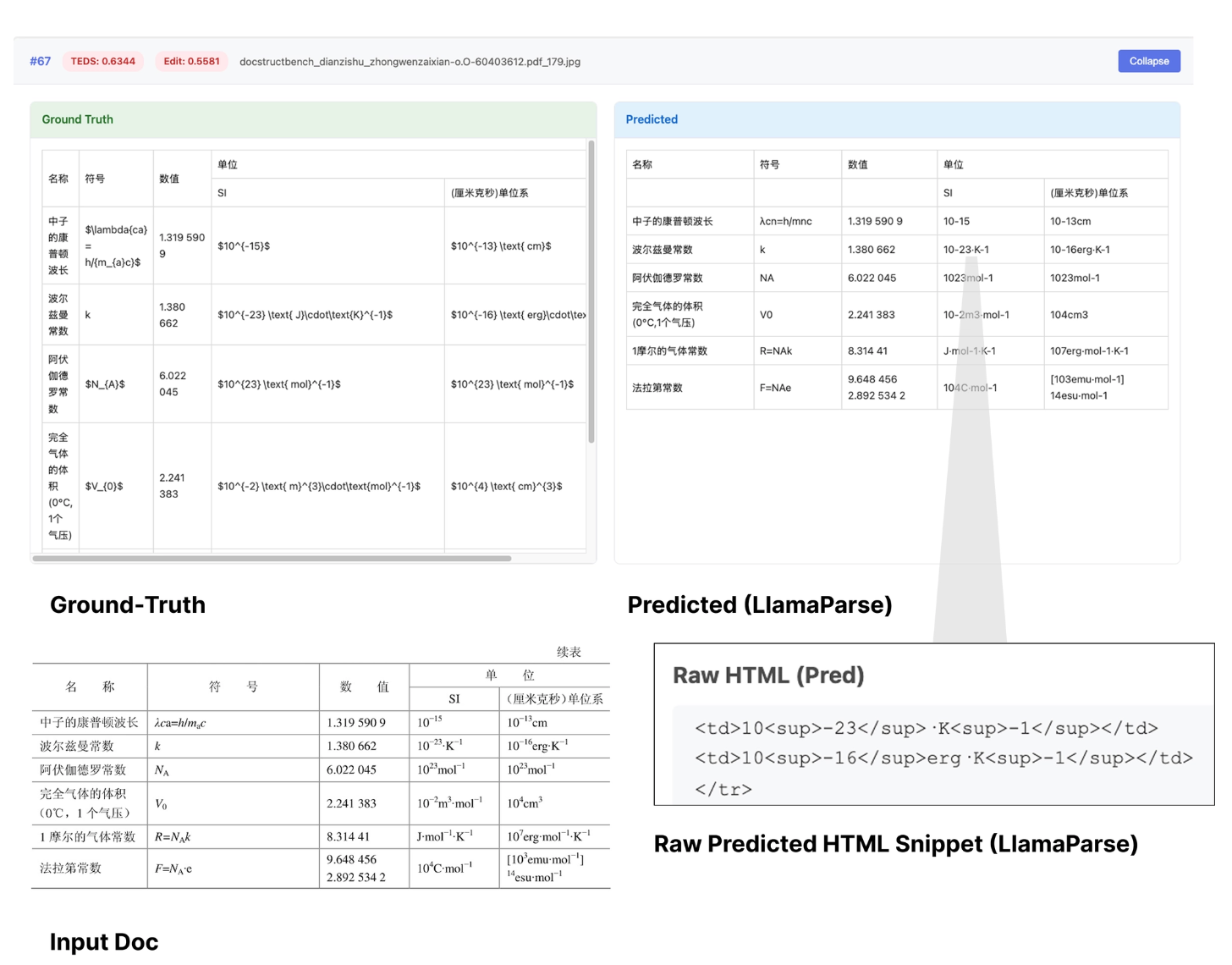
This is especially evident in tables. Exact table match failures can occur when the output is functionally equivalent - for instance, the parsed table representation is in HTML and not markdown, or the parsed table representation adds some stylistic tags that the annotations don’t have. Any failure in formatting directly penalizes edit distance metrics.
Even ignoring the metric itself, the document inputs can oftentimes have “ambiguous” ground-truth representations. For instance, outputting 3 bullet points could be as equally valid as outputting them without bullet points. When two tables are side by side and semantically related, the tables could be joined together or separated. Unfortunately within OmniDocBench there is only one single ground-truth representation. If the document parser outputs any semantically correct representation that’s different than the ground-truth, it is penalized.

Exact match evaluation is especially bad for document intelligence in the AI-native era. In a world where agents or humans are processing unstructured text tokens, what matters the most is that the representation is semantically correct, not that it has to conform to an exact formatting specification. AI agents don’t care if the parsed output is in HTML or markdown; they don’t care if the text is in bullet points or emdashes. They will care if the table rows/columns are misaligned, if diagrams and charts are interpreted incorrectly, and if content is dropped.
There are many parsers capable of handling much more complex documents in a semantically correct manner than the documents within the OmniDocBench dataset, but they are parsed in an incorrect manner.
What’s Next
We need a good document benchmark that is not only more complex and comprehensive, but also contains an evaluation methodology that rewards general semantic correctness beyond exact match.
This will lead to models that aren’t hillclimbing edge cases for exact text/table matching, but are encouraged to have better one-shot visual reasoning across any type of document.
This is a hard problem and we welcome discussion and feedback in this space. If you come across benchmarks or have ideas on document edge cases, we’d love to chat.
We’re also working on both fast/cheap and accurate parsing models that output semantically correct, easy-to-interpret markdown from even the most complex visual documents, without paying as much attention to exact matching. If you’re looking to scale up your OCR workload in production, come check out LlamaParse!