co-authored with Logan Markewich
For any agentic application that needs to retain basic information about past conversations, about its users, their past interactions and so on, memory is unsurprisingly a core component. So, as part of our latest round of improvements to LlamaIndex, we’ve introduced a new and improved Memory component.
In this article, we will walk through some of the core features of the new LlamaIndex memory component, and how you can start using it in your own agentic applications. First, we’ll look into the most basic implementation of memory, where we simply store chat message history. Then, we’ll also look into more advanced implementations with our latest additions of long-term memory blocks.
When to Use Memory
Not all AI applications need a memory implementation. A lot of agentic applications we see today don’t necessarily rely on chat history, or persistent information about their users. For example, our very own LlamaExtract is an agentic document extraction application, that uses LLMs to extract structured information from complex files. It doesn’t rely on retaining any sort of memory while doing so.
But, if the essence of an application relies on persistent information that you’d rather not repeat (someone’s name and age for example), and/or any form of conversation flow (so virtually any application with a chat interface), memory quickly becomes quite a crucial component.
Think of this simple (and annoying) chat flow where no form of memory has been implemented:
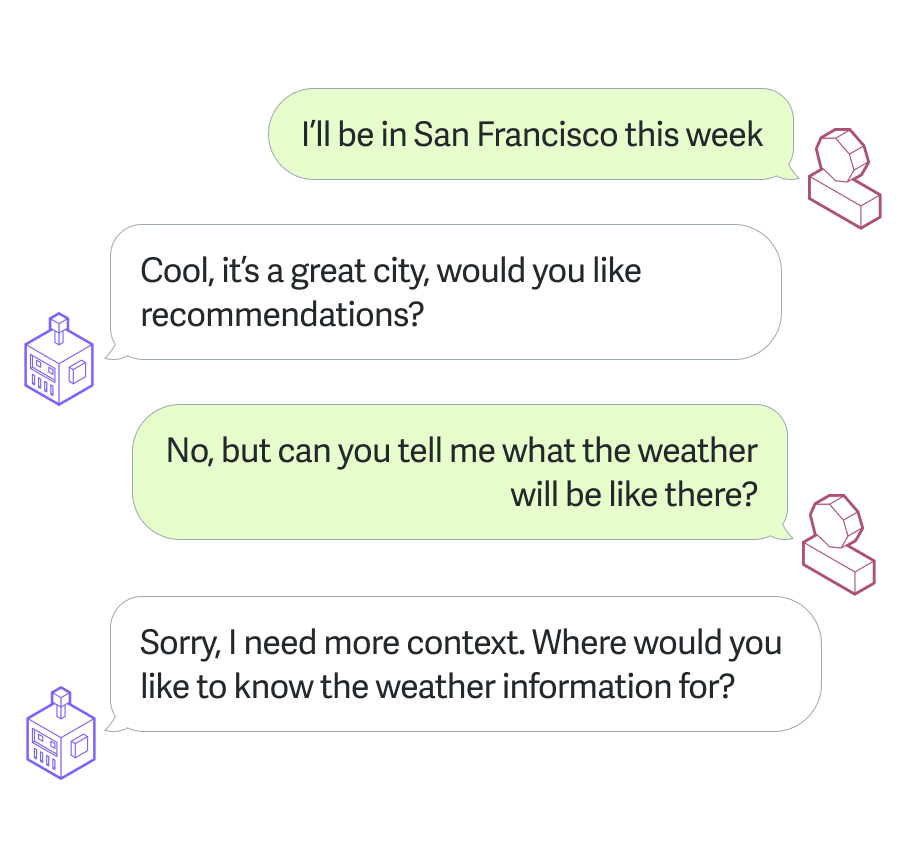
Notice how by the time I get to my second question, the agent is not able to provide me with any answers. The simple reason is that it has no context as to what ‘there’ is in the sentence ‘Can you tell me what the weather is like there?’.
This can be solved with a super simple step where we store chat message history, and send that to the LLM as context. That’s exactly how the most basic form of the LlamaIndex Memory starts:
The Basic Usage of Memory
In the most simple form, the LlamaIndex Memory will store any number of chat messages that fit into a given token limit, into a SQL database, which defaults to an in-memory SQLite database. In short, this memory will be able to store chat messages, up to a limit. Once that limit is reached (depending on how the memory is configured), the oldest messages in chat history will either get discarded, or flushed to long-term memory.
