

We’re coming to believe that the combination of a command-line agent like Claude Code or Gemini CLI with the extensive tooling already present in a Unix-like file system is sufficient to complete a wide variety of tasks at surprisingly high fidelity. We wanted to test that theory.
Part of our motivation is that we recently released SemTools, a toolkit for parsing and semantic search in the CLI. SemTools can be provided to command-line agents, giving them even more tools to parse complex documents and semantically search them with fuzzy semantic keyword search.
What we wanted to test was: is that combination of Unix-like tools like grep , find , and semantic search all you need? To test that theory, we built an informal benchmark to test the limits of coding agents for document search to try and answer that question.
What does SemTools do?
SemTools provides two main tools:
-
parse- a CLI tool that calls LlamaParse to parse complex formats into markdown. This way, you can grep and search file formats that were previously unsearchable. -
search- another CLI tool that uses static embeddings to embed documents on the fly and then performs a semantic search. Due to the nature of static embeddings, you can think of this as a fuzzy semantic keyword search. Specifically, it uses the model2vec model from MinishLab, minishlab/potion-multilingual-128M.
By providing these two tools to agents like Claude and Gemini, you can seriously upgrade their capability to explore the filesystem and answer questions about your documents, turning them into a full-fledged knowledge worker.
The Benchmark
The Dataset
To test the impacts of giving agents access to SemTools, we assembled a dataset of 1000 papers from ArXiv to test claude-code for document search. For this experiment, we wanted to focus solely on testing the search tool, so we downloaded the HTML versions of the papers and converted them to text.
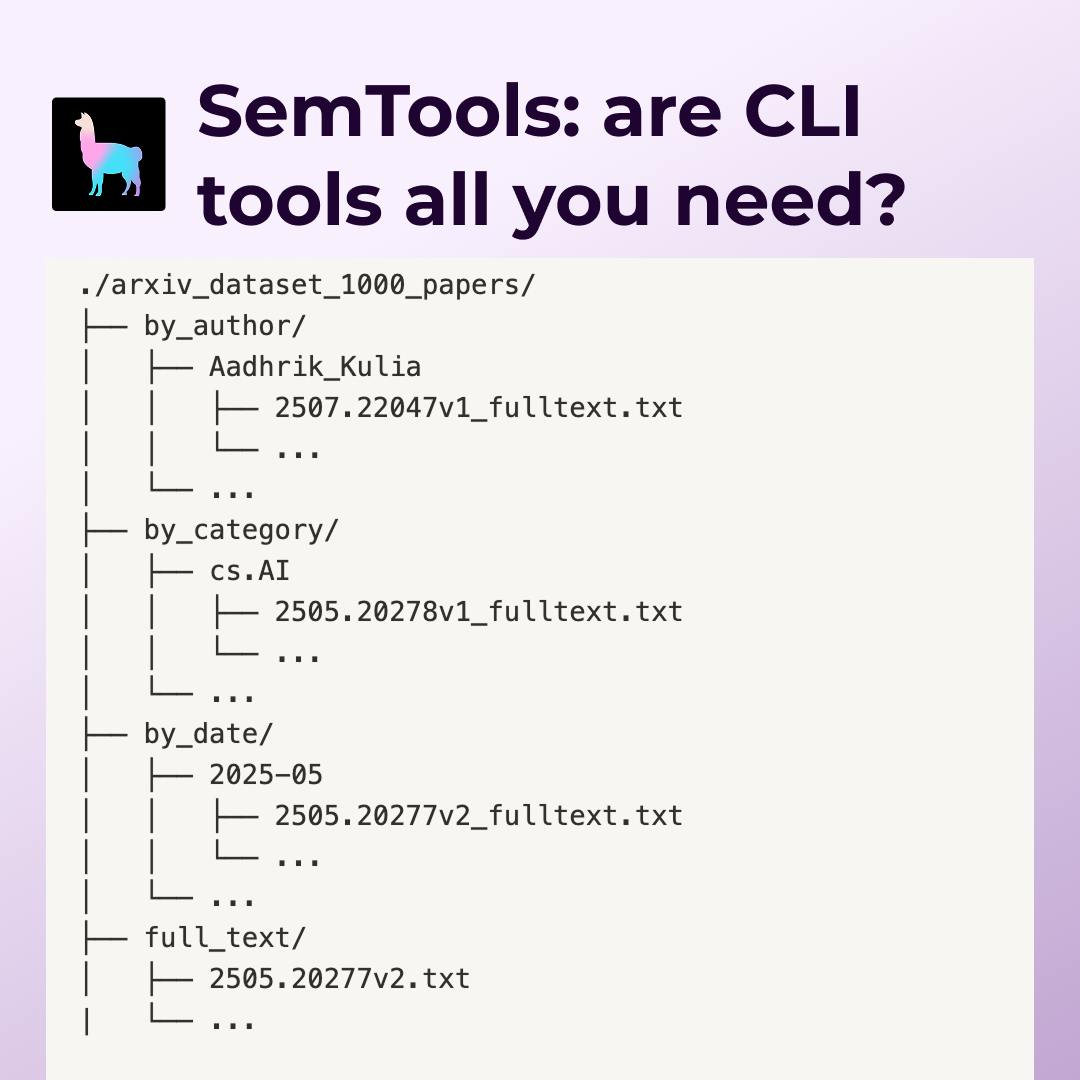
Then, we organized the papers into a directory structure composed of the full text, and other directories that symlink to the full text but are organized in different ways. A sample of the directory structure is shown below:
text
./arxiv_dataset_1000_papers/
├── by_author/
│ ├── Aadhrik_Kulia
│ │ ├── 2507.22047v1_fulltext.txt
│ │ └── ...
│ └── ...
├── by_category/
│ ├── cs.AI
│ │ ├── 2505.20278v1_fulltext.txt
│ │ └── ...
│ └── ...
├── by_date/
│ ├── 2025-05
│ │ ├── 2505.20277v2_fulltext.txt
│ │ └── ...
│ └── ...
├── full_text/
│ ├── 2505.20277v2.txt
| └── ...The full dataset is available to download from cloud storage, and the script that generated the dataset is available in the repo.
To configure Claude with appropriate background information, we created two CLAUDE.md files: both describe the dataset, while the second one also describes the search tool and how to use it. You can find both config files in the repo.
The Questions
With a dataset built and our agent configured, we just needed to design questions to ask. To do this, we developed five categories of questions, each with five questions:
-
search and filter-- questions that test the ability of the agent to search and filter the dataset -
cross reference and relationships-- questions that test the ability of the agent to cross reference and find relationships between papers -
temporal analysis-- questions that test the ability of the agent to analyze information over time from the dataset
You can find the full list of questions in the repo.
Evaluating the Results
With such a large dataset, and the open-ended nature of the questions, fully validating responses is a challenge. Instead, we took a vibes-based approach to evaluating the results: purely asking Claude Code to check if the response contains inaccurate information by investigating the direct papers/authors the response mentions, as well as checking ourselves.
The Actual Results
Below, we detail the accuracy and key differences between the with search and without search approaches. You can find the full answer traces from Claude Code in the repo.
Search and Filter
Here, both with search and without search approaches are able to find accurate information. Token costs are mostly comparable, but the key difference we noticed was that the responses with search were more detailed and contained more information. without search answers tended to peek less into the dataset, and therefore returned less information.
e.g. For the query Find papers discussing 'attention mechanisms' , the with search approach realized that the semantic fuzzy-search abilities were the right tool for the job. In without search , the agent had to rely entirely on calling grep , which is limited by the agents ability to generate synonyms. There it didn’t even try very hard, looking for ‘attention mechanism’ directly.
Cross Reference and Relationships
With more complex questions, we continue to see the same pattern. with search answers are more detailed and contain more information, while without search answers tend to peek less into the dataset and therefore return less information. Answers appear to be accurate in both cases.
e.g. Two interesting questions here were Which authors work on both 'transformers' and 'graph neural networks'? and Find exact co-author relationships for papers containing 'meta-learning' . In both cases, without search answers needed to use the Task() tool in Claude-Code to perform extensive research. This created a lot of token usage, tool calls, and latency. with search on the other hand, the agent was able to quickly find the papers discussing these topics and pulling the authors out for analysis.
Temporal Analysis
This class of questions is arguably pretty difficult even with good semantic search. However again, we see a similar pattern emerge as before: with search answers are more detailed and contain more information, while without search answers are less detailed.
Interestingly in more than a few cases, the agent tried to write python code to do basic NLP analysis to answer these questions, which was very creative.
e.g. The question Find authors who shifted research focus between months, if any caused the agent in both cases to analyze individual words, looking for topics and how they changed across months for authors that had multiple works between months.
Learnings
One key learning for us was about runtime -- With 1000 files and 4 million lines of text, running search on the full dataset is slower than we would like. We are actively working on improving this by incorporating persistent embeddings into the search tool and broad-based document-level retrieval. Users should be able to pull in a relevant "working set" of documents and then use search to find relevant information using fine-grained embeddings.
Our other learning was that CLI access is incredibly powerful relative to the effort involved in creating it, largely due to the benefit of the huge amount of tooling already provided by Unix. The amount of effort to set up agent tools to do the same thing that the CLI already provides would be large. Being able to peek into files, grep, search, etc, is much faster than building your own RAG.
Our takeaway: yes.
Overall, giving an agent access to the CLI proves to be a powerful baseline for document search and RAG. Agents are able to effectively use tools like grep to create synonyms and search for specific patterns in the text. When given access to SemTools, agents are able to find even more detailed and relevant information! Given the power and flexibility of this approach, we think it can often be all you need to accomplish your tasks.
Have you tried using SemTools? What are your thoughts? Let us know, and get involved in the project on GitHub!


