LLMs rely on static, outdated training data that does not capture current events or evolving knowledge. To overcome this limitation, AI models need access to up-to-date information.
Bright Data meets that need by providing an AI-ready web data infrastructure for collecting and analyzing web data. Now natively integrated with LlamaIndex via LlamaHub, Bright Data covers use cases such as web scraping, business intelligence applications, web search, data enrichment, and more.
This integration supports scenarios such as:
- On-demand access to relevant web data for accurate inference and up-to-date responses.
- RAG pipelines and agent-driven RAG workflows.
- Dynamic data feeds that help agents make informed decisions, such as monitoring news, competitor pricing, and social media trends.
- Web search(via SERP scraping) for data validation and information gathering.
- Prompt-based web searching.
Technical Walkthrough: Integrating Bright Data with LlamaIndex
Let’s explore a practical example of how Bright Data and LlamaIndex work together to enable web data access in an AI agent.
Step 1: Install Required Packages
Create and activate a Python virtual environment. Then, install the LlamaIndex and LlamaIndex Bright Data packages using the following command:
pip install llama-index llama-index-tools-brightdata
Step 2: Configure OpenAI
Import the required packages, configure your API key, and initialize the LLM integration for your agent:
python
import openai
from llama_index.llms.openai import OpenAI
openai.api_key = "your-openai-key"
llm = OpenAI(model="gpt-4o-mini")This example uses OpenAI’s models, but you can replace them with any other supported LLMs by adjusting the code as needed.
While we set the gpt-4o-mini model, you can change that to any model you prefer. We recommend setting a general-purpose model.
Step 3: Integrate Bright Data Tools
Before proceeding, make sure you have your Bright Data API key and Web Unlocker zone ready. You can obtain your API key and create the zone and by signing up for a free trial on the Bright Data dashboard.
Import the LlamaIndex Bright Data module from llama-index-tools-brightdata, and get the list of tools for your AI agent:
python
from llama_index.tools.brightdata import BrightDataToolSpec
brightdata_tool_spec = BrightDataToolSpec(
api_key="your-brightdata-api-key",
zone="your-webunlocker-zone-name", # e.g., "unlocker" or "web_unlocker"
verbose=True # To monitor what the tools are doing
)
brightdata_tools = brightdata_tool_spec.to_tool_list()As of today, the BrightDataToolSpec available in the llama-index-tools-brightdata package provides the following web scraping and search capabilities:
| Tool Name | Description | Reference |
|---|---|---|
| scrape_as_markdown | Scrapes a web page and returns the content in Markdown format. | Scrape as markdown |
| get_screenshot | Takes a screenshot of a specified web page and saves it to a local path. | Return a screenshot |
| search_engine | Performs a web search on search engines like Google, Bing, and Yandex. | SERP API |
| web_data_feed | Retrieves structured data from sources like LinkedIn, Amazon, Instagram, and more. | Web Scraper API |
The tools available in the llama-index-tools-brightdata package offer comprehensive support for accessing web data. They are designed to bypass anti-scraping measures and include built-in proxy management, JavaScript rendering, CAPTCHA solving, and many other features. The output from these tools is optimized for LLMs to minimize token usage and improve processing speed.
Step 4: Initialize the Agent
Initialize the AI agent with the Bright Data tools and a system prompt:
python
agent = FunctionAgent(
tools=[*brightdata_tools],
llm=llm,
system_prompt=(
"You are a helpful assistant capable of searching the web, "
"extracting data from web pages, connecting to data feeds "
"to back your responses and perform scraping tasks."
)
) In this example, we wrote a general system prompt instructing the AI agent to use web data when needed. For specific tasks, you can customize the system prompt to fit your requirements and even choose to use only a subset of the tools available from BrightDataToolSpec.
Step 5: Execute the Agent
With our tools integrated, the agent is now equipped to perform a variety of tasks. Let’s test it on some common scenarios.
1. Data feeding: The agent uses the web_data_feed tool to retrieve structured data from Amazon, then summarizes it in a concise report.
python
response = await agent.run("""
Provide a short summary of the key characteristics (price, reviews, etc.) of this Amazon product:
https://www.amazon.com/ATHMILE-Quick-Dry-Barefoot-Exercise-Accessories/dp/B09Q3MYDQH/
""")
print(str(response))text
### ATHMILE Water Shoes Overview
- **Product Title**: Water Shoes for Women Men Quick-Dry Aqua Socks
- **Brand**: ATHMILE
- **Price**: $6.99 (discounted from $7.99, 13% off)
- **Availability**: In Stock
- **Customer Reviews**: 21,069 reviews with an average rating of 4.4 out of 5 stars.
- **Best Sellers Rank**: #1 in Women's Water Shoes
- **Amazon's Choice**: Yes
#### Key Features:
- **Material**: Made from breathable, quick-dry elastic fabric.
- **Sole**: Rubber sole with excellent grip and drainage.
- **Weight**: Lightweight (0.22 pounds), easy to carry.
- **Comfort**: Designed for a snug fit, providing comfort during various activities.
- **Protection**: Anti-slip sole protects feet from sharp objects and hot surfaces.
- **Occasions**: Suitable for beach, swimming, yoga, surfing, and other outdoor activities.
#### Customer Feedback:
- **Positive Aspects**: Comfortable, lightweight, stylish, and good value for money.
- **Mixed Feedback**: Durability varies; some users report good longevity while others mention issues with wear and tear.
#### Additional Information:
- **Delivery Options**: Free delivery on orders over $35; Prime members can get same-day delivery.
- **Product Images**:  2. Screenshotting: The agent calls the get_screenshot tool to visit Wikipedia.org, take a screenshot of the homepage, and save it locally as screenshot.jpg .
python
response = await agent.run("""Visit wikipedia.org, take a screenshot of the homepage, and save it as a local file named screenshot.jpg
""")
print(str(response))
A screenshot.jpg file containing the following image will appear in the project directory:
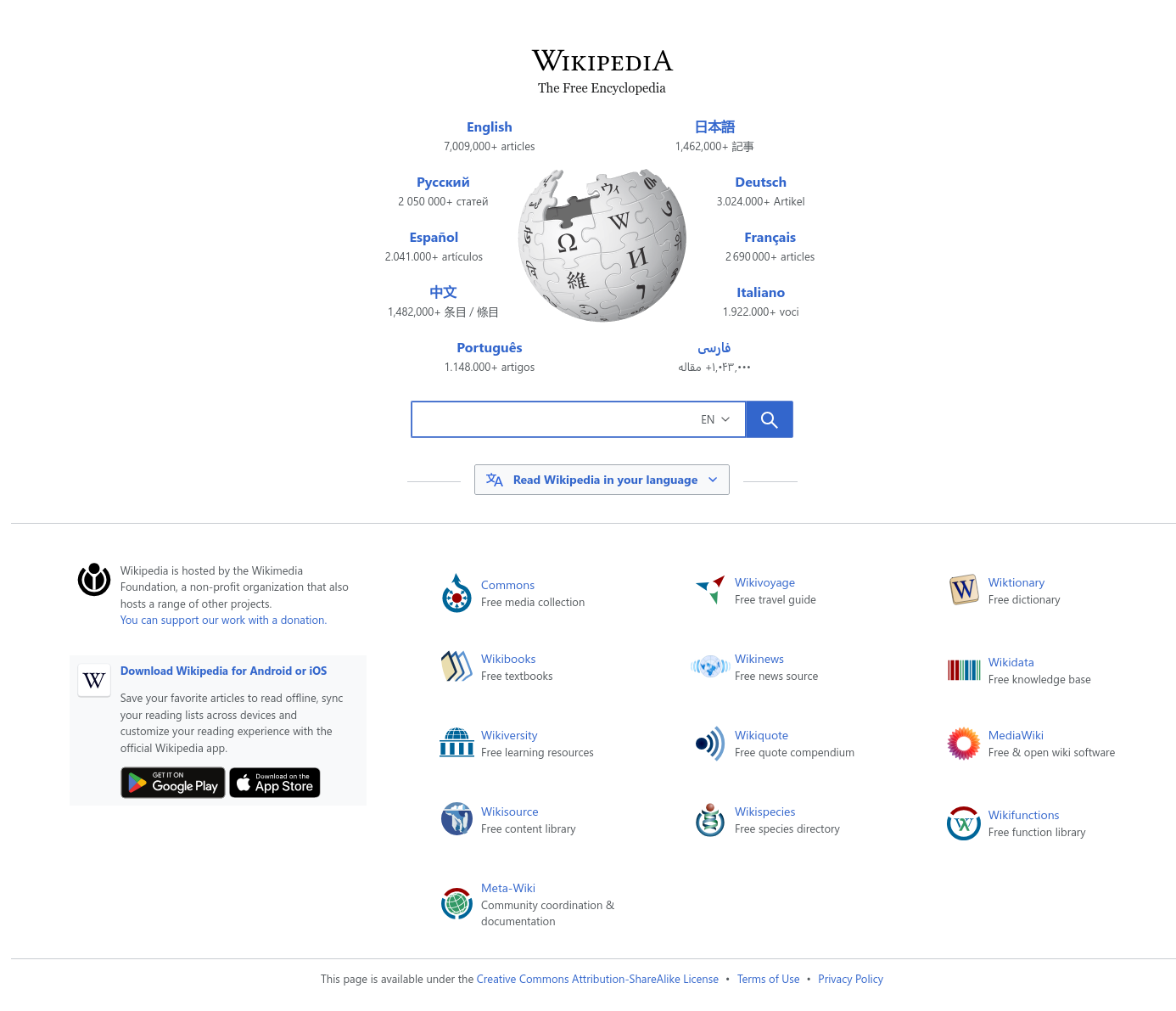
3. Web search + scraping: The agent utilizes Bright Data’s search_engine tool to find the top 3 Google articles about new AI protocols. Next, it accesses each article with the scrape_as_markdown tool to summarize the content as requested.