So, in its most basic form, the LlamaIndex Memory component allows you to build agentic workflows that are able to retain past conversations. You can store chat history into this memory either by initializing an agent with memory:
python
from llama_index.core.agent.workflow import FunctionAgent
from llama_index.core.memory import Memory
memory = Memory.from_defaults(session_id="my_session", token_limit=40000)
agent = FunctionAgent(llm=llm, tools=tools)
response = await agent.run("<question that invokes tool>", memory=memory)
Or, by using memory.put_messages() to add specific chat messages into memory:
python
memory = Memory.from_defaults(session_id="my_session",
token_limit=40000)
memory.put_messages(
[
ChatMessage(role="user", content="Hello, world!"),
ChatMessage(role="assistant", content="Hello, world to you too!"),
]
)
chat_history = memory.get()
Long-Term Memory Blocks
For some use-cases, the simple chat history implementation above might be enough. But for others, it makes sense to implement something a bit more advanced. We introduce 3 new “memory blocks” that act as long-term memory:
- Static memory block: which keeps track of static, non-changing information
- Fact extraction memory block: that populates a list of facts extracted from the conversation
- Vector memory block: which allows us to make use of classic embedding generation vector search as a way to both store chat history and fetch relevant parts of old conversations.
A memory component can be initialized with any number of these long-term memory blocks. Then, every time we reach the token limit for short-term memory, it will write the relevant information to these long-term memory blocks. To add long-term memory blocks we initialize memory with memory_blocks :
python
blocks = [<list of long-term memory blocks>]
memory = Memory.from_defaults(
session_id="my_session",
memory_blocks=blocks,
insert_method="system")Let’s see in more detail how we can initialize each block.
Static Information as long-term memory
Imagine information that might be relevant to your agentic application that is less likely to change over time. For example, your name, where you live, where you work etc. The StaticMemoryBlock allows you to provide this information as added context for your agent:
python
from llama_index.core.memory import StaticMemoryBlock
static_info_block = StaticMemoryBlock(
name="core_info",
static_content="My name is Tuana, and I live in Amsterdam. I work at LlamaIndex.",
priority=0
)You may think that the information here are facts, so are more appropriate for the fact extraction block. The main difference is that the fact extraction block is in itself an LLM powered extraction system, that is designed to extract facts as the conversation is happening.
Facts as long-term memory
My personal favorite. The FactExtractionMemoryBlock is a unique long-term memory block that is initialized with a default prompt (which you can override), that instructs an LLM to extract a list of facts from ongoing conversations. To initialize this block:
python
from llama_index.core.memory import FactExtractionMemoryBlock
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-4o-mini")
facts_block = FactExtractionMemoryBlock(
name="extracted_info",
llm=llm,
max_facts=50,
priority=1
)
Then, for example, after a long conversation with an agent where I provide some information about myself, we may get the following:
python
memory.memory_blocks[1].facts
# ['User is 29 years old.', 'User has a sister.']Vector search as long-term memory
Finally, we also have the VectorMemoryBlock which has to be initialized with a vector store like Weaviate, Qdrant or similar. The idea here is simple: once we reach the token limit for short-term memory, the memory component will write all the chat messages that have occurred to the vector store we initialized this block with. Once we do that, any ongoing conversations, where appropriate, can fetch relevant conversations from history and use that as context before replying to the user.
python
from llama_index.core.memory import VectorMemoryBlock
vector_block = VectorMemoryBlock(
name="vector_memory",
# required: pass in a vector store like qdrant, chroma, weaviate, milvus, etc.
vector_store=vector_store,
priority=2,
embed_model=embed_model,
similarity_top_k=2,
)
Customizing Memory
On top of all of these, we are also making it possible for you to introduce your own memory blocks by extending the BaseMemoryBlock class. For example, below we define a memory block that counts the mention of a given name in the conversation:
python
from typing import Optional, List, Any
from llama_index.core.llms import ChatMessage
from llama_index.core.memory.memory import BaseMemoryBlock
class MentionCounter(BaseMemoryBlock[str]):
"""
A memory block that counts the number of times a user mentions a specific name.
"""
mention_name: str = "Logan"
mention_count: int = 0
async def _aget(self, messages: Optional[List[ChatMessage]] = None, **block_kwargs: Any) -> str:
return f"Logan was mentioned {self.mention_count} times."
async def _aput(self, messages: List[ChatMessage]) -> None:
for message in messages:
if self.mention_name in message.content:
self.mention_count += 1
async def atruncate(self, content: str, tokens_to_truncate: int) -> Optional[str]:
return ""
Future Improvements
We would love for you to try out these latest improvements to the memory component for agents. If you do, please let us know how you got on in our community Discord server.
But, that being said, we see a few improvements coming for this component. For example, the current implementation only allows you to make use of memory as part of the backend of an agent. We’d love to provide the option of using memory as one of the suite of tools for a tool calling agent.
Additionally, we currently only support SQL databases (including remote databases which you can configure). But, we would also like to add support for NoSQL databases like MongoDB, Redis and so on.
Finally, we can imagine plenty of scenarios where the FactExtractionMemoryBlock might benefit from structured outputs. This would allow us to initialize the block with a predefined set of fields (facts) that the agent will fill in along the way.
To get started and learn more about how to build agents with both short-term and long-term memory: