RAG has come a long way since the days of naive chunk retrieval; now agentic strategies are table stakes.
Nowadays, an AI engineer has to be aware of a plethora of techniques and terminology that encompass the data-retrieval aspects of agentic systems: hybrid search, CRAG, Self-RAG, HyDE, deep research, reranking, multi-modal embeddings, and RAPTOR just to name a few.
As we’ve built the Retrieval services in LlamaParse, we’ve chosen to abstract a few of these techniques into our API, only exposing a few top-level hyper-parameters for controlling these algorithms. In this blog post, we will showcase these various techniques, explaining how and when to use them. We will build upon these techniques one by one and end with a fully agentic retrieval system that can intelligently query multiple knowledge bases at once.
Starting with the basics
You can’t talk about RAG without talking about “naive top-k retrieval”. In this basic approach, document chunks are stored in a vector database, and query embeddings are matched with the k most similar chunk embeddings.
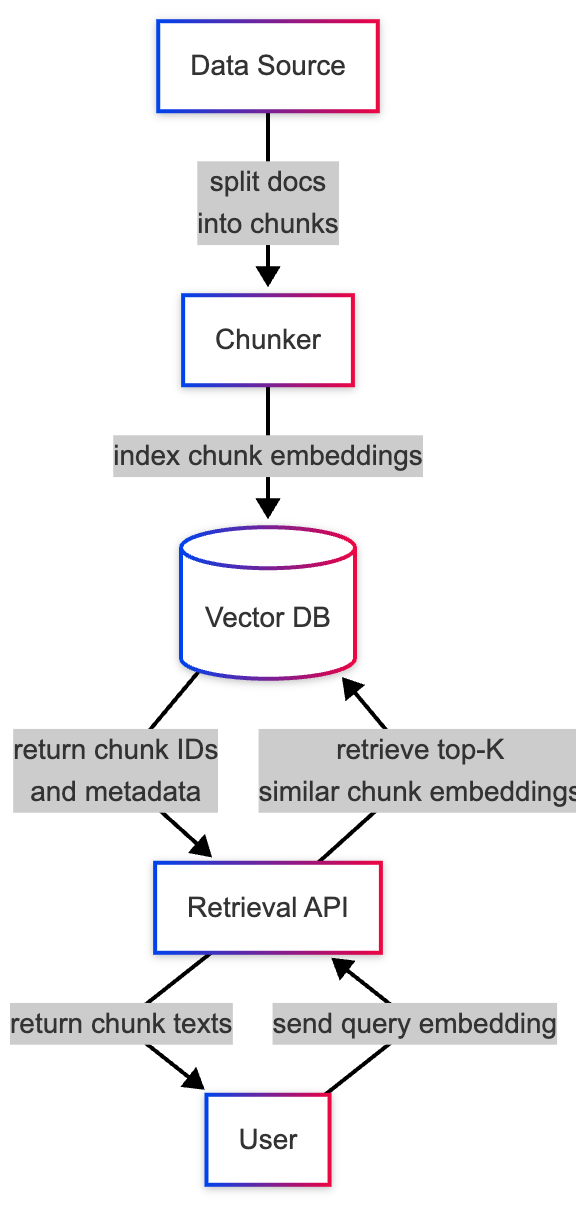
Here’s a basic code snippet to index a simple folder of PDFs:
python
import os
from llama_index.indices.managed.llama_cloud import LlamaParseIndex
# ^ pip install llama-index-indices-managed-llama-cloud
financial_index = LlamaParseIndex.from_documents(
documents=[], # leave documents empty since we will be uploading the raw files
name="Financial Reports",
project_name=project_name,
)
financial_reports_directory = "./data/financial_reports"
for file_name in os.listdir(financial_reports_directory):
file_path = os.path.join(financial_reports_directory, file_name)
# Add each file to the slides index
financial_index.upload_file(file_path, wait_for_ingestion=False)
financial_index.wait_for_completion()Once this is indexing is completed, you can start retrieving these chunks with one more line:
python
query = "Where is Microsoft headquartered?"
nodes = financial_index.as_retriever().retrieve(query)
# or, if you've set up the Settings object, generate the full response here
response = financial_index.as_query_engine().query(query) Going slightly beyond this naive chunk retrieval mode, there are also two more modes if you want to retrieve the entire contents of relevant files:
-
files_via_metadata- use this mode when you want to handle queries where a specific filename or pathname is mentioned e.g. “What does the 2024_MSFT_10K.pdf file say about the financial outlook of MSFT?”. -
files_via_content- use this mode when you want to handle queries that are asking general questions about a topic but not a particular set of files e.g. “What is the financial outlook of MSFT?”.
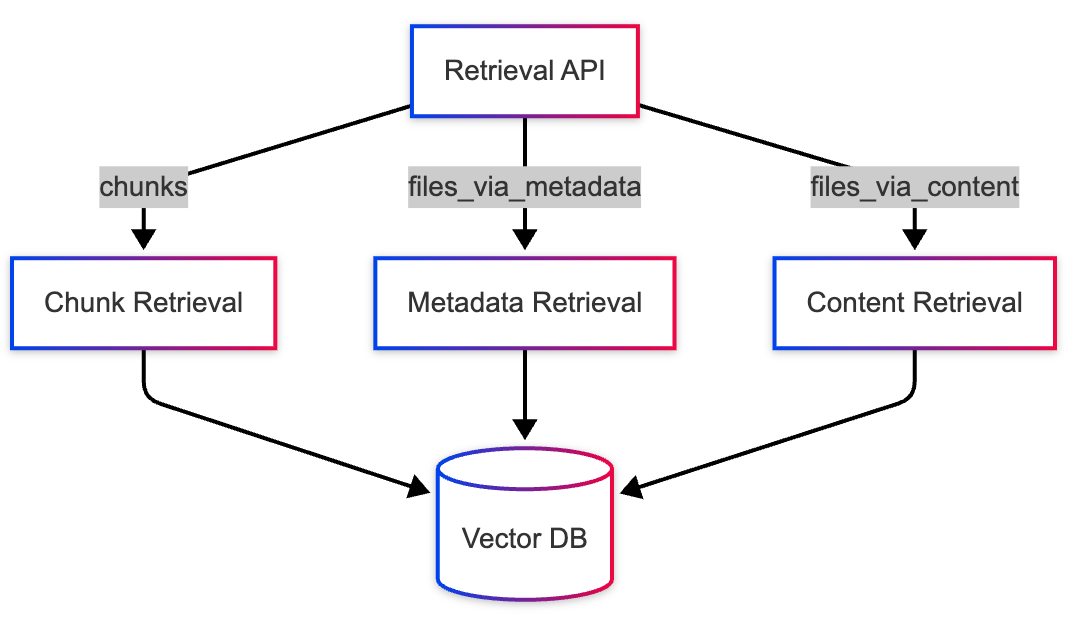
While chunk retrieval is the default mode, you can use one of the other retrieval modes via the retrieval_mode kwarg:
python
files_via_metadata_nodes = financial_index.as_retriever(retrieval_mode="files_via_metadata").retrieve(query)
files_via_content_nodes = financial_index.as_retriever(retrieval_mode="files_via_content").retrieve(query)Level up: Auto Mode
Now that we have an understanding how and when to use each of our retrieval modes, you’re now equipped with the power to answer any and all of types of questions about your knowledge base!
However, many applications will not know which type of question is being asked beforehand. Most of the time, these questions are being asked by your end user. You will need a way to know which retrieval mode would be most appropriate for the given query.
Enter the 4th retrieval mode - auto_routed mode! As the name suggests, this mode uses a lightweight agent to determine which of the other 3 retrieval modes to use for a given query.
