2025 continues to be the year of specialized agents. At LlamaIndex we’ve been building specialized agents around document parsing and extraction over the past year, with a primary focus on unstructured formats like PDFs, Word, and Powerpoint. Today we’re thrilled to announce one of our most requested enterprise features, in private preview mode - a production-ready Excel agent that allows for complex spreadsheet automation.
Manual Spreadsheet Processing
Most organizations have thousands of spreadsheet files containing critical business data. Workflows today are very manual and mundane. Some examples we have heard from our customers:
Audit Firms: Auditors at Big 4 and other firms typically import hundreds of client trial-balance or general-ledger files, manually aligning them to their firm's standard format before running analytics. While tools like Alteryx automate some steps, auditors still lose 5–10 hours per week simply lifting numbers out of ERP exports.
Tax Teams: Analysts doing income tax provisions need to pull ERP extracts, map to tax lines, book permanent/temporary differences and true up. This translates to processing ~100 spreadsheet files per quarter per client, with each client taking 5-10 hours to map and reconcile.
Insurance Carriers: For bordereaux ingestion, managing agents send loss & premium bordereaux in every imaginable spreadsheet template. Volumes routinely hit tens of thousands of rows per file, dozens of files per month. Carriers need to transform each one into their standard layout, and regulatory reporting makes clean, auditable outputs a "must-have."
Corporate finance - Excel normalization problems are very common for corporate finance teams. Budget and forecast consolidations, quarter end close, Cash flow forecasting all entail very large volumes of excel files and normalizing them into a standard format.
Why Spreadsheets Needed a Rethink
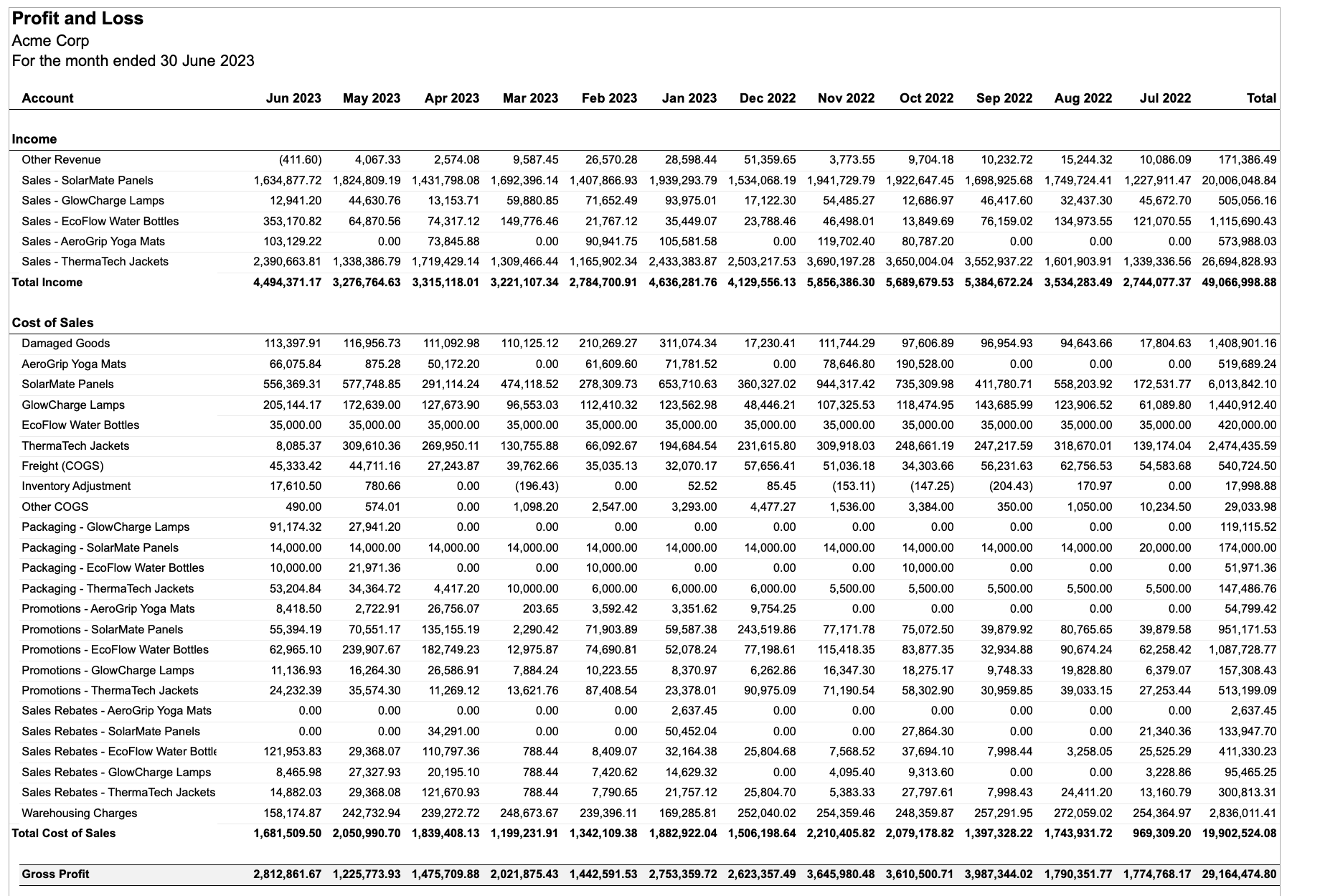
Spreadsheets (in the form of Excel, Google Sheets, and more) represent one of the most challenging document types for AI systems. Unlike clean CSV files or structured databases, spreadsheets are designed for human consumption, not machine readability:
- Visual structure matters: Headers span multiple lines, data relationships are implied through positioning and formatting
- Context lives everywhere: Critical information is embedded in cell formatting, colors, merged cells, and whitespace
- Tables aren't just data: Complex financial models, pivot tables, and nested calculations require semantic understanding
Traditional approaches like text-to-CSV conversion, vector retrieval, or simply dumping cell contents into prompts fail catastrophically. It's like handing someone shredded documents and asking them to understand a complex financial report.
