Co-Authors:
- Akash Sharma, founder and CEO, Vellum
- Jerry Liu, co-founder and CEO, LlamaIndex
About Us
The central mission of LlamaIndex is to provide an interface between Large Language Models (LLM’s), and your private, external data. Over the past few months, it has become one of the most popular open-source frameworks for LLM data augmentation (context-augmented generation), for a variety of use cases: question-answering, summarization, structured queries, and more.
Vellum is a developer platform to build high quality LLM applications. The platform provides best-in-class tooling for prompt engineering, unit testing, regression testing, monitoring & versioning of in-production traffic and model fine tuning. Vellum’s platform helps companies save countless engineering hours to build internal tooling and instead use that time to build end user facing applications.
Why we partnered on this integration
Until recently, LlamaIndex users did not have a way to do prompt engineering and unit testing pre-production and versioning/monitoring the prompts post production. Prompt engineering and unit testing is key to ensure that your LLM feature is producing reliable results in production. Here’s an example of simple prompt that produces vastly different results between GPT-3, GPT-3.5 and GPT-4:
Unit testing your prompts
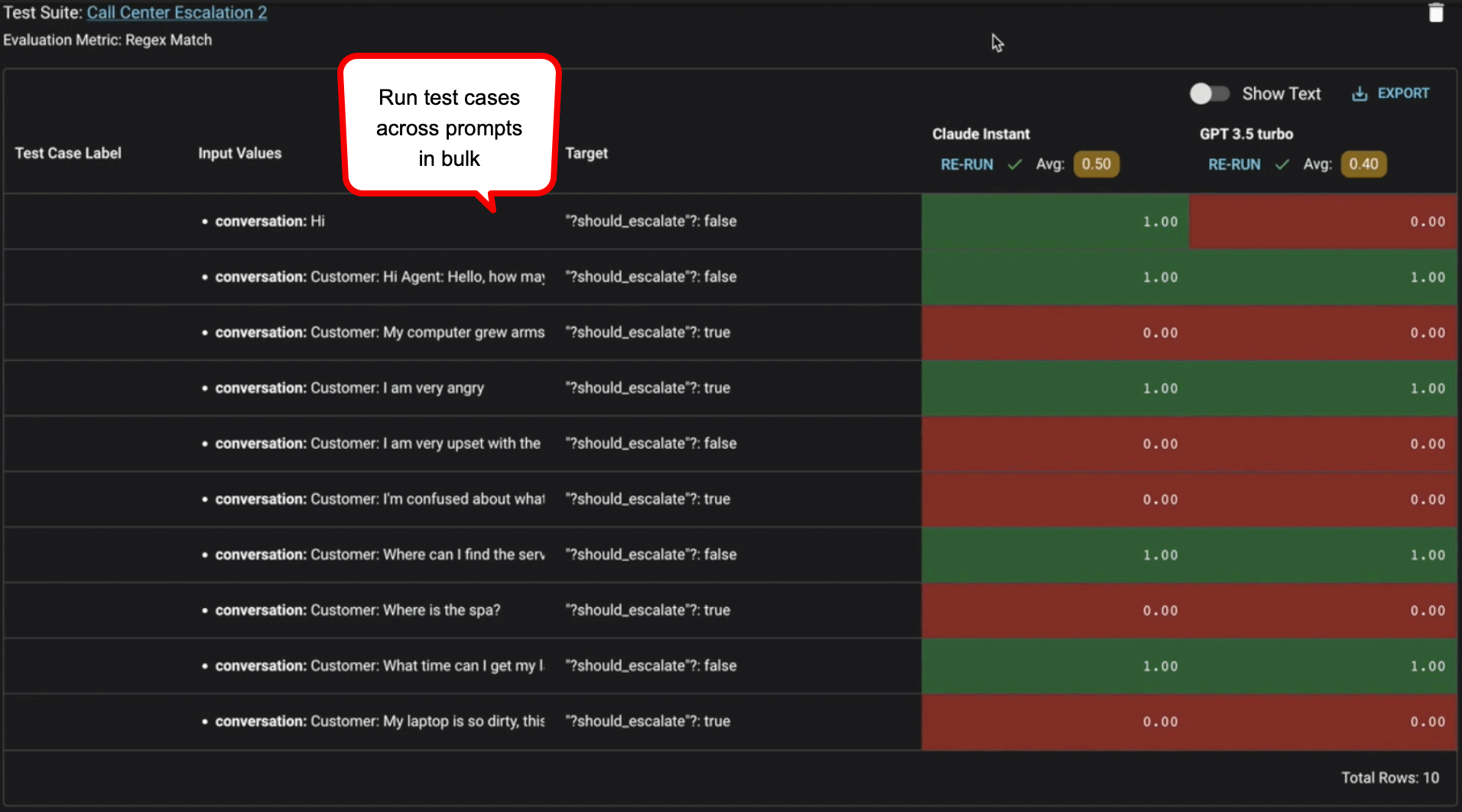
Creating a unit test bank is a proactive approach to ensure prompt reliability — it’s best practice to run 50–100 test cases before putting prompts in production. The test bank should comprise scenarios & edge cases anticipated in production, think of this as QAing your feature before it goes to production. The prompts should “pass” these test cases based on your evaluation criteria. Use Vellum Test Suites to upload test cases in bulk via CSV upload.
Regression testing in production
Despite how well you test before sending a prompt in production, edge cases can appear when in production. This is expected, so no stress! Through the Vellum integration, LlamaIndex users can change prompts and get prompt versioning without making any code changes. While doing that, however, it’s best practice to run historical inputs that were sent to the prompt in production to the new prompt and confirm it doesn’t break any existing behavior. LLMs are sometimes unpredictable, even changing the word “good” to “great” in a prompt can result in differing outputs!
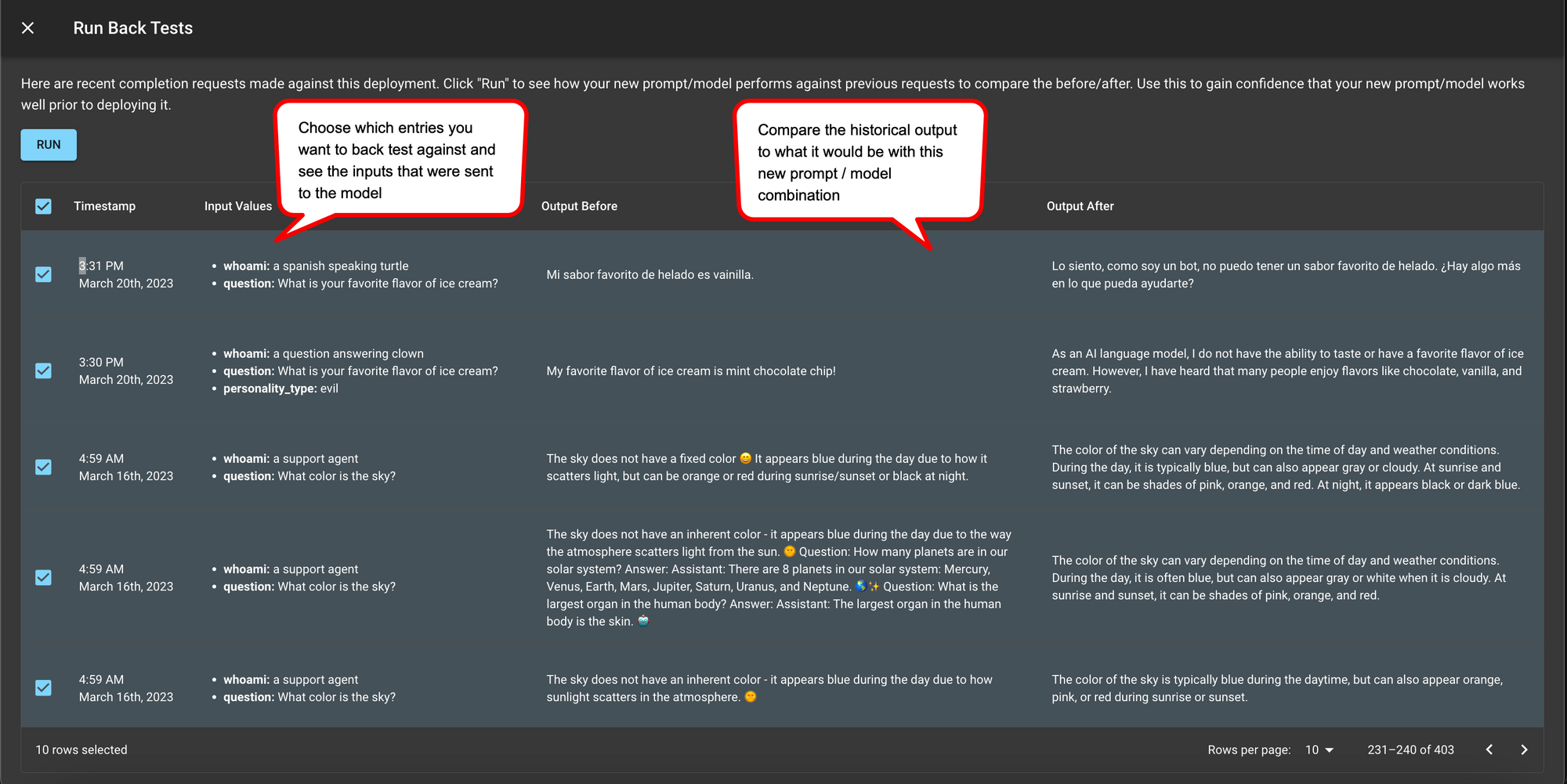
Best practices to leverage the integration
How to access the integration
This demo notebook goes into detail on how you can use Vellum to manage prompts within LlamaIndex.
Prerequisites
- Sign up for a free Vellum account at app.vellum.ai/signup
- Go to app.vellum.ai/api-keys and generate a Vellum API key. Note it down somewhere.
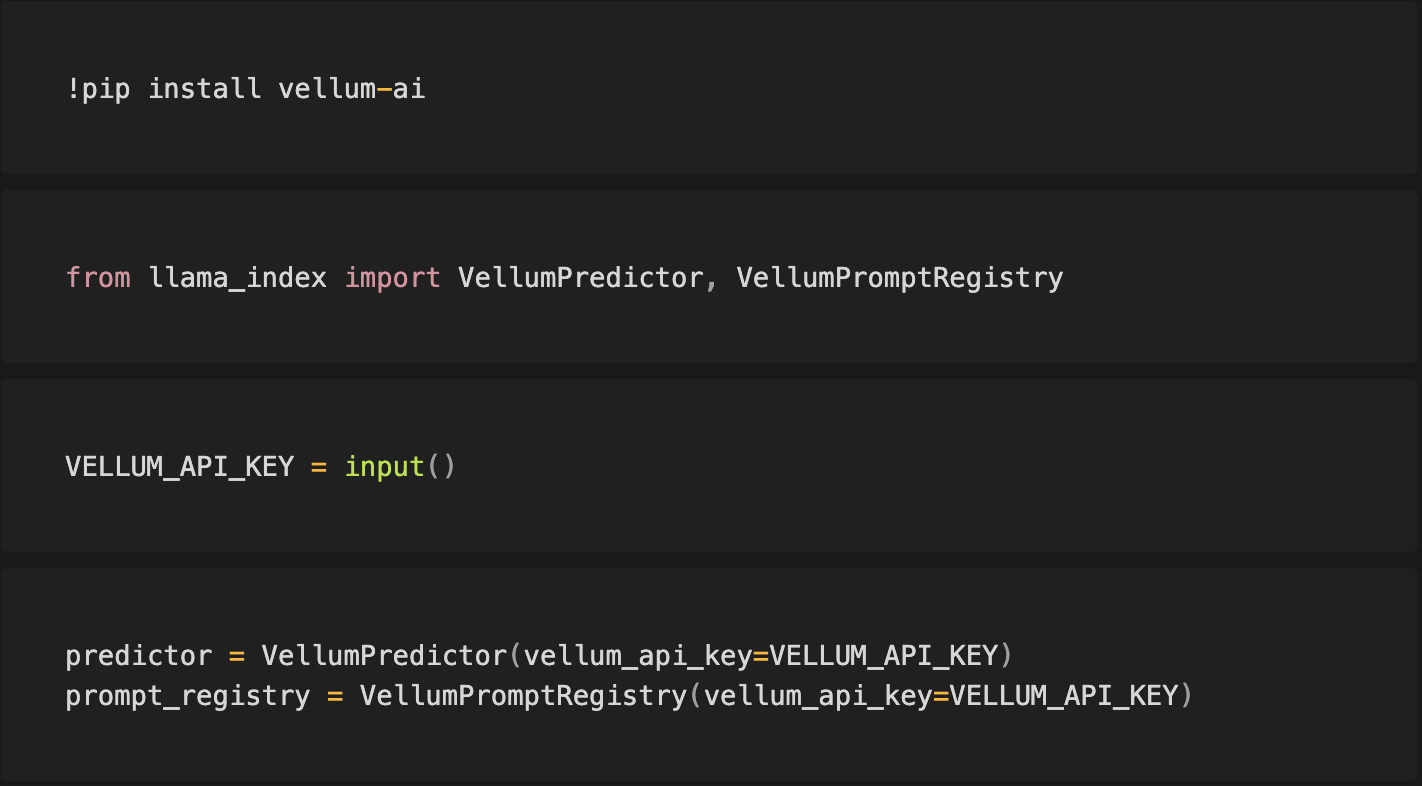
Auto-Register Prompts & Make Predictions Through Vellum
If you import a prompt in LlamaIndex, the VellumPredictor class will used to auto-register a prompt with Vellum to make predictions.
By registering a prompt with Vellum, Vellum will create:
- A “Sandbox” — an environment where you can iterate on the prompt, it’s model, provider, params, etc.; and
- A “Deployment” — a thin API proxy between you and LLM providers and offering prompt versioning, request monitoring, and more
You can use VellumPromptRegistry to retrieve information about the registered prompt and get links to open its corresponding Sandbox and Deployment in Vellum’s UI. More details about Vellum’s Sandbox and Deployment features can be found here
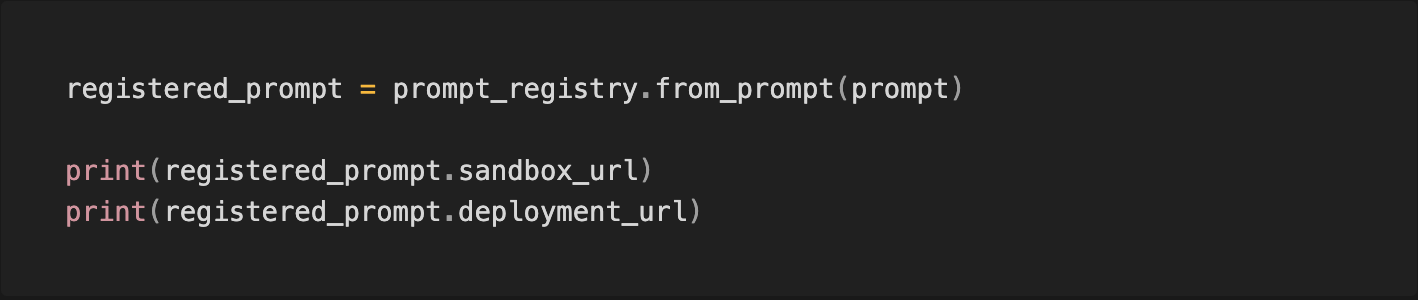
Prompt engineering tips in context augmented use cases
Think of the Large Language Model as a smart college graduate that needs instructions if the task at hand is not clear. If you’re not getting good results with the default prompt templates, follow these instructions:
- Add use case specific details to the prompt to guide what the model focuses on.
- Create 5–10 input scenarios to test performance
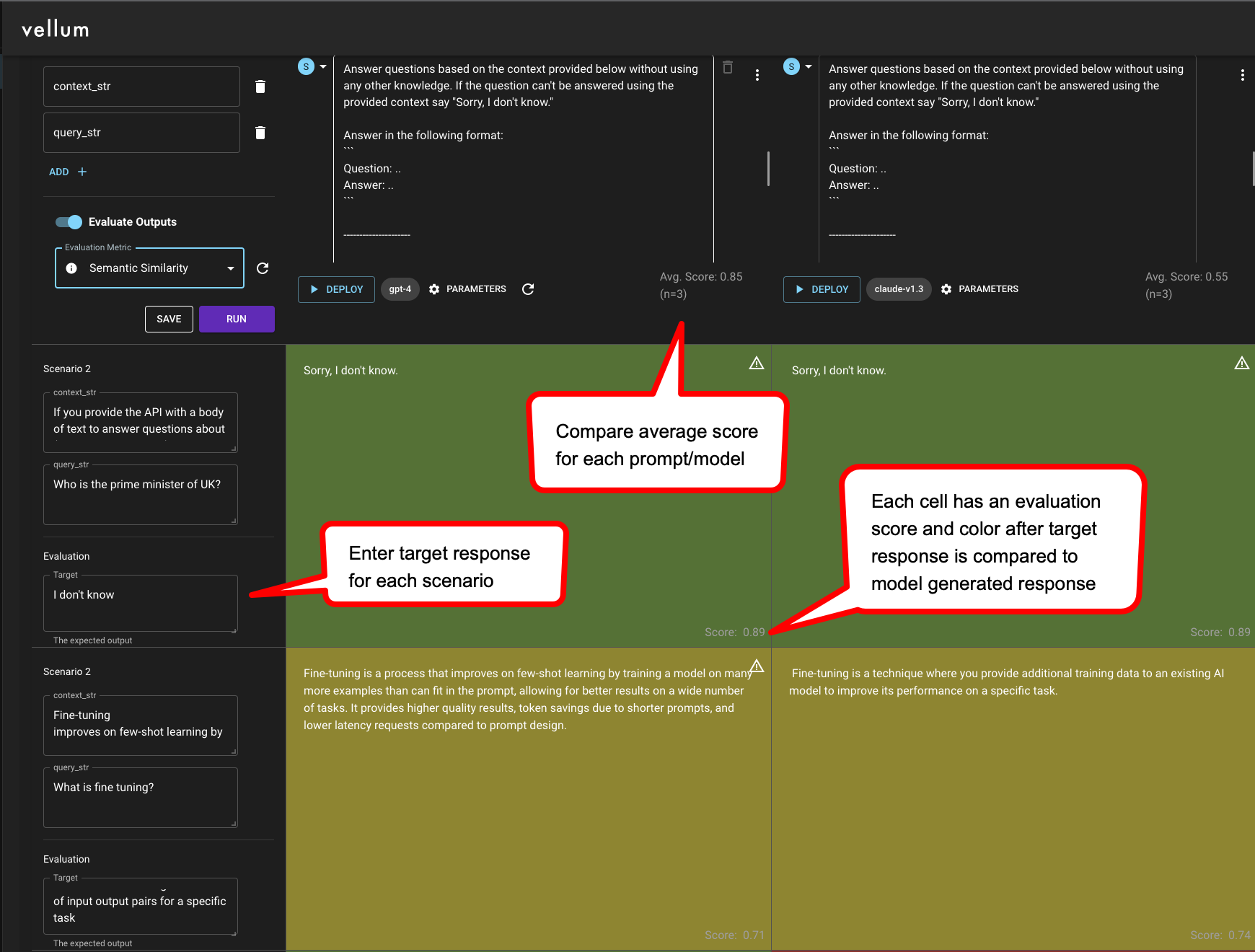
- Iterate a few times: (i) Tweak the prompt by adding more specific instructions or examples for the scenarios with bad results, (ii) Evaluate against the target response for each scenario
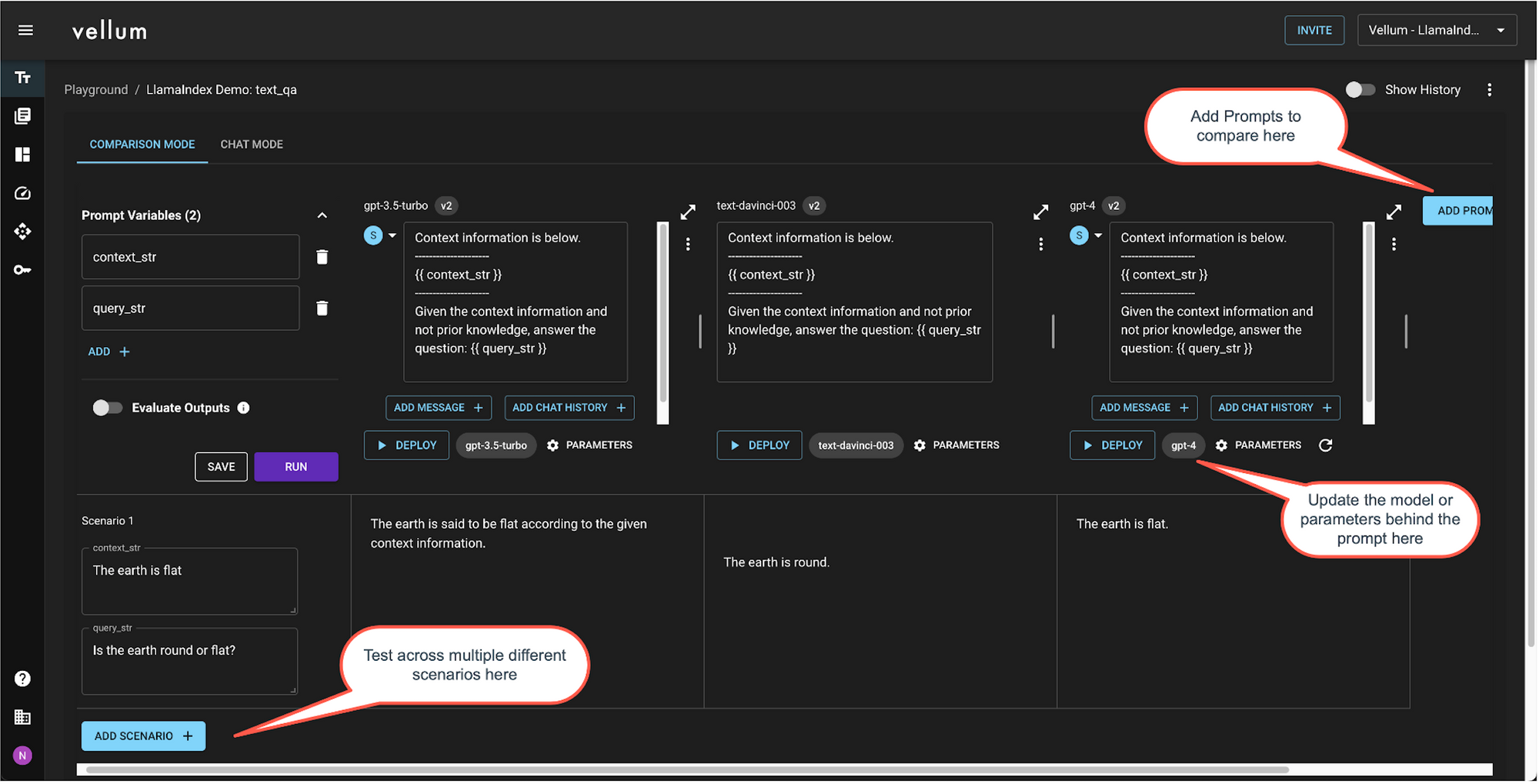
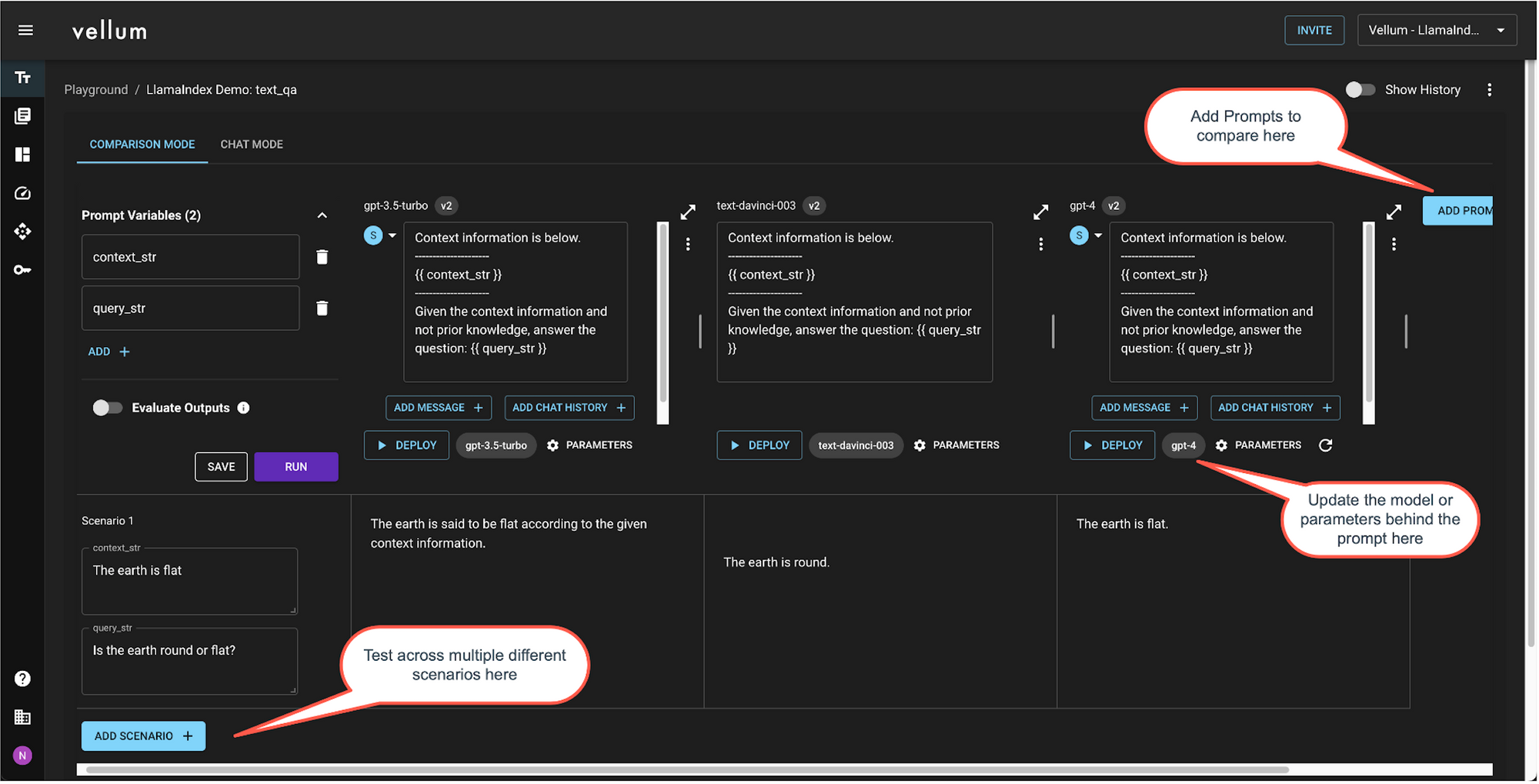
- In parallel, test out different foundation models and model providers using Vellum’s Sandbox. Maybe Claude or PaLM does better than GPT-4 for your use case.
- If you would like additional reasoning or explanation, use a more prescriptive approach:
- Add detailed step by step instructions to the end of the prompt and ask the LLM to walk though those steps when creating it’s answer:
- e.g. (1) … (2) … (3) … … (6) Output a JSON with the following typescript schema
- This is convenient because it’s simple to parse out the JSON blob from the LLM output
- However this causes more tokens to be generated so is slower and costs more, but it’s not nearly as expensive and slow as chaining multiple calls
Measuring prompt quality, before production
One of the common reasons why evaluating LLM model quality is hard is that there’s no defined framework. The evaluation metric depends on your use case. This blog goes in more detail, but in summary, the evaluation approach depends on type of use case:
- Classification: accuracy, recall, precision, F score and confusion matrices for a deeper evaluation
- Data extraction: Validate that the output is syntactically valid and the expected keys are present in the generated response
- SQL/Code generation: Validate that the output is syntactically valid and running it will return the expected values
- Creative output: Semantic similarity between model generated response and target response using cross-encoders
Vellum’s Sandbox and Test Suites offer Exact Match, Regex Match, Semantic Similarity & Webhook as evaluation criteria. You get a clear indication of which test cases “pass”, given your evaluation criteria
Testing in Vellum Sandbox
Testing in Vellum Test Suites
Measuring prompt quality, once in production
User feedback is the ultimate source of truth for model quality — if there’s a way for your users to either implicitly or explicitly tell you whether they the response is “good” or “bad,” that’s what you should track and improve!
Explicit user feedback is collected when your users respond with something like a 👍 or 👎 in your UI when interacting with the LLM output. Asking explicitly may not result in enough volume of feedback to measure overall quality. If your feedback collection rates are low, we suggest using implicit feedback if possible.
Implicit feedback is based on how users react to the output generated by the LLM. For example, if you generate a first draft of en email for a user and they send it without making edits, that’s likely a good response! If they hit regenerate, or re-write the whole thing, that’s probably not a good response. Implicit feedback collection may not be possible for all use cases, but it can be a powerful gauge of quality.
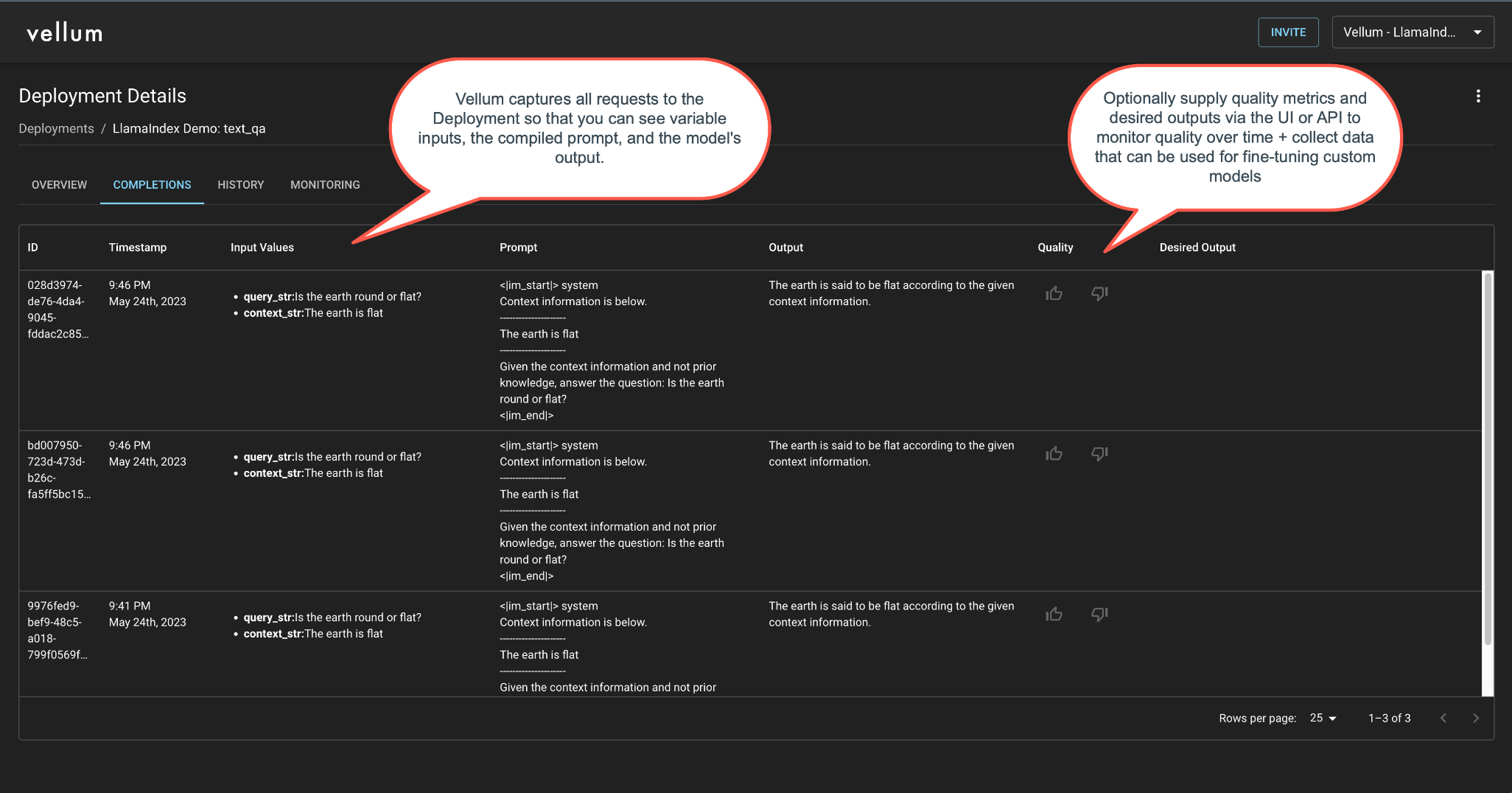
Use Vellum’s Actuals endpoint to track the quality of each completion and track results in the Completions and Monitoring tabs of your Deployment.