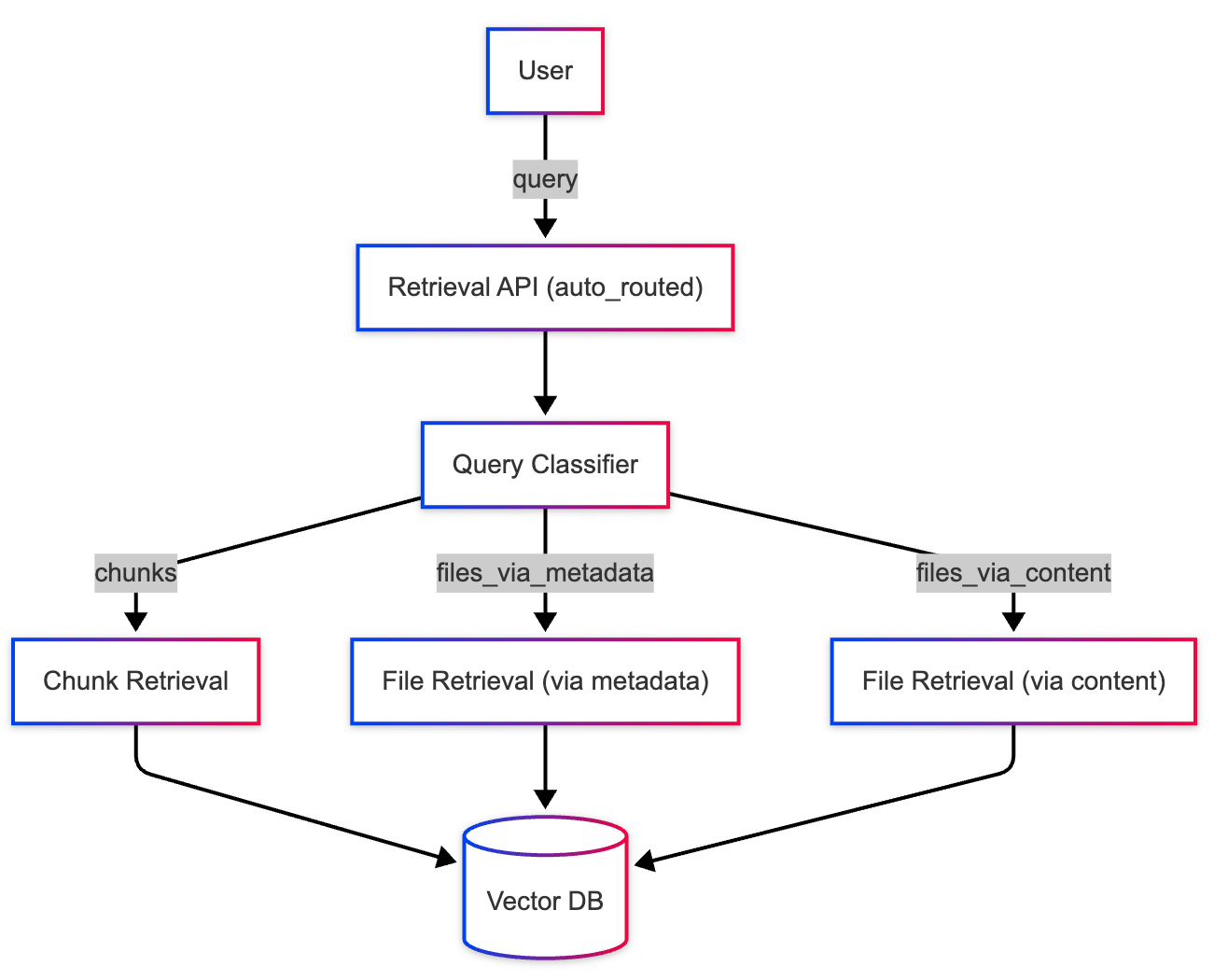
Using this mode is just as simple as using any of the other modes:
python
nodes = financial_index.as_retriever(retrieval_mode="auto_routed").retrieve("Where is Microsoft headquartered?")
# you can check which mode the query was routed to via the retrieval_mode metadata value
# this will print "chunks" since the input query is asking about specific information
print(nodes[0].metadata["retrieval_mode"])Expanding Beyond a single knowledge base
With the use of auto_routed mode, we have a lightweight agentic system that is capable of competently answering a variety of questions. However, this system is somewhat restricted in terms of its search space - it is only able to retrieve data that has been ingested in a single index.
If all of your documents are of the same format (e.g. they’re all just SEC 10K filings), it may be actually be appropriate for you to just ingest all your documents through a single index. The parsing and chunking configurations on that single index can be highly optimized to fit the formatting of this homogenous set of documents. However, your overall knowledge base will surely encompass a wide variety of file formats - SEC Filings, Meeting notes, Customer Service requests, etc. These other formats will necessitate the setup of separate indices whose parsing & chunking settings are optimized to each subset of documents.