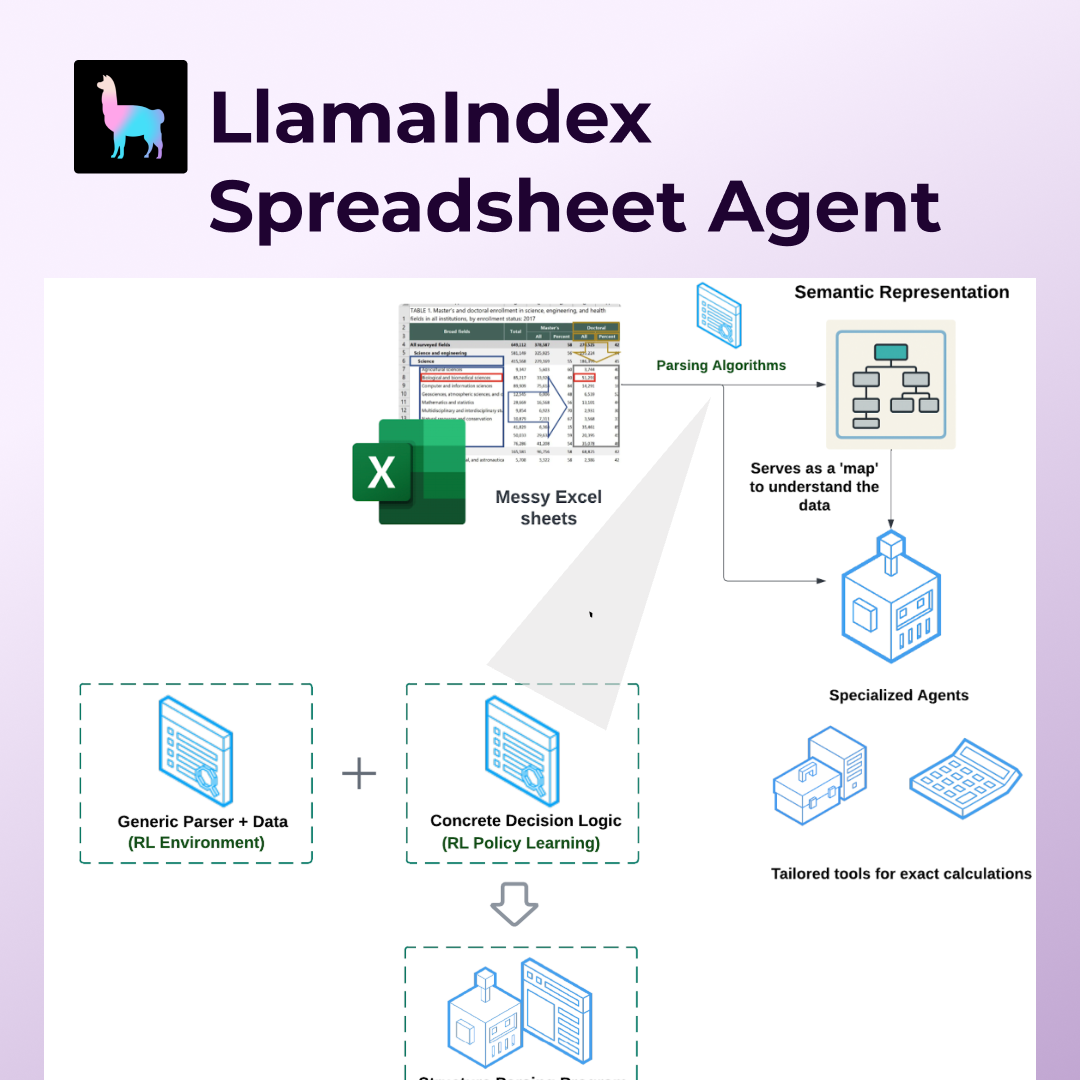
Our Solution: Parse First, Reason Second
Rather than trying to force spreadsheet understanding into existing methodologies, we built a completely new architecture that treats a spreadsheet as a visual document requiring semantic understanding.
Two Core Capabilities
Data Transformation
Convert messy spreadsheets into normalized 2D formats while preserving semantic meaning. Our agent understands complex layouts, handles merged cells intelligently, and maintains data relationships during transformation.
Direct Q&A Over Spreadsheets
Ask natural language questions directly over spreadsheet content. The agent reasons through the sheet structure, performs precise calculations using specialized tools, and provides answers with full traceability back to source cells.
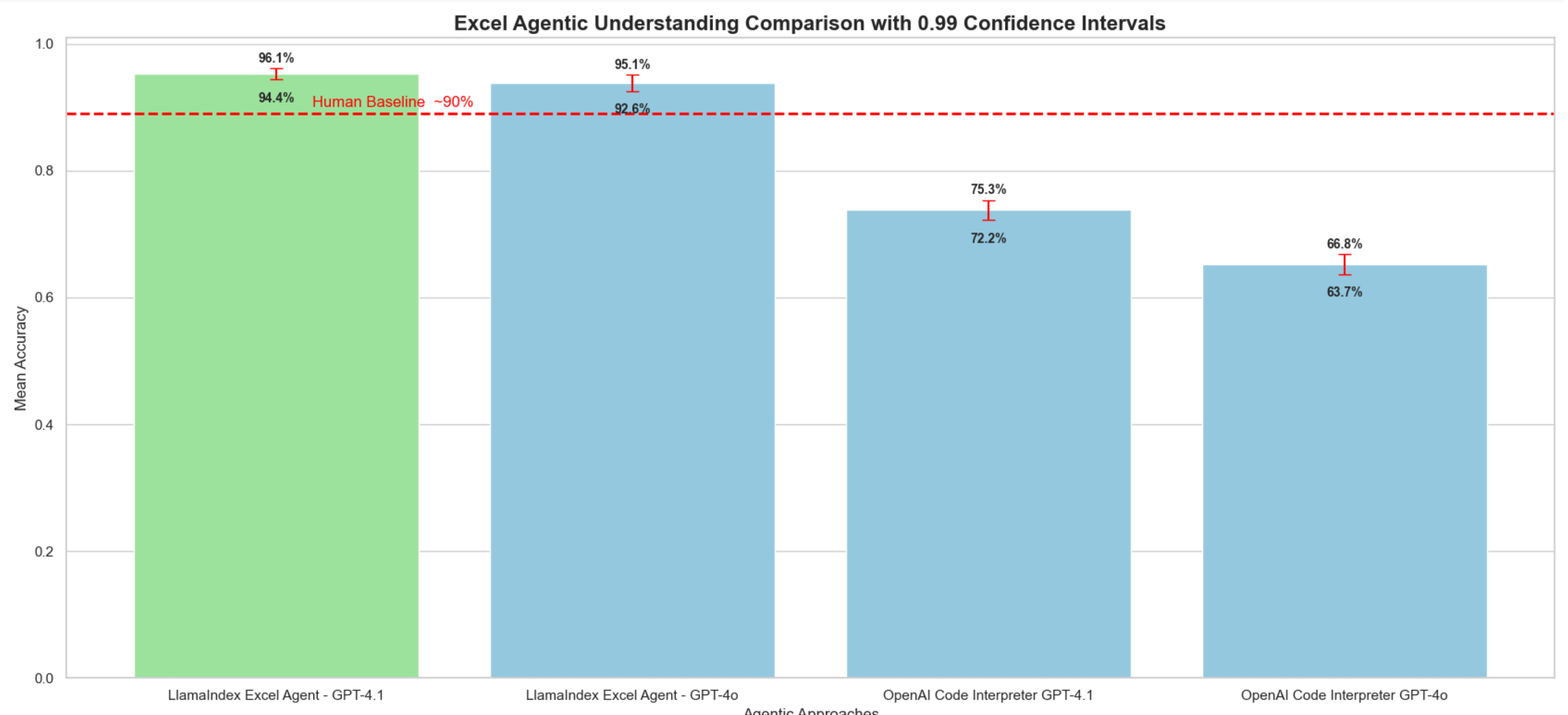
State-of-the-Art Results
Our approach delivers breakthrough performance over a private dataset of complex financial spreadsheets.
