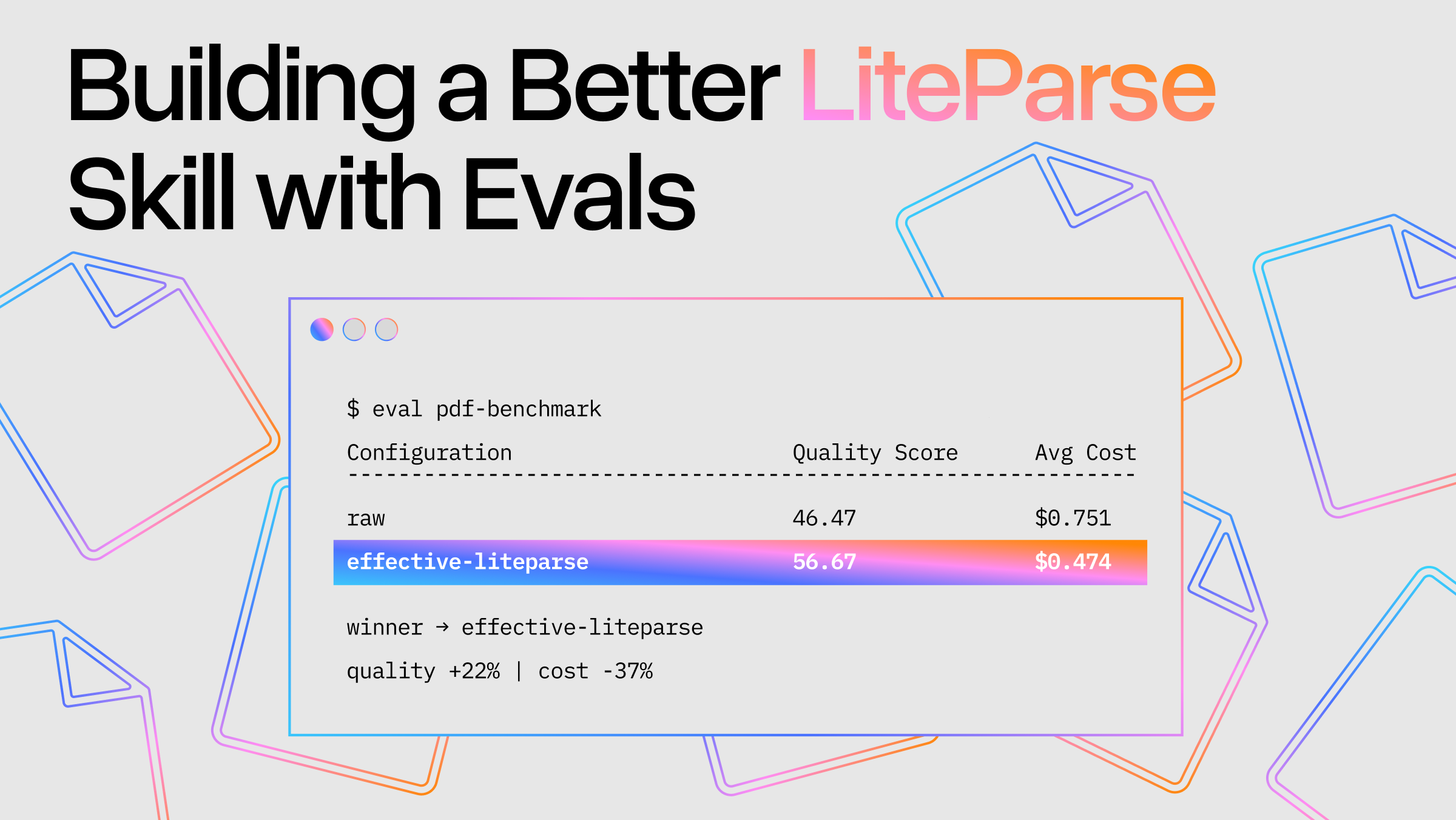
When we first released LiteParse, we launched it with the goal of being the PDF extractor that runs everywhere. LiteParse extracts structured text from PDFs and office documents without LLMs. Documents are processed, and text is projected according to the layout in the document. The LLM-free approach was already lightweight, but running only as a Node/Typescript package meant that we were limited by latency and distribution issues that came with that approach.
Today, LiteParse is now available as a native Rust, Node, Python, and WASM package. We rewrote the entire project using rust and adapted it to run anywhere. Now you can launch and install LiteParse anywhere: rust, python, node, in the browser, and even on edge runtimes.