Let’s say you have your SEC filings in the financial_index from the prior code snippets, and additionally have created a slides_index that has ingested .ppt PowerPoint files from a folder of slide shows.
python
import os
from llama_index.indices.managed.llama_cloud import LlamaParseIndex
# ^ pip install llama-index-indices-managed-llama-cloud
slides_index = LlamaParseIndex.from_documents(
documents=[], # leave documents empty since we will be uploading the raw files
name="Slides",
project_name=project_name,
)
# Add your slide files to the index
slides_directory = "./data/slides"
for file_name in os.listdir(slides_directory):
file_path = os.path.join(slides_directory, file_name)
# Add each file to the slides index
slides_index.upload_file(file_path, wait_for_ingestion=False) Your application may now have users asking questions about the SEC Filings you’ve ingested in financial_index & the meeting slide shows you’ve ingested in slides_index .
This is where our Composite Retrieval APIs shine! They provide a single Retrieval API to retrieve relevant content from many indices - not just one. The Composite Retrieval API exposes a lightweight agent layer to clients to allow them to specify a name & description for each sub-index. These parameters can help you control how the agent decides to route a question between the various indices you’ve added to your composite retriever.
python
from llama_cloud import CompositeRetrievalMode
from llama_index.indices.managed.llama_cloud import LlamaParseCompositeRetriever
composite_retriever = LlamaParseCompositeRetriever(
name="My App Retriever",
project_name=project_name,
# If a Retriever named "My App Retriever" doesn't already exist, one will be created
create_if_not_exists=True,
# CompositeRetrievalMode.ROUTED will query route the query to a subset of indices
mode=CompositeRetrievalMode.ROUTED,
# return the top 5 results from all queried indices
rerank_top_n=5,
)
# Add the above indices to the composite retriever
# Carefully craft the description as this is used internally to route a query to an attached sub-index when CompositeRetrievalMode.ROUTING is used
composite_retriever.add_index(
slides_index,
description="Information source for slide shows presented during team meetings",
)
composite_retriever.add_index(
financial_index,
description="Information source for company financial reports",
)
# Start querying across both of these indices at once
nodes = retriever.retrieve("What was the key feature of the highest revenue product in 2024 Q4?")Piecing Together a Knowledge Agent
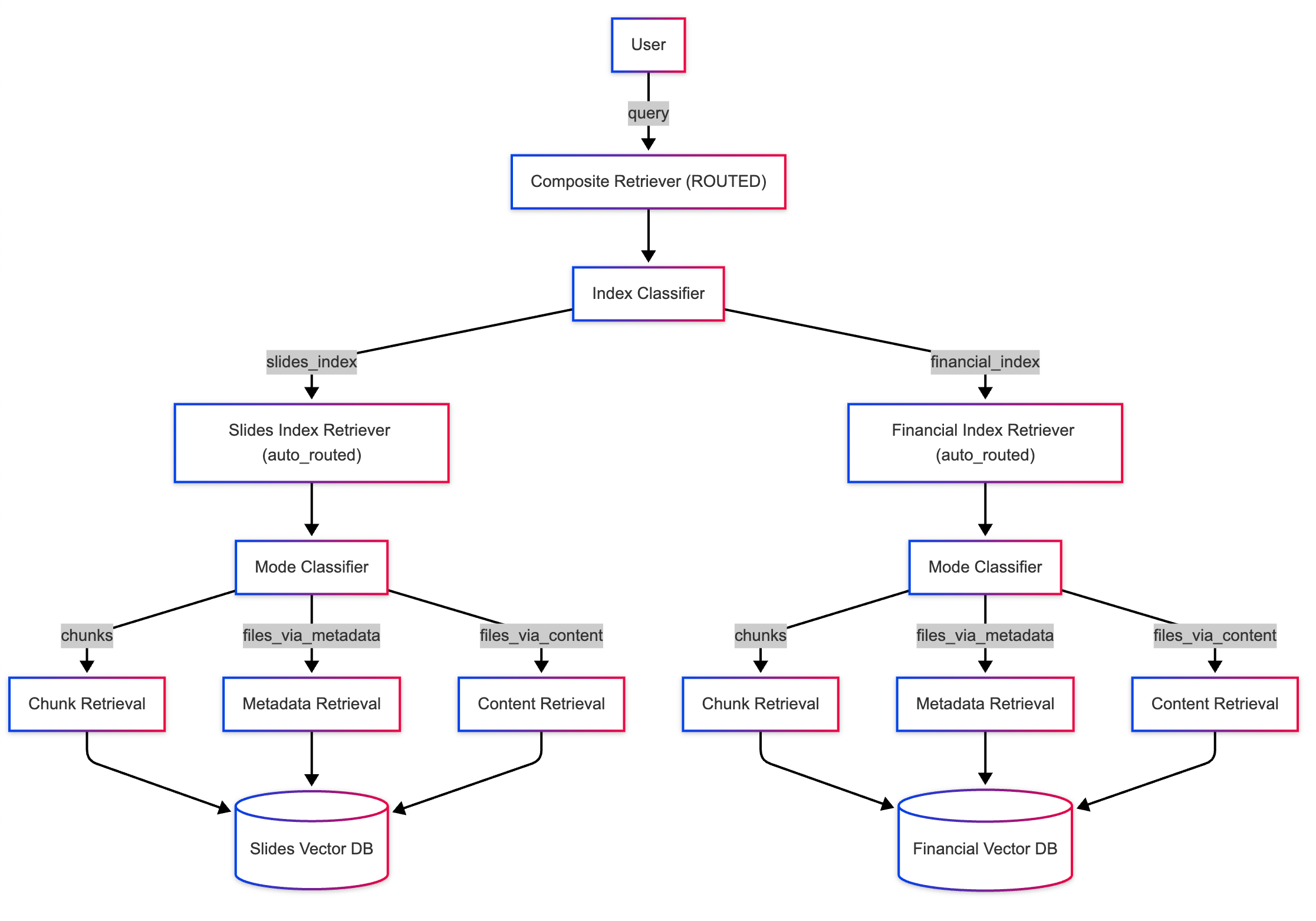
Now that we know how to use agents for both individual and multi-index level, we can put together a single system that does agentic retrieval at every step of retrieval! Doing so will enable the use of an LLM to optimize every layer of our search path.
The system works like this:
- At the top layer, the composite retriever uses LLM-based classification to decide which sub-index (or indices) are relevant for the given query.
- At the sub-index level, the
auto_routedretrieval mode determines the most appropriate retrieval method (e.g.,chunk,files_via_metadata, orfiles_via_content) for the query.
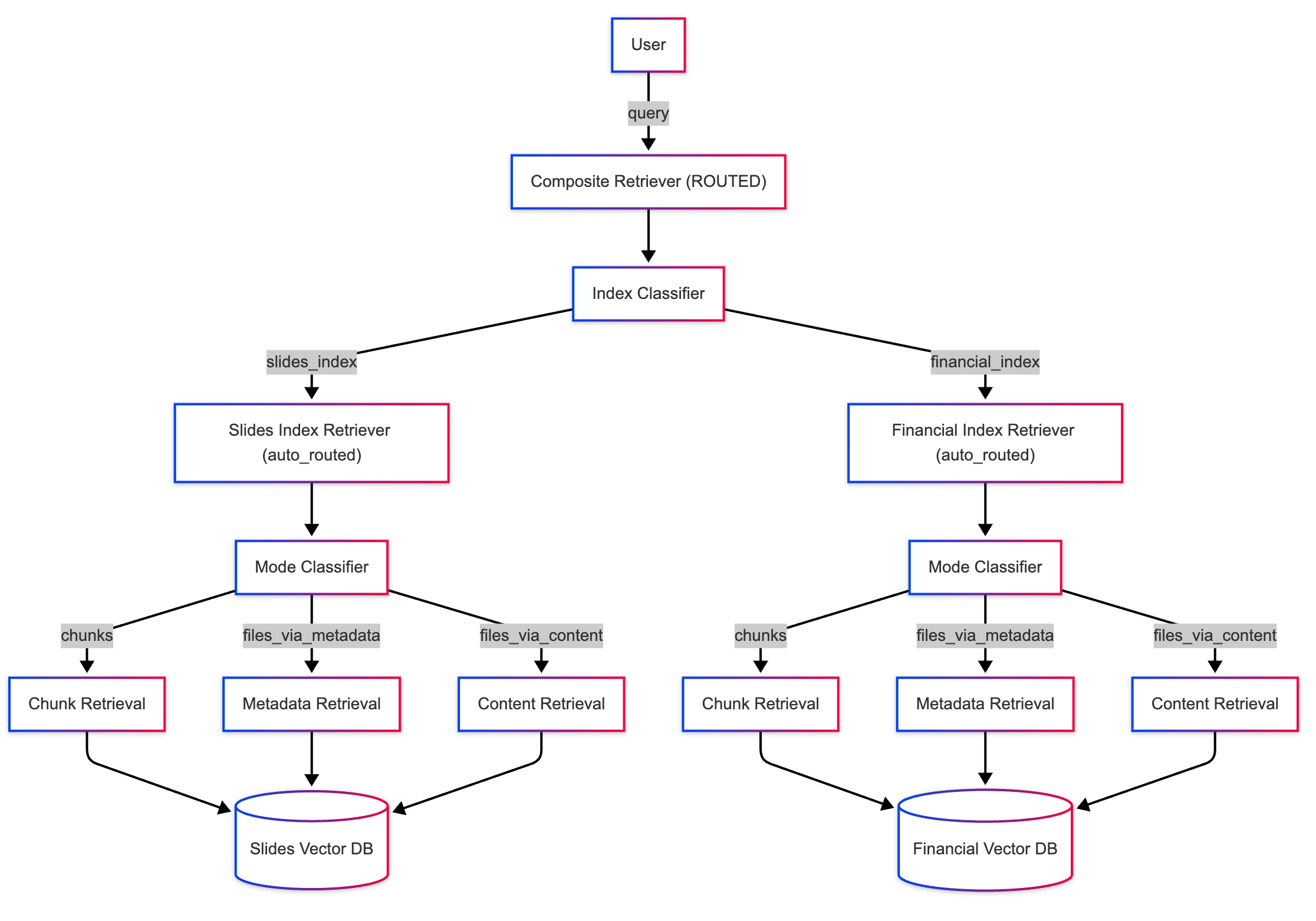
Here’s the code implementation:
python
from llama_cloud import CompositeRetrievalMode
from llama_index.indices.managed.llama_cloud import LlamaParseCompositeRetriever
# Create a composite retriever
composite_retriever = LlamaParseCompositeRetriever(