python
response = await agent.run("""
Select the top 3 articles about the new AI protocols.
Then, for each article, access its content and provide a brief 30-word summary,
including a link to the original source for further reading.
""")
print(str(response))
text
1. **MCP, ACP, and Agent2Agent set standards for scalable AI results**
This article discusses emerging AI protocols that standardize connections and agent management, helping organizations transition from experimentation to practical AI solutions.
[Read more here](https://www.cio.com/article/3991302/ai-protocols-set-standards-for-scalable-results.html)
2. **Introducing the Model Context Protocol**
The Model Context Protocol (MCP) is an open standard that facilitates secure connections between AI systems and data sources, enhancing the relevance of AI responses and reducing integration complexity.
[Read more here](https://www.anthropic.com/news/model-context-protocol)
3. **Google A2A Protocol: The Future of AI Agent Collaboration**
This article explores Google's Agent2Agent protocol, designed to enable interoperability among AI agents, allowing businesses to manage diverse AI systems more effectively across platforms.
[Read more here](https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/)
The complete code for integrating LlamaIndex with Bright Data tools in an AI agent is:
python
# pip install llama-index llama-index-tools-brightdata
import asyncio
import openai
from llama_index.llms.openai import OpenAI
from llama_index.tools.brightdata import BrightDataToolSpec
from llama_index.core.agent.workflow import FunctionAgent
# Register your OpenAI API key
openai.api_key = "your-openai-key"
# Initialize the LLM for the AI agent
llm = OpenAI(model="gpt-4o-mini")
# Retrieve the Bright Data tools
brightdata_tool_spec = BrightDataToolSpec(
api_key="your-brightdata-api-key",
zone="your-webunlocker-zone-name", # e.g., "unlocker" or "web_unlocker",
verbose=True # To monitor what the tools are doing
)
brightdata_tools = brightdata_tool_spec.to_tool_list()
# Create an AI agent that can use the Bright Data tools
agent = FunctionAgent(
tools=[*brightdata_tools],
llm=llm,
system_prompt=(
"You are a helpful assistant capable of searching the web, "
"extracting data from web pages, connecting to data feeds "
"to back your responses and perform scraping tasks."
)
)
async def main():
# Submit the query to the agent and print the response
response = await agent.run("""
Provide a short summary of the key characteristics (price, reviews, etc.) of this Amazon product:
https://www.amazon.com/ATHMILE-Quick-Dry-Barefoot-Exercise-Accessories/dp/B09Q3MYDQH/
""")
print(str(response))
if __name__ == "__main__":
asyncio.run(main())Next Steps
Connecting Bright Data in LlamaIndex lays the foundation for building powerful web-enabled LLM applications, unlocking a wide range of possibilities.
You can improve your agent to specialize in web scraping or develop it around web search tasks for SERP retrieval and analysis. Ultimately, you can create a highly capable, tool-equipped chatbot by integrating Bright Data with LlamaIndex via MCP.
For more advanced use cases, explore the Bright Data documentation and LlamaIndex resources referenced throughout this guide to fully understand the breadth of this integration’s capabilities.