This is a guest post from Uptrain.
We are excited to announce the recent integration of LlamaIndex with UpTrain - an open-source LLM evaluation framework to evaluate your RAG pipelines and experiment with different configurations. As an increasing number of companies are graduating their LLM prototypes to production-ready systems, robust evaluations provide a systematic framework to make decisions rather than going with the ‘vibes’. By combining LlamaIndex's flexibility and UpTrain's evaluation framework, developers can experiment with different configurations, fine-tuning their LLM-based applications for optimal performance.
About UpTrain
UpTrain [github || website || docs] is an open-source platform to evaluate and improve LLM applications. It provides grades for 20+ preconfigured checks (covering language, code, embedding use cases), performs root cause analyses on instances of failure cases and provides guidance for resolving them.
Key Highlights:
- Data Security: As an open-source solution, UpTrain conducts all evaluations and analyses locally, ensuring that your data remains within your secure environment (except for the LLM calls).
- Custom Evaluator LLMs: UpTrain allows for customisation of your evaluator LLM, offering options among several endpoints, including OpenAI, Anthropic, Llama, Mistral, or Azure.
- Insights that help with model improvement: Beyond mere evaluation, UpTrain performs root cause analysis to pinpoint the specific components of your LLM pipeline, that are underperforming, as well as identifying common patterns among failure cases, thereby helping in their resolution.
- Diverse Experimentations: The platform enables experimentation with different prompts, LLM models, RAG modules, embedding models, etc. and helps you find the best fit for your specific use case.
- Compare open-source LLMs: With UpTrain, you can compare your fine-tuned open-source LLMs against proprietary ones (such as GPT-4), helping you to find the most cost-effective model without compromising quality.
In the following sections, we will illustrate how you can use UpTrain to evaluate your LlamaIndex pipeline. The evaluations demonstrated here will help you quickly find what’s affecting the quality of your responses, allowing you to take appropriate corrective actions.
LlamaIndex x UpTrain Callback Handler
We introduce an UpTrain Callback Handler which makes evaluating your existing LlamaIndex Pipeline seamless. By adding just a few lines of code, UpTrain will automatically perform a series of checks - evaluating the quality of generated responses, the quality of contextual data retrieved by the RAG pipeline as well as the performance of all the interim steps.
If you wish to skip right ahead to the tutorial, check it out here.

Evals across the board: From Vanilla to Advanced RAG
Vanilla RAG involves a few steps. You need to embed the documents and store them in a vector database. When the user asks questions, the framework embeds them and uses similarity search to find the most relevant documents. The content of these retrieved documents, and the original query, are then passed on to the LLM to generate the final response.
While the above is a great starting point, there have been a lot of improvements to achieve better results. Advanced RAG applications have many additional steps that improve the quality of the retrieved documents, which in turn improve the quality of your responses.
But as Uncle Ben famously said to Peter Parker in the GenAI universe:
“With increased complexity comes more points of failure.”.
Most of the LLM evaluation tools only evaluate the final context-response pair and fail to take into consideration the intermediary steps of an advanced RAG pipeline. Let’s look at all the evaluations provided by UpTrain.
Addressing Points of Failure in RAG Pipelines
1. RAG Query Engine Evaluation
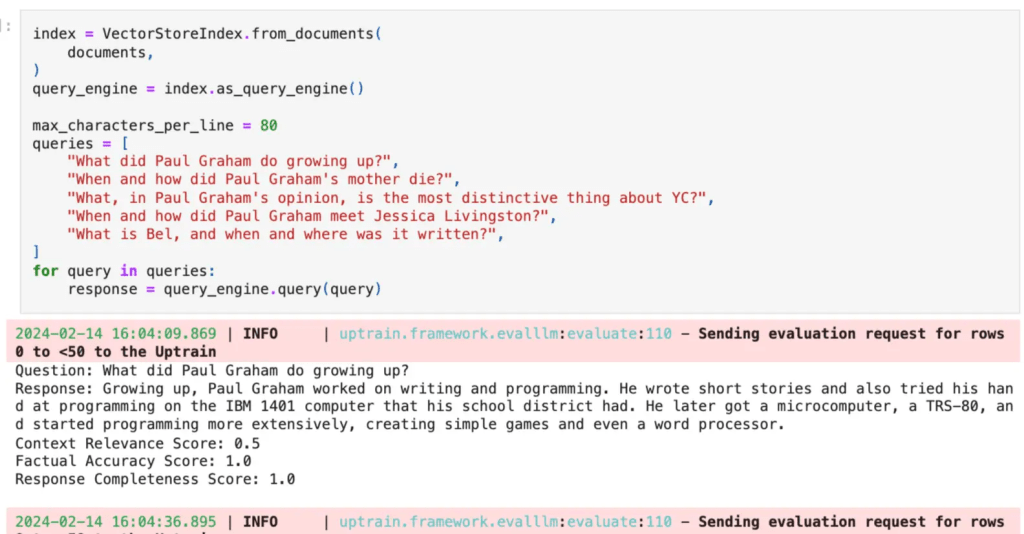
Let's first take a Vanilla RAG Pipeline and see how you can test its performance. UpTrain provides three operators curated for testing both the retrieved context as well as the LLM's response.
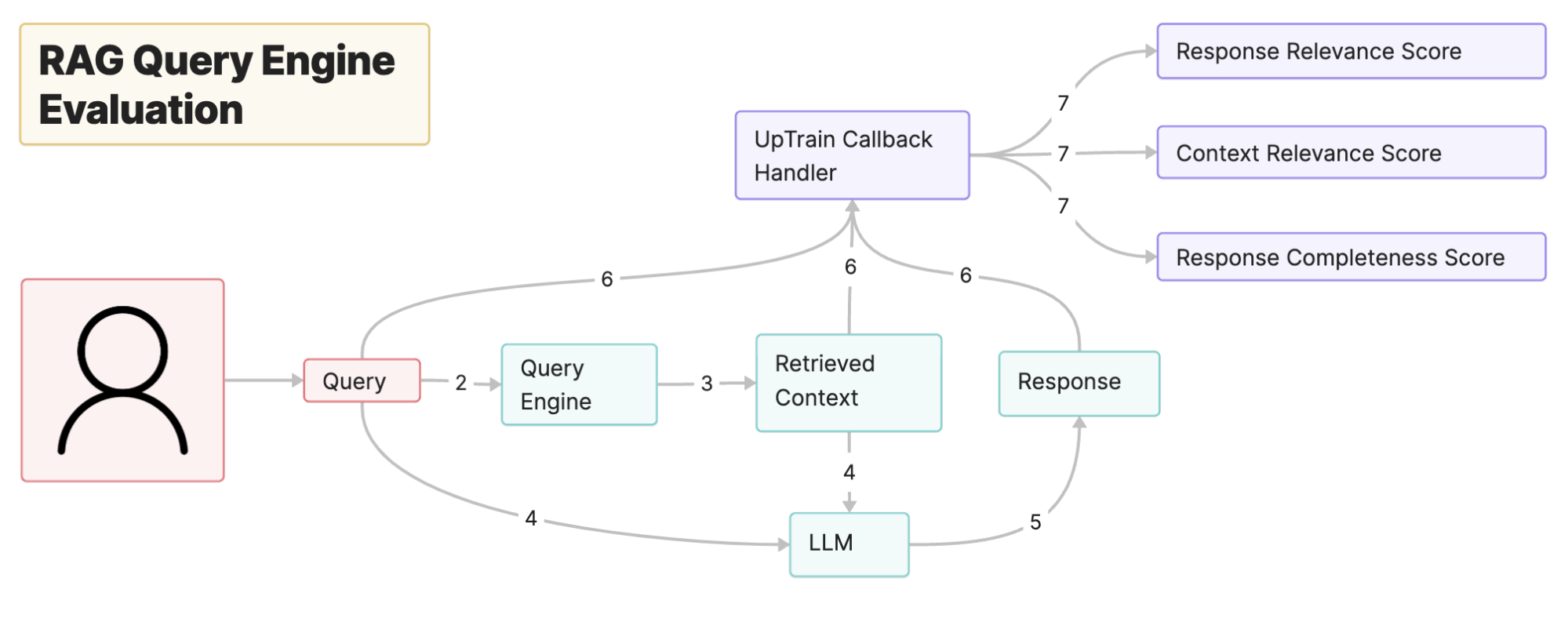
- Context Relevance: However informative the documents retrieved might be, if they are not relevant to your query, you will likely not get a response that answers your query. The Context Relevance operator determines if the documents fetched from the vector store contain information that can be used to answer your query.
- Factual Accuracy: Now that we have checked if the context contains information to answer our query, we will check if the response provided by the LLM is backed by the information present in the context. The Factual Accuracy operator assesses if the LLM is hallucinating or providing information that is not present in the context.
- Response Completeness: Not all queries are straightforward. Some of them have multiple parts to them. A good response should be able to answer all the aspects of the query. The Response Completeness operator checks if the response contains all the information requested by the query.
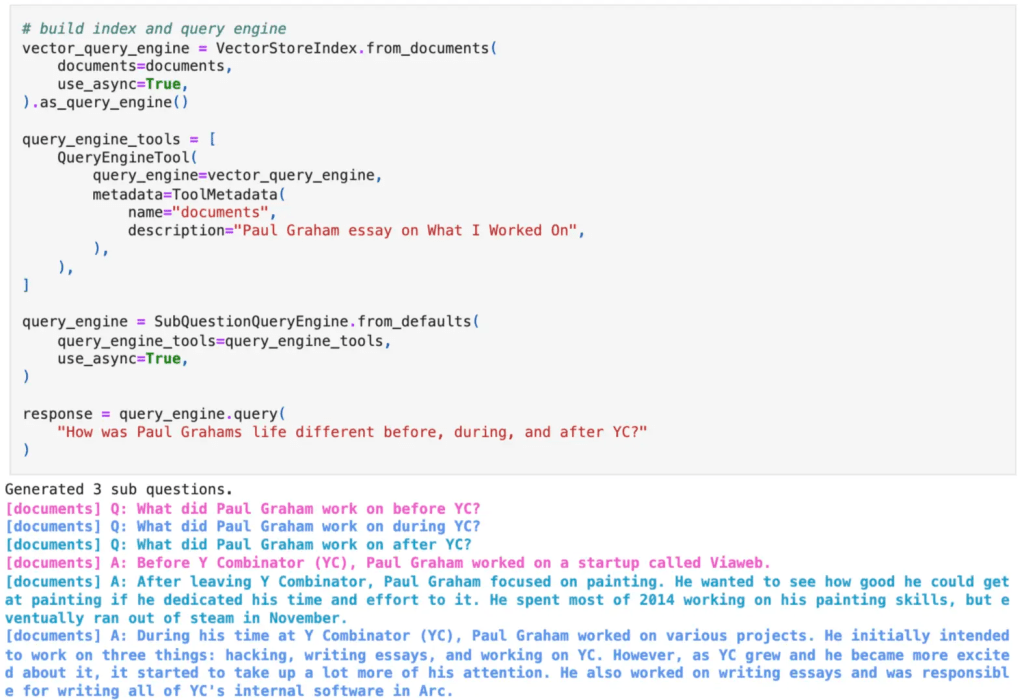
2. Sub-Question Query Engine Evaluation
Let's say you tried out a Vanilla RAG pipeline and got consistently low Response Completeness scores. This means that the LLM is not answering all aspects of your query. One of the ways to solve this is by splitting the query into multiple smaller sub-queries that the LLM can answer more easily. To do this, you can use the SubQuestionQueryGeneration operator provided by LlamaIndex. This operator decomposes a question into sub-questions, generating responses for each using an RAG query engine.
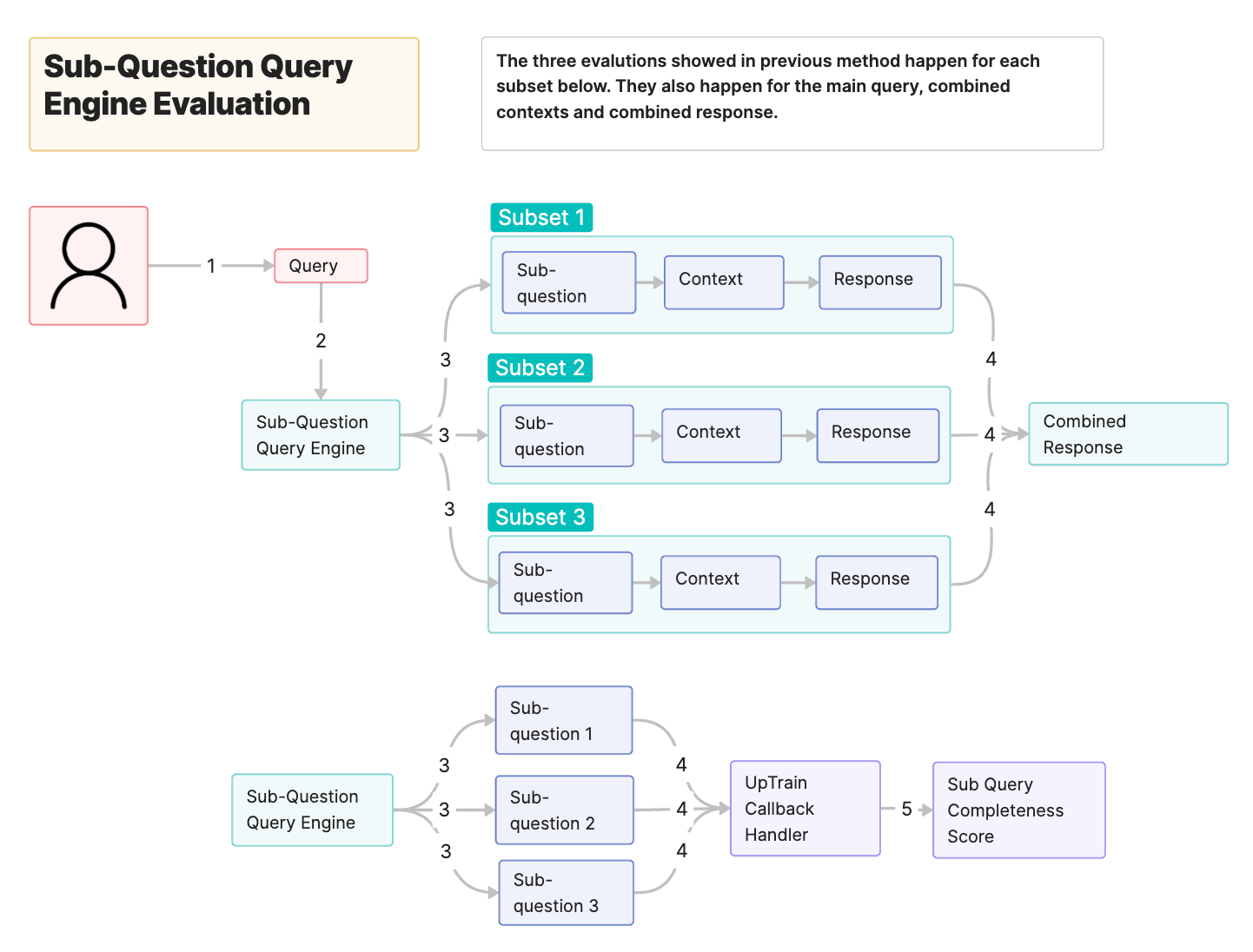
If you include this SubQuery module in your RAG pipeline, it introduces another point of failure, e.g. what if the sub-questions that we split our original question aren't good representations of it? UpTrain automatically adds new evaluations to check how well the module performs:
- Sub Query Completeness: It evaluates whether the sub-questions accurately and comprehensively cover the original query.
- Context Relevance, Factual Accuracy and Response Completeness for each of the sub-queries.

3. Reranking Evaluations
We looked at a way of dealing with low Response Completeness scores. Now, let's look at a way of dealing with low Context Relevance scores.
RAG pipelines retrieve documents based on semantic similarity. These documents are ordered based on how similar they are to the query asked. However, recent research [Lost in the Middle: How Language Model Uses Long Contexts] has shown that the LLMs are sensitive to the placement of the most critical information within the retrieved context. To solve this, you might want to add a reranking block.
Reranking involves using a semantic search model (specially tuned for the reranking task) that breaks down the retrieved context into smaller chunks, finds the semantic similarity between them and the query and rewrites the context by ranking them in order of their similarity.
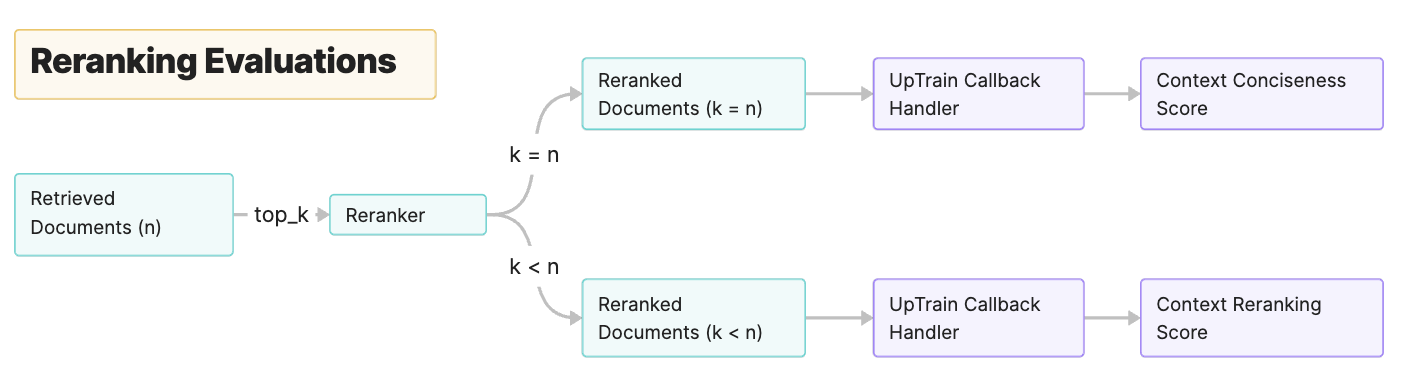
We observed that when using the reranking operators in LlamaIndex, two scenarios can occur. These scenarios differ based on the number of nodes before and after the reranking process:
a. Same Number of Nodes Before and After Reranking:
If the number of nodes after the reranking remains the same, then we need to check if the new order is such that nodes higher in rank are more relevant to the query as compared to the older order. To check for this, UpTrain provides a Context Reranking operator.
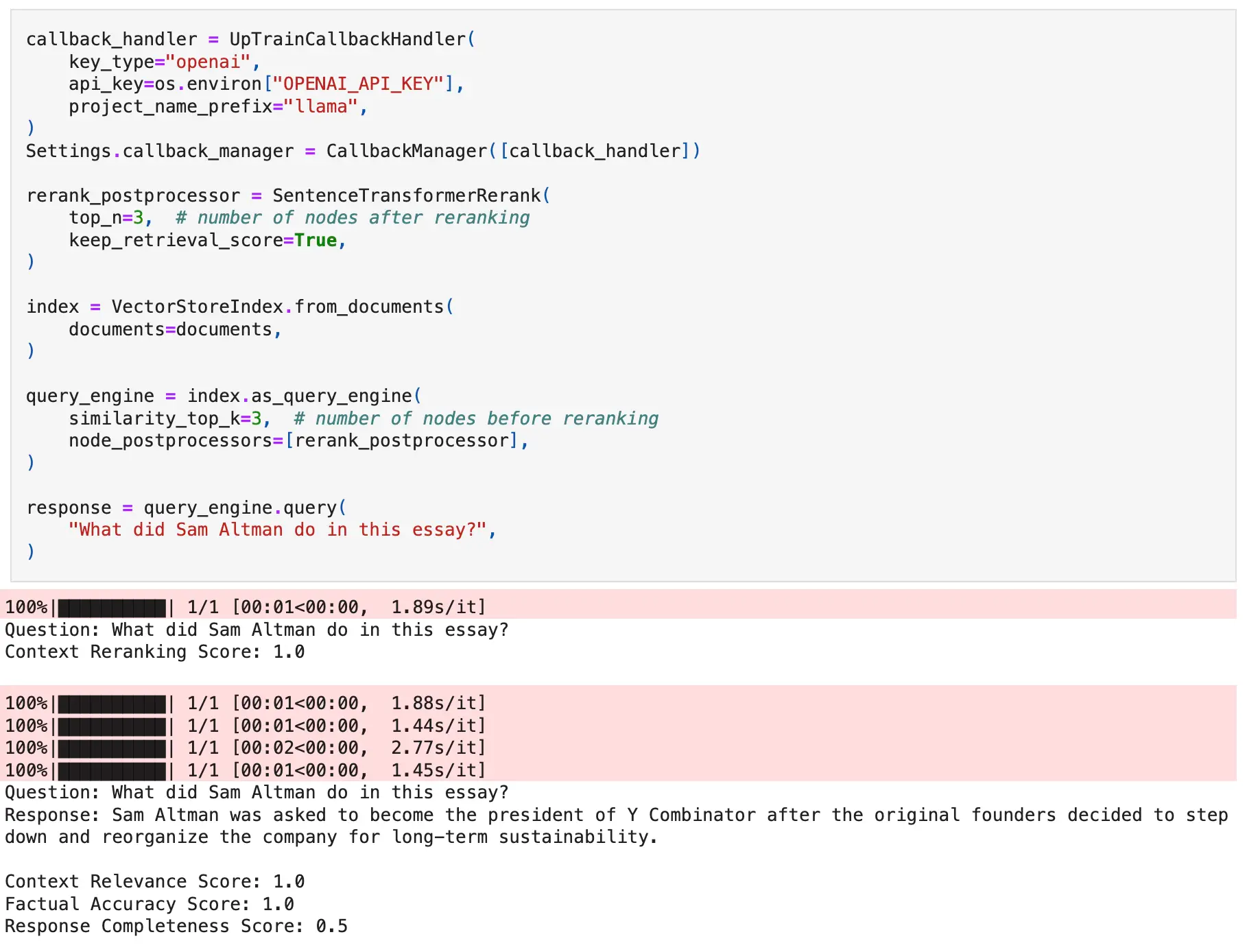
- Context Reranking: Checks if the order of reranked nodes is more relevant to the query than the original order.
b. Fewer Number of Nodes After Reranking:
Reducing the number of nodes can help the LLM give better responses. This is because the LLMs process smaller context lengths better. However, we need to make sure that we don't lose information that would have been useful in answering the question. Therefore, during the process of reranking, if the number of nodes in the output is reduced, we provide a Context Conciseness operator.
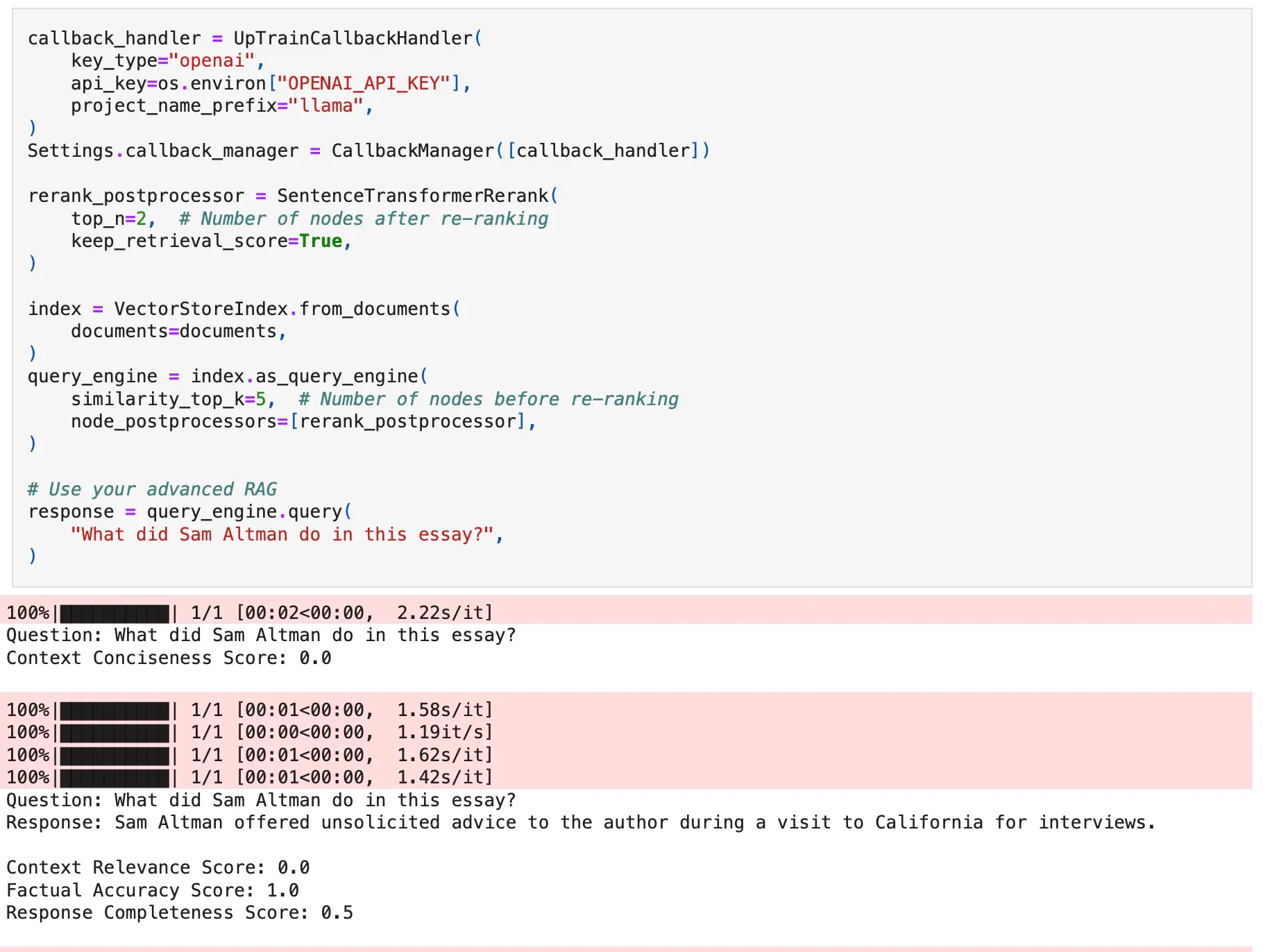
- Context Conciseness: Examines whether the reduced number of nodes still provides all the required information.
Key Takeaways: Enhancing RAG Pipelines Through Advanced Techniques and Evaluation
Let's do a quick recap here. We started off with a Vanilla RAG pipeline and evaluated the quality of the generated response and retrieved context. Then, we moved to advanced RAG concepts like the SubQuery technique (used to combat cases with low Response Completeness scores) and the Reranking technique (used to improve the quality of retrieved context) and looked at advanced evaluations to quantify their performance.
This essentially provides a framework to systematically test the performance of different modules as well as evaluate if they actually lead to better quality responses by making data-driven decisions.
Much of the success in the field of Artificial intelligence can be attributed to experimentation with different architectures, hyperparameters, datasets, etc., and our integration with UpTrain allows you to import those best practices while building RAG pipelines. Get started with uptrain with this quickstart tutorial.
References
- UpTrain Callback Handler Tutorial
- UpTrain GitHub Repository
- Advanced RAG Techniques: an Illustrated Overview
- Lost in the Middle: How Language Models Use Long Contexts
- UpTrainCallbackHandler documentation
- UpTrain Website