- LlamaIndex Excel Agent (GPT-4.1): 96.1% accuracy
- LlamaIndex Excel Agent (GPT-4o): 95.1% accuracy
- OpenAI Code Interpreter (GPT-4.1): 75.3% accuracy
- OpenAI Code Interpreter (GPT-4o): 66.8% accuracy
- Human Baseline: ~90% accuracy
While other approaches rely on general-purpose tools like code generation or text extraction, our representation-based spreadsheet agent takes a fundamentally different path. By parsing the spreadsheet into a semantic structure and reasoning over it with tool-augmented agents, we achieve significantly higher accuracy and consistency — especially on complex, real-world financial files. This architecture enables state-of-the-art performance, far surpassing alternatives in both precision and robustness.
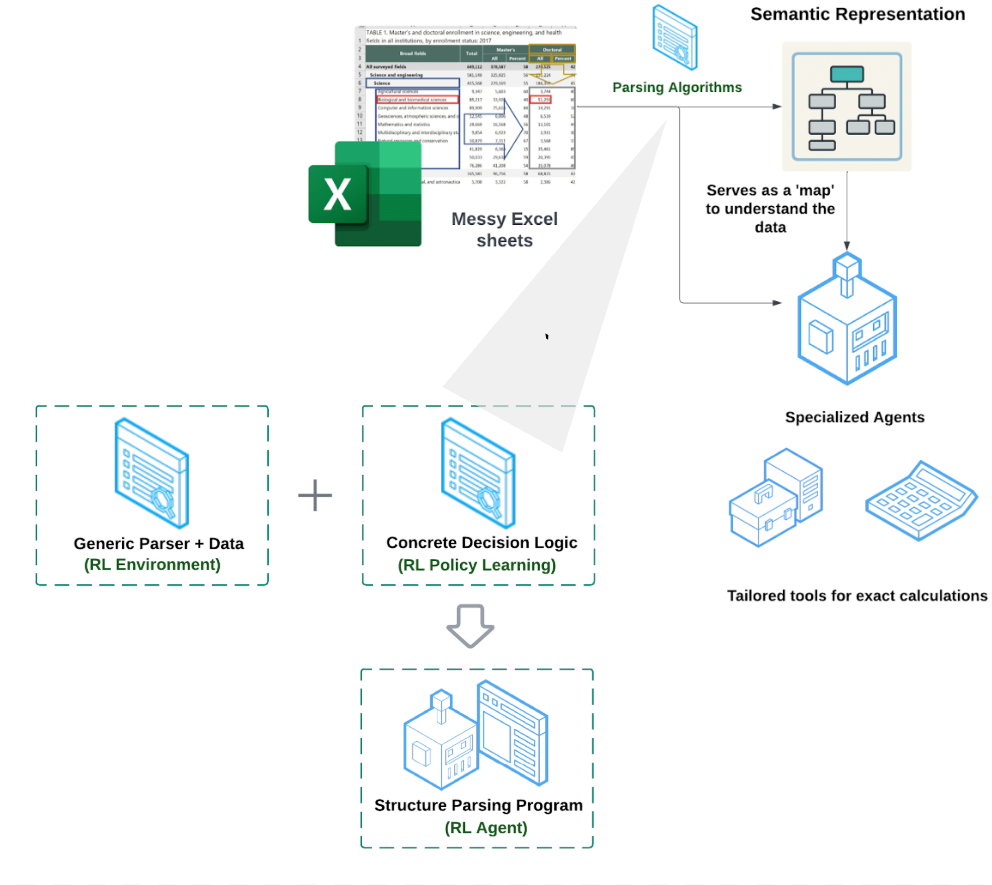
Technical Architecture
We built a completely new architecture that combines RL-based structure understanding with specialized agentic tools:
1. Semantic Structure Parsing
Our system first builds a semantic map of each sheet using reinforcement learning to understand the implicit relationships between data elements. This creates a structured representation that serves as a "map" for downstream reasoning.
2. Specialized Sub-Agents + Tools
Rather than generic LLM reasoning, we deploy specialized agents equipped with tailored tools for arithmetic operations and data aggregation - ensuring precision in calculations and transformations.
3. Reinforcement Learning for Hard Problems
We turned spreadsheet structure parsing into a reinforcement learning problem, training our system on real-world Excel files to learn optimal parsing strategies rather than relying on brittle conditional logic.
Getting Started
The spreadsheet agent is available in private preview - the core capabilities are there but we’re iterating on some general feedback before releasing it to the public.
If you’re interested in these capabilities, come talk to us.
In the meantime, if you’re interested in core PDF/Powerpoint/Word document processing capabilities, check out LlamaParse today.