Native MCP search over the LlamaIndex documentation is now shipping today! Combined with recent changes to how we host and unify documentation, this means your coding agent or agentic workflow has direct access to search tools over ALL documentation: https://developers.llamaindex.ai/mcp
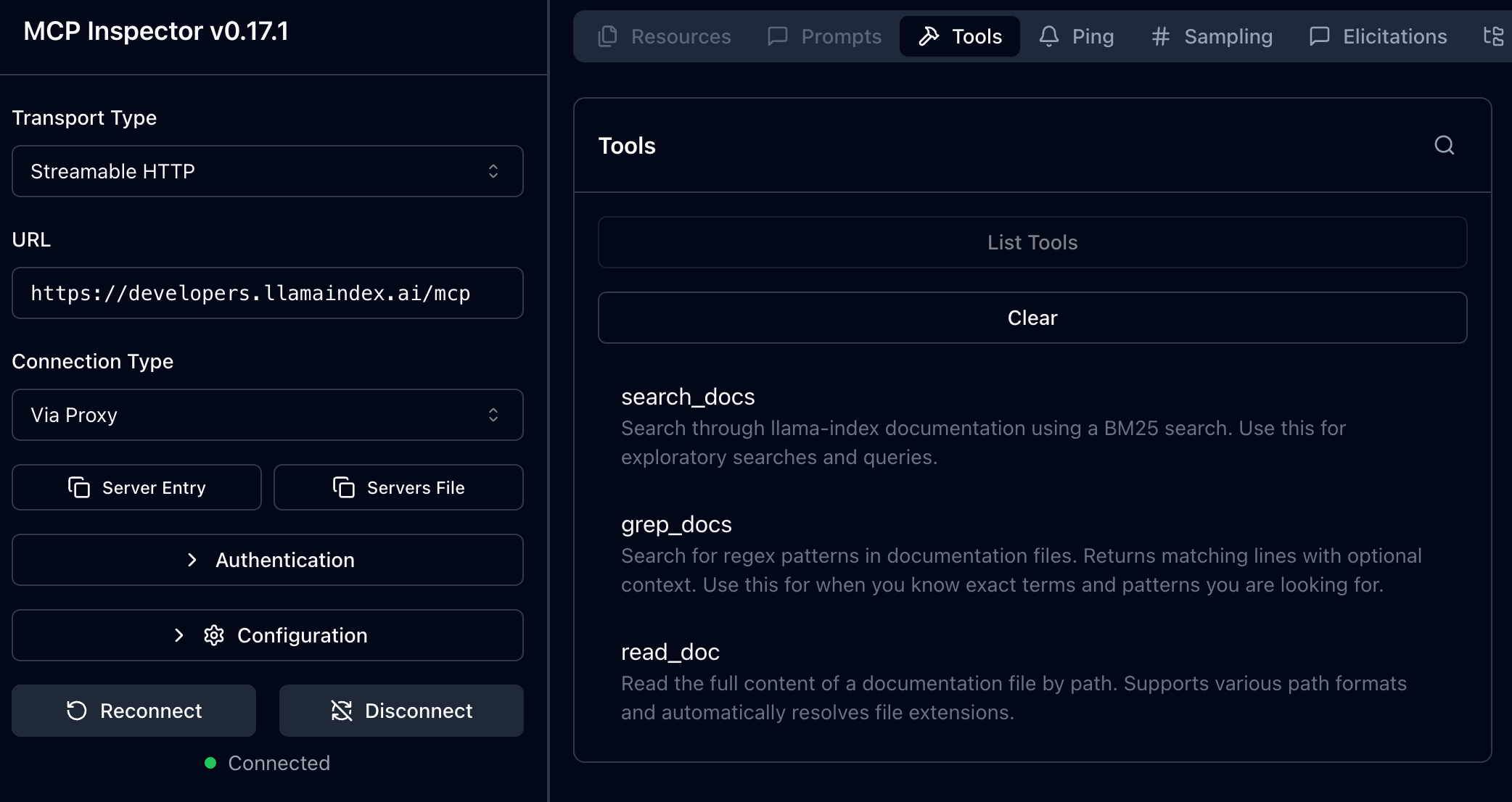
This change exposes three tools:
-
search_docs— a basic lexical search using BM25 -
grep_docs— exact search using regex -
read_doc— provides an interface to read the entire contents of any given page path
We believe all documentation sites should be shipping with some kind of native search available to LLMs and agents. Below, we detail how exactly this was implemented and how you can use it.
“How can I use LlamaIndex docs MCP in my work?”
MCP is basically a universal tool adaptor these days. You can search the LlamaIndex documentation using MCP with just about anything. Here’s a few examples.
LlamaIndex Agents
To use with LlamaIndex, you can simply install install the needed packages and create an agent using the tools from the MCP endpoint.
python
% pip install llama-index llama-index-tools-mcp
from llama_index.core.agent import FunctionAgent, ToolCall, ToolCallResult
from llama_index.llms.openai import OpenAI
from llama_index.tools.mcp import McpToolSpec, BasicMCPClient
async def main():
client = BasicMCPClient("https://developers.llamaindex.ai/mcp")
tool_spec = McpToolSpec(client=client)
tools = await tool_spec.to_tool_list_async()
agent = FunctionAgent(
llm=OpenAI(model="gpt-4.1", api_key="sk-..."),
tools=tools,
system_prompt="You are a helpful assistant that has access to tools to search the LlamaIndex documentation."
)
while True:
query = input("Query: ")
handler = agent.run(query)
async for ev in handler.stream_events():
if isinstance(ev, ToolCall):
print(f"Calling tool {ev.tool_name} with input {ev.tool_kwargs}")
if isinstance(ev, ToolCallResult):
print(f"Tool {ev.tool_name} returned {ev.tool_output}")
resp = await handler
print("")
print(resp)
print("=================")
if __name__ == "__main__":
import asyncio
asyncio.run(main())Claude Code
Adding to Claude Code is a single command:
python
claude mcp add --transport http llama_index_docs https://developers.llamaindex.ai/mcpFrom there, you can use Claude Code and it will retrieve information from the docs as needed.
Anything Else!
Most platforms/frameworks/etc. these days will have some kind of MCP support. Whether its some kind of JSON you configure locally, a special class you import in a framework, or elsewhere, we encourage users to use this docs MCP server anywhere they work.
“How do the MCP tools actually work?”
To start with, our documentation is a dynamically generated Astro and Starlight website, built from docs across many repositories. This is hosted and deployed onto Vercel.
Conveniently, Vercel provides a nice createMCPHandler function for automatically creating MCP endpoints from Vercel functions. This was a great place to start, and from there, we could focus on the actual tool implementations without worrying about specifics around MCP.
As for what tools to provide, we chose search , grep and read tools, as they would align well with LLM agents, especially coding agents like Claude-Code, that are used to these operations.
For the actual tool implementations, we wanted to re-use as much as possible from what was already bundled in the documentation and deployed.
read_doc
Since URLs can come in two forms (either relative/linked from other markdown files) or as URLs/paths, we implemented code to normalize these paths. From there, it was simply a matter of using the normalized path to lookup the docs file and returning its content.
grep_docs
This function was a natural extension of read_doc . Normalize the path, find the doc, and then apply a regex. Some nice utility options like providing context lines and case sensitivity were easy to implement beyond that.
search_docs
This was the most challenging function to implement. Initially, we thought we could hook into the search index from PageFind that the documentation ships with. And it worked! Or at least, it worked locally. But deployed on Vercel, the index files we needed to load from were missing, and despite some painful debugging we couldn’t track them down.
From here, it was back to the drawing board. To keep keep this extremely lightweight, we ended up going with a BM25 search. While BM25 is typically worse in benchmarks compared to vector search, we’ve also seen LLMs and agents excel in using lexical tools like these and crafting queries that take advantage of the underlying search algorithm.
The BM25 index is statically built at build time. We used the natural package for tokenization and stemming (i.e. for splitting text into words and consolidating duplicates like “like” and “likes”). With our docs split into words, we then build an inverted index that maps tokens to pages they appear in, to efficiently calculate the BM25 scoring method.
At runtime, this index is loaded, searches can run, and the index help can return relevant documentation for a given query. While this loses some accuracy compared to vector search, it was easy enough to do and very lightweight to maintain.
“Wait, I have feedback on the MCP tools!”
Great! We want to hear it! There are a ton of features we can add to this given how flexible the implementation is, and we really want to hear from users how useful they find this feature and what it might be missing.
You can reach out to us on several platforms, come find us!
- X: https://x.com/llama_index
- LinkedIn: https://www.linkedin.com/company/llamaindex/
- Discord: https://discord.gg/dGcwcsnxhU
- Youtube: https://www.youtube.com/@LlamaIndex