name="Knowledge Agent",
project_name=project_name,
create_if_not_exists=True,
mode=CompositeRetrievalMode.ROUTED, # Use routed mode for intelligent index selection
rerank_top_n=5, # Rerank and return the top 5 results
)
# Add sub-indices with detailed descriptions
composite_retriever.add_index(
financial_index,
description="Detailed financial reports, including SEC filings and revenue analysis",
)
composite_retriever.add_index(
slides_index,
description="Slide shows from team meetings, covering product updates and project insights",
)
# Query the composite retriever
query = "What does the Q4 2024 financial report say about revenue growth?"
nodes = composite_retriever.retrieve(query)
# Print the retrieval mode used for the query and the results
for node in nodes:
print(f"Retrieved from: {node.metadata['retrieval_mode']} - {node.text}")This setup ensures that retrieval decisions are intelligently routed at each layer, using LLM-based classification to handle complex queries across multiple indices and retrieval modes. The result is a fully agentic retrieval system capable of adapting dynamically to diverse user queries.
Naive RAG is dead, agentic retrieval is the future
Agents have become an essential part of modern applications. For these agents to operate effectively and autonomously, they need precise and relevant context at their fingertips. This is why sophisticated data retrieval is crucial for any agent-based system. LlamaParse serves as the backbone for these intelligent systems, providing reliable, accurate context when and where agents need it most.
What’s next? You can learn more about LlamaParse or sign up today and get started with 10,000 credits for free!