bash
# Node Library + CLI
npm i @llamaindex/liteparse
# Python Library + CLI
pip install liteparse
# Rust Library + CLI
cargo install liteparse
# WASM Library
npm i @llamaindex/liteparse-wasmOne Codebase, Run Anywhere
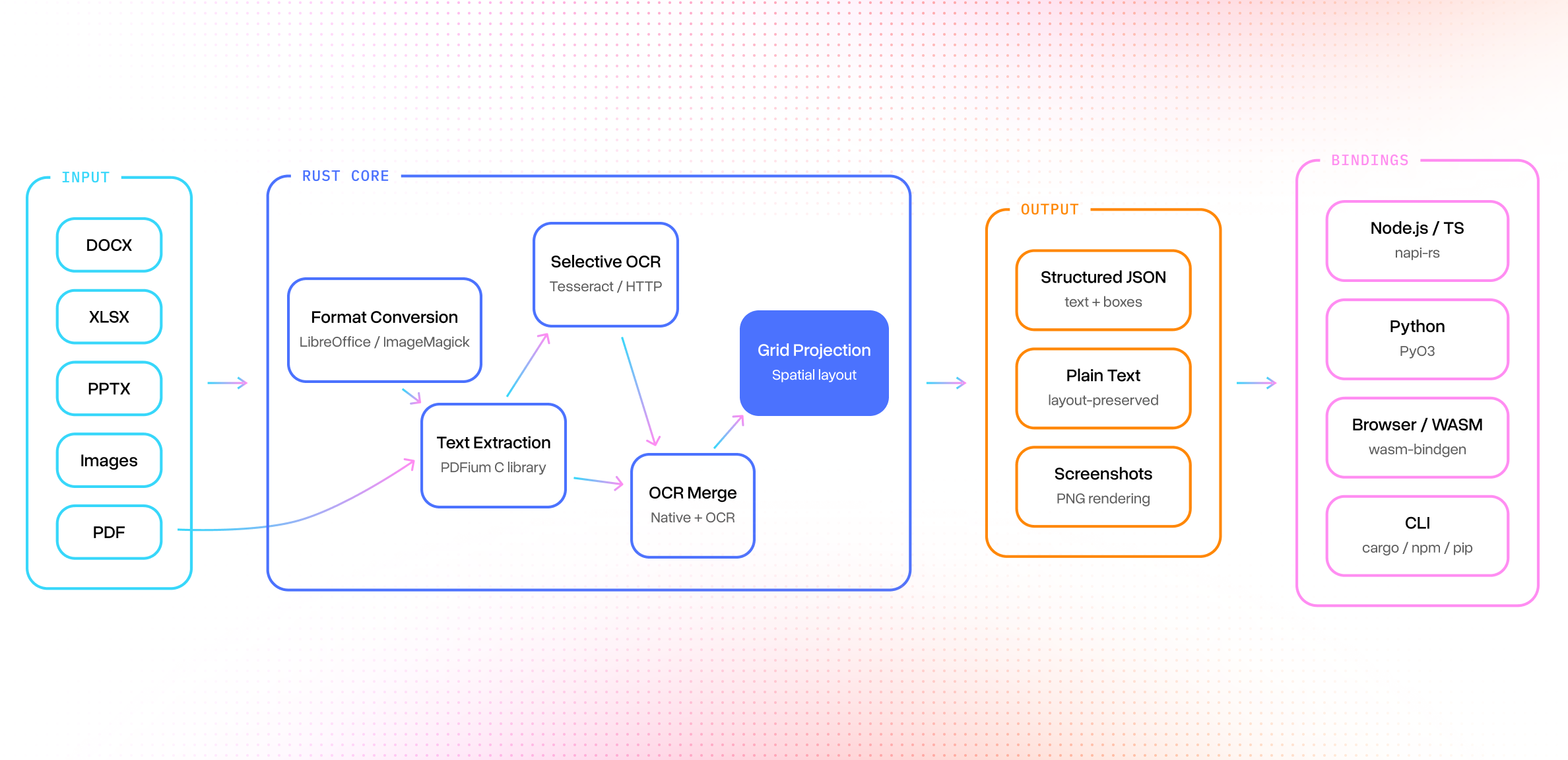
One of the first requests we got after releasing LiteParse V1.0 was requests for other languages. We added a Python package that just wrapped the CLI, and could do the same for other languages, but this wasn’t going to remove the hard dependency on a Node install.
We explored compiling the Typescript code into a binary, but the complex system dependencies made this impossible.
Instead, we picked Rust, and got to work. Now, changes to the rust core propagate easily to every language binding, and we get the performance and safety that rust provides.
Performance
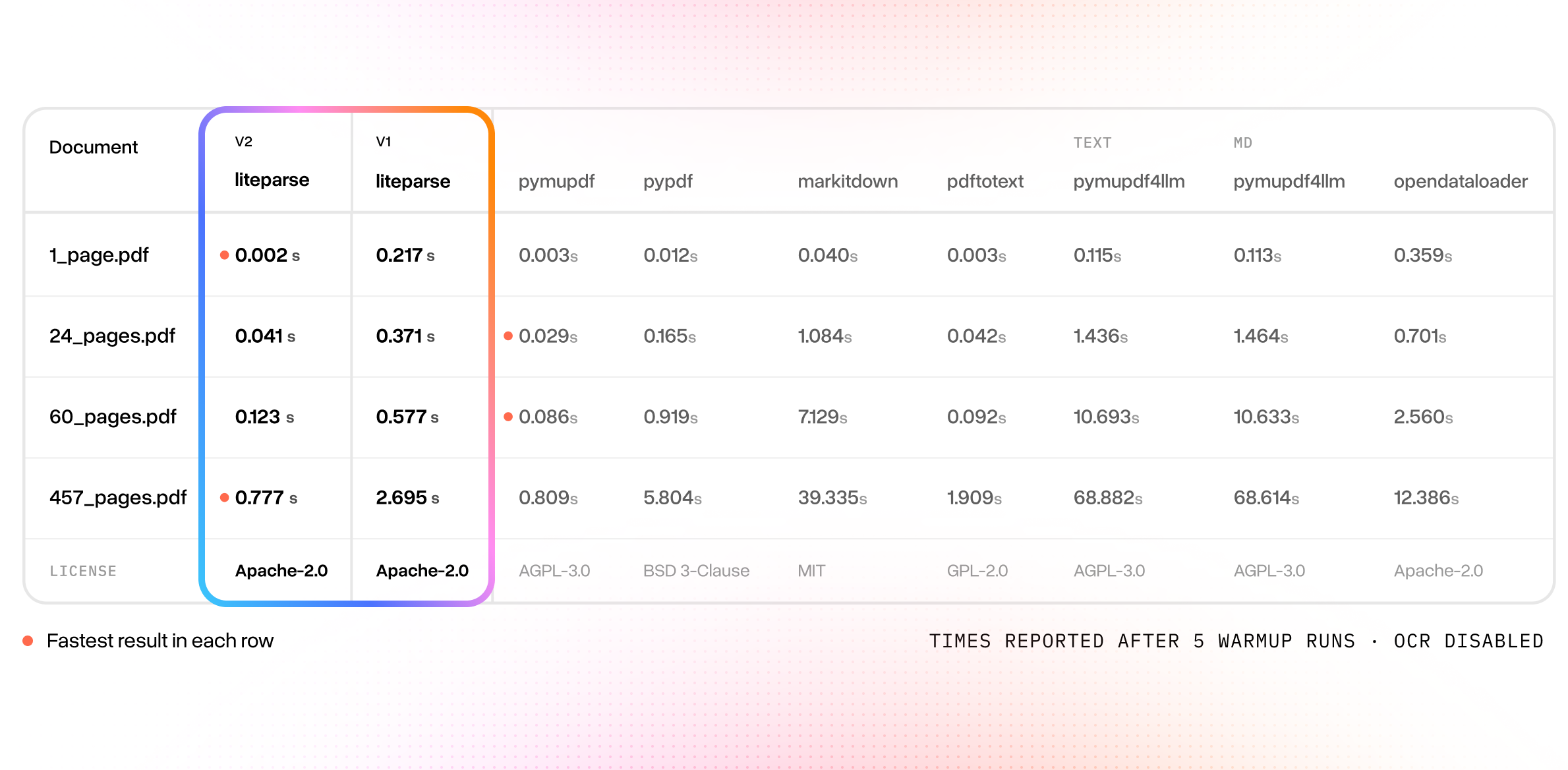
Naturally with rust, performance increased quite a bit. Previously the runtime was dominated by spinning up a node process, so small docs see a 5-100x speedup. For larger docs, we observed around a 3x speedup.
Comparing to other PDF parsing utilities, we are blazing fast on most documents, with just 0.777s for a 457 page 100MB document. The Rust implementation uses a custom fork and build of PDFium, and is compiled against a build of tesseract-rs as the default OCR implementation. Together, we were able to squeeze out every drop of performance.
If you are running real-time agents and applications that need to read docs fast, LiteParse is the tool for it.
Making LiteParse Truly Portable
For us, running in rust, node, or python wasn’t enough. We wanted full browser and edge support. Community efforts from Simon Willison showed that it was possible to run LiteParse in the browser today, but you needed to stub out a lot of functions using Vite. We took that work and even made it the official path to browser support in our docs.
However with Rust, we can own more of the build pipeline. We created a WASM target for liteparse and were able to create a @llamaindex/liteparse-wasm package that could run in both the browser and edge runtimes. In fact, you can open this webpage and try out the WASM build of LiteParse for yourself. All parsing running locally in your browser!
To accomplish this, we still had to stub out system dependencies. This means the WASM version only parses file bytes directly, and OCR is instead provided through a callback that is passed in (i.e. calling tesseract-js) rather than being a built-in default.
Try it Today!
As we’ve emphasized, LiteParse runs everywhere and v2.0 is available now:
bash
# Node Library + CLI
npm i @llamaindex/liteparse
# Python Library + CLI
pip install liteparse
# Rust Library + CLI
cargo install liteparse
# WASM Library
npm i @llamaindex/liteparse-wasmOr, use it with your favourite coding agent directly as a skill:
bash
# Claude Code, Codex, OpenCode, etc.
npx skills add run-llama/llamaparse-agent-skills --skill liteparse
# Pi Coding Agent Extension
pi install npm:@llamaindex/liteparse-pi-extension@latestFollow these links for docs and details on source code: