This is a guest post from one of our partners.
Introduction
DeepEval is an open-source LLM evaluation library in Python that enables engineers to unit test all types of LLM applications—whether you're building RAG pipelines, chatbots, or AI agents.
It offers 50+ out-of-the-box metrics covering RAG, conversational, red-teaming, agentic, and multimodal use cases. DeepEval also offers custom metric builders, making it easy to evaluate domain-specific applications with custom criteria.
LlamaIndex is an open-source framework for building complex, agentic applications. It provides flexible tools to connect language models with external data, memory, and tools—making it easy to design powerful multi-step agents.
LlamaIndex also allows you to build powerful RAG pipelines for both text-based and multimodal applications. When combined with DeepEval's RAG metrics (which includes multimodal support), you can optimize RAG performance by identifying the best LLM model, prompt templates, and hyperparameters—such as top-K retrieval settings or embedding models—based on evaluation scores.
To begin evaluating, you’ll need to first install DeepEval and Llamaindex.
sh
!pip install -U deepeval llama-index llama-index-readers-web llama-index-llms-openaiWalkthrough: Evaluating LlamaIndex
In this example, we’ll explore how you can use DeepEval metrics to evaluate a simple RAG pipeline built on LlamaIndex.
Step 1: Defining RAG Metrics
DeepEval’s metrics are powered by LLMs. Although you may use any LLM, they’re set to OpenAI’s gpt-4o by default. For the purposes of this tutorial, we’ll define 3 RAG metrics: Answer Relevancy, Faithfulness, and Contextual Precision.
Answer Relevancy
python
from deepeval.metrics import AnswerRelevancyMetric
answer_relevancy = AnswerRelevancyMetric()Answer Relevancy measures how relevant the output of your LLM application is compared to the user input.
Faithfulness
python
from deepeval.metrics import FaithfulnessMetric
faithfulness = FaithfulnessMetric()Faithfulness measures whether the LLM’s output factually aligns with the contents of your RAG’s retrieval context.
Contextual Precision
python
from deepeval.metrics import ContextualPrecisionMetric
contextual_precision = ContextualPrecisionMetric()The Contextual Precision metric evaluates whether the most relevant information chunks are ranked higher than less relevant ones for a given input. In simple terms, it checks that the most useful context appears first in the set of retrieved documents.
Understanding RAG Metrics
A typical RAG pipeline has two main components: the retriever, which retrieves knowledge chunks (retrieval context) based on the user input, and the generator, which produces a response using both the input and the retrieved context.
- Answer Relevancy and Faithfulness assess the quality of the generator.
- Contextual Precision (along with related metrics like Contextual Recall and Contextual Relevancy, not covered in this example) evaluate the quality of the retriever.
It’s important to understand that each metric is uniquely influenced by different parameters in your pipeline. For example, Answer Relevancy is primarily affected by the prompt template, Faithfulness largely depends on the LLM model used, and Contextual Precision reflects the performance of the ranker.
This means that if you receive a low Answer Relevancy score, it’s likely due to issues with your prompt template. Understanding these relationships allows you to use evaluation results to improve your LLM system effectively. If you’re curious, this guide helps you determine which metrics to track, what they measure, and why they matter.
Step 2: Setting up LlamaIndex RAG Application
To set up a simple RAG Application using LlamaIndex, simply use the `VectorStoreIndex` to load your knowledge base documents, before passing it to `VectorIndexRetriever` for your `RetrieverQueryEngine`, which is your main RAG application. We’ll use a top-K of 10 and the gpt-4o model to power our RAG pipeline.
python
from llama_index.core import VectorStoreIndex, Settings, get_response_synthesizer
from llama_index.core.postprocessor import SimilarityPostprocessor
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.readers.web import SimpleWebPageReader
from llama_index.llms.openai import OpenAI
# changing the global default
Settings.llm = OpenAI("gpt-3.5-turbo")
# build index
documents = SimpleWebPageReader(html_to_text=True).load_data(
["https://www.llamaindex.ai/"]
)
index = VectorStoreIndex.from_documents(documents)
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=10,
)
# configure response synthesizer
response_synthesizer = get_response_synthesizer()
# assemble query engine
rag_application = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
node_postprocessors=[SimilarityPostprocessor(similarity_cutoff=0.7)],
)Step 3: Preparing a Test Case
Next, we’ll create a Test Case by defining a user input and generating an LLM response—capturing both the model’s actual output and the retrieved context used during generation. You can think of each test case as a row in your evaluation dataset, essentially serving as a single unit in LLM Unit Testing.
python
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
...
# Run a query through the RAG application to test its response
response = rag_application.query("What is LLamaIndex")
# Extract the actual output (generated answer) from the model
actual_output = response.response
# Extract the retrieved context used to generate the answer
retrieval_context = [source_node.node.text for source_node in raw_response.source_nodes]
# Create a test case object to evaluate the model's performance
test_case = LLMTestCase(
input=input, # the input question
actual_output=actual_output, # the model's generated answer
expected_output=expected_output, # the ground truth answer
retrieval_context=retrieval_context # the supporting retrieved context
)If you’re building a Multimodal RAG application with LlamaIndex, be sure to structure your test cases using `MLLMTestCase` instead. This format includes support for images in inputs, outputs, and retrieved contexts.
Moreover, although we’re showing only one test case here, you’ll ideally want to generate many test cases using a variety of inputs to stress-test your LLM application at scale and ensure optimal performance. If you don’t have an evaluation dataset yet, DeepEval also offers a robust RAG Synthesizer to help you get started.
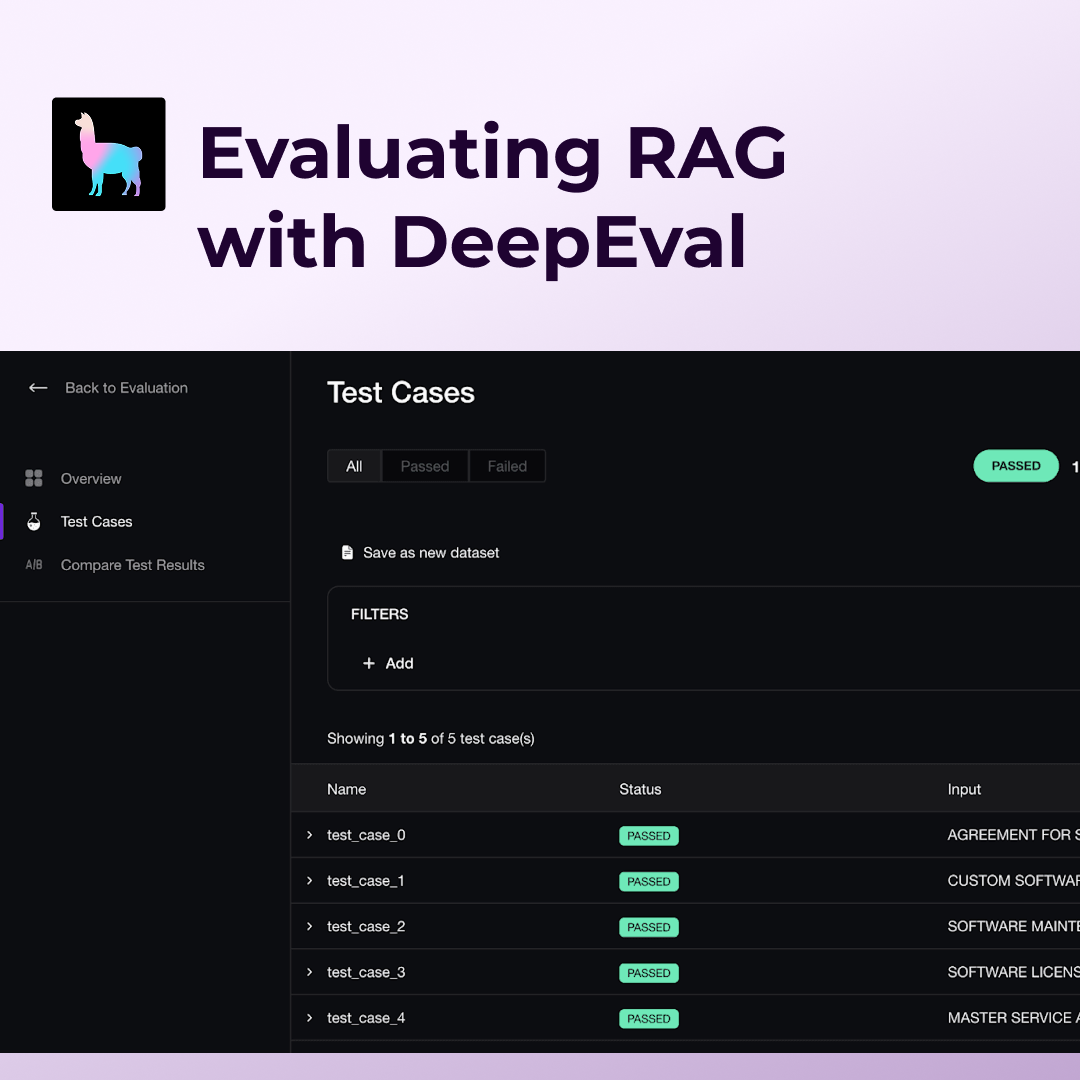
Step 4: Running Evaluations
With your test cases and metrics defined, running evaluations is as easy as passing everything into the evaluate function.
python
from deepeval import evaluate
...
evaluate([test_case], [answer_relevancy, faithfulness, contextual_precison])Let’s inspect the metric scores:
python
print(answer_relevancy.score) # 0.81
print(faithfulness.score) # 0.32
print(contextual_precison.score) # 0.86Step 5: Improving RAG
The low Faithfulness score indicates that the model isn't grounding its answers well in the retrieved context. In this case, you’ll want to experiment with different models to find one that offers better performance while remaining cost-effective. Fortunately in DeepEval, this can be as simple as running a loop like the one below:
python
for model in ["gpt-3.5-turbo", "gpt-4o", "o1"]:
# Building RAG from different models
Settings.llm = OpenAI(model)
documents = SimpleWebPageReader(html_to_text=True).load_data(
["https://www.llamaindex.ai/"]
)
index = VectorStoreIndex.from_documents(documents)
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=10,
)
response_synthesizer = get_response_synthesizer()
rag_application = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
node_postprocessors=[SimilarityPostprocessor(similarity_cutoff=0.7)],
)
response = rag_application.query("What is LlamaIndex")
# Constructing the Test Case
actual_output = response.response
retrieval_context = [source_node.node.text for source_node in raw_response.source_nodes]
test_case = LLMTestCase(
input=input,
actual_output=actual_output,
expected_output=expected_output,
retrieval_context=retrieval_context
)
# Evaluation
evaluate([test_case], [answer_relevancy, faithfulness, contextual_precision])You’ll want to repeat this process for all the hyperparameters you wish to optimize—whether that’s topK, the prompt template, reranker model, embedding model, or others.
Furthermore, in addition to standard RAG metrics, you may find custom metrics like G-Eval or DAG especially helpful. These are particularly useful for domain-specific RAG use cases where you need to define custom criteria such as coherence, verbosity, or correctness, for instance.
Scaling Evaluations
DeepEval is a powerful open-source tool for evaluating your RAG models locally.
For deeper analysis and centralized results, Confident AI (DeepEval Cloud) takes things further—bringing your evaluations to the cloud and unlocking advanced experimentation with robust analysis tools.
With Confident AI, you can:
- Easily curate and manage your evaluation datasets.
- Run local evaluations using DeepEval metrics while seamlessly syncing datasets from Confident AI.
- View and share comprehensive reports to compare prompts, models, and iterate on your LLM application.