Hi everyone, Jerry here, CEO and co-founder of LlamaIndex.
It's been an incredible year since we first launched LlamaParse in public beta. As I reflect on this journey, I keep coming back to a fundamental truth I've witnessed since the early days of LlamaIndex as a developer framework, from hundreds of Discord messages to F500 enterprise conversations: the world runs on documents.
Walk into any company, and you'll find the same story. Critical business knowledge scattered across contracts buried in legal folders. Financial insights locked in dense research reports. Process documentation spread across wikis that haven't been updated in months. This is what 90% of enterprise data actually looks like: unstructured, disconnected, and largely inaccessible to the AI systems we're trying to build.
The Context Problem
Over the past two years at LlamaIndex, I've watched the generative AI landscape evolve from those early RAG demos with a single question box to sophisticated, multi-step, context-aware agents. We've been fortunate to be at the center of that transformation, from helping developers jumpstart RAG with five lines of code to powering millions of production workflows through our multi-agent framework.
From this vantage point, we found that the biggest challenge / biggest time-suck for AI engineers is figuring out how to feed reliable, high-quality context throughout the agentic workflow. When we analyzed the most popular use cases that our framework helped power, we found most of that context lives in large quantities of documents in standard file formats (.pdfs, .pptx, .docx).
There were no adequate solutions to help make files “AI-ready” for agents. Standard OCR fails on complex layouts, misses critical table relationships, and often produces text tokens with missing or hallucinated content. When your AI agent is making business-critical decisions based on faulty document understanding, trust evaporates quickly. It's like asking a pilot to fly without instruments, even the most sophisticated workflow becomes dangerous.
Why We Built LlamaParse
This is exactly why we built LlamaParse. Not as another document processing tool, but as the document processing and workflow platform for agents that automate knowledge work.
In just one year, we've grown from that initial public beta to a platform serving hundreds of thousands of users, with over 700% growth in self-serve revenue alone. But the numbers tell only part of the story.
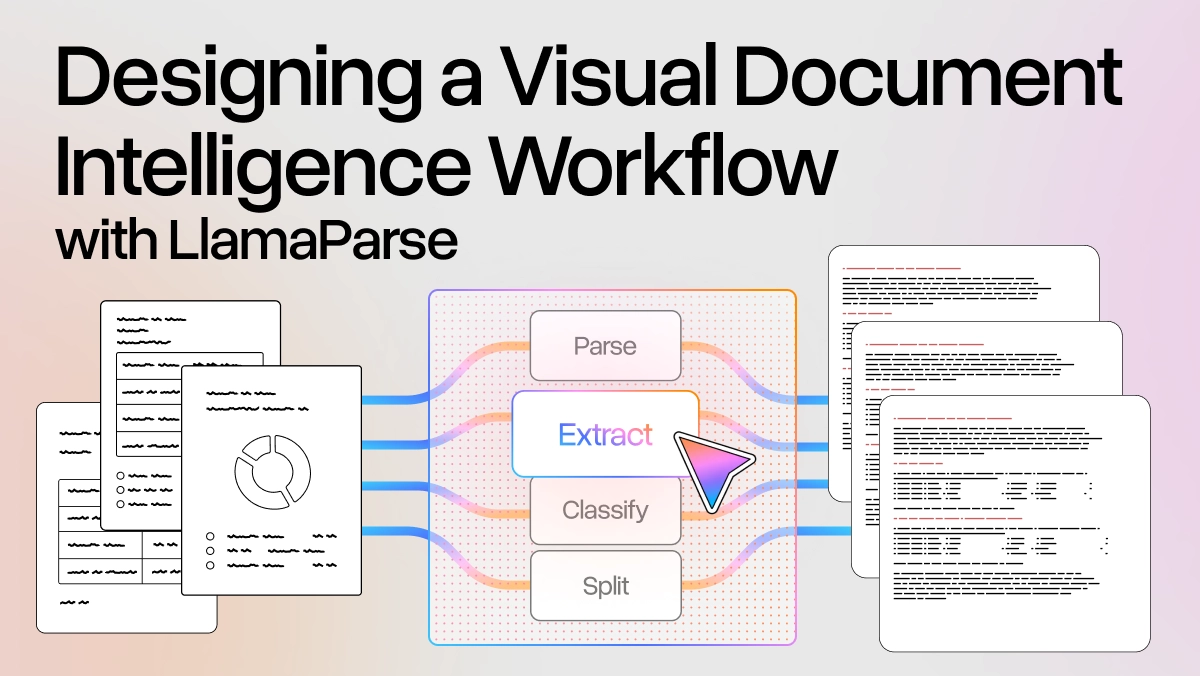
What excites me most is how teams are using LlamaParse as their document processing building blocks. You can parse even the most complex documents into well-formatted markdown. Extract specific information into normalized schemas. Index entire repositories and make them available to your AI agents. We've even added classification capabilities in beta to automate document detection.
The real magic happens when you combine these building blocks into end-to-end agentic workflows, whether you're building a deep research agent or automating critical business processes.
Our products are layout-aware, table-aware, and chart-aware, interpreting complex documents end-to-end. They stitch multi-page tables together, read and understand charts, handle mixed layouts, and deliver accuracy scores and citations you can actually trust. This isn't just better OCR. This is agentic document processing — reasoning over structure, interpreting fine details, and connecting insights across documents, not just extracting text.
Real Impact in the Real World
The applications we're seeing give me incredible optimism about where this technology is headed.
Take deep research agents. Companies like Cemex, Rakuten, and Carlyle are building research copilots over their entire enterprise knowledge bases. At Carlyle, their research agent can access data rooms filled with private financial documents: extracting and surfacing insights that once took teams weeks to compile. That's not just efficiency; that's unlocking entirely new capabilities.
For automated workflows, LlamaParse enables high-accuracy processes like invoice parsing and Excel transformation, codifying business workflows into standardized, governed pipelines, always with appropriate human oversight.
From automating invoice processing to unlocking enterprise search to building sophisticated research copilots , the possibilities really do scale with your ambition.
The Foundation for What's Next
With LlamaParse as your data foundation and LlamaIndex Workflows as the agentic workflow layer, we're becoming the single place teams go to reimagine document workflows and build context-aware document agents.
But honestly, this is just the start. Every conversation I have with enterprise teams reveals new use cases, new challenges, and new opportunities to push the boundaries of what's possible when you give AI agents access to high-quality document context.
We're building the infrastructure for a future where AI agents can reason over your entire enterprise knowledge base with the same confidence and reliability that humans do — maybe better.
Join Us
Whether you've been following our journey from the early LlamaIndex days or you're just discovering what we're building, I invite you to take part! Sign up for LlamaParse, get 10,000 free credits to start experimenting, and share your feedback in our community Discord.
We’re going all in on documents and automating everything you can do over documents. Come join us and millions of other developers to help automate the exabytes++ of unstructured, digitalized/manual paperwork that exists in the world today.
—Jerry