LlamaIndex is an industry-leading set of frameworks for building generative AI agents, with its roots in the understanding that your results are only as good as your data. Getting that data from the huge number of places it can live, parsing it in all its many forms, indexing it, and accurately retrieving it are hard problems that we exist to solve. Our frameworks make it easy.
Our hosted platform, LlamaParse, exists to make things even easier: scaling up your LLM applications from prototypes to enterprise scale comes with a variety of challenges. As our customers have scaled to ever greater workloads, we’ve evolved to tackle them, and learned a lot of lessons along the way about how to develop RAG services, which then serve as the foundation on which our customers build agentic applications in our frameworks.
In this post, we want to share some of those lessons, to help others just starting out on their journey. Put another way: you’re going to run into these requirements eventually, so it’s better to find out about them early.
Noisy Neighbors
Many enterprise use cases today are centered on providing some type of context-aware assistant interface. While there are many form factors for this, today this still mostly takes the form of a chat app that you can upload files into to then ask questions about. For consumer applications like this, you’ll quickly find that some customers produce much heavier usage than others.
Let’s say your system is ingesting thousands of files per hour without breaking a sweat because you’ve built a robust and observable job orchestration system. However, you then take a look one level deeper and you see that of the 1000 files that were ingested in the past hour, about half of them were from a single user! Worse yet, because that user uploaded all their files at once, all the other users saw their file processing take 30 minutes! Your system was so busy churning through files for your single heavy user, it left behind your other users to starve. This is a core problem when building any multi-tenant SaaS application, and a particularly important one for enterprise RAG.
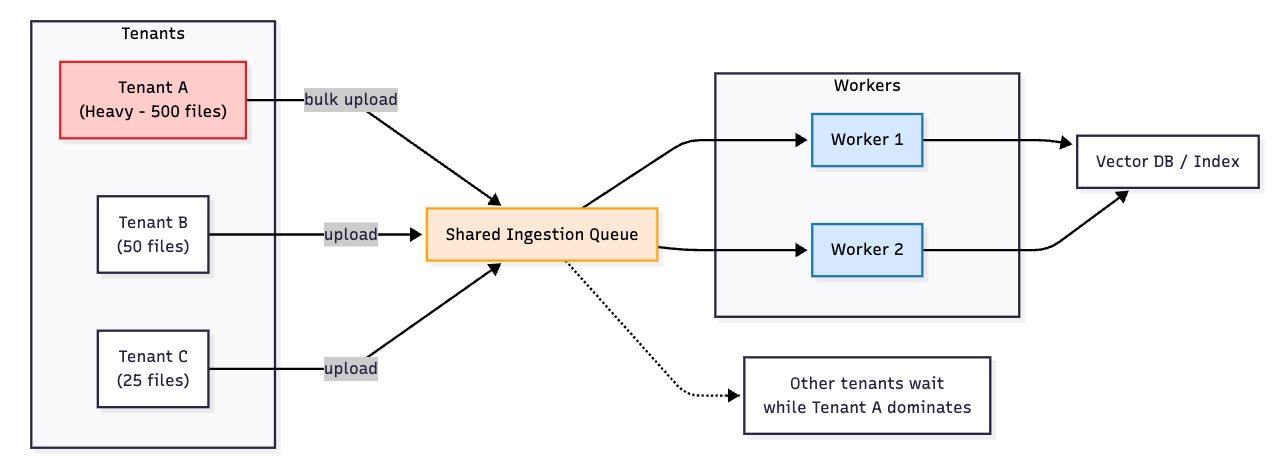
This starvation problem needs to be a top-of-mind concern when building any enterprise RAG system from scratch. Anyone building on the LlamaParse platform has the luxury of leaving these details up to our managed scheduling controls, so they can focus on their downstream product experience.
Maintaining Access Control
One of the most frequent customers for enterprises looking to build AI tools today are their own employees. Often, for these AI tools to be useful to an employee within a large organization, they need to have context from all kinds of documents produced within the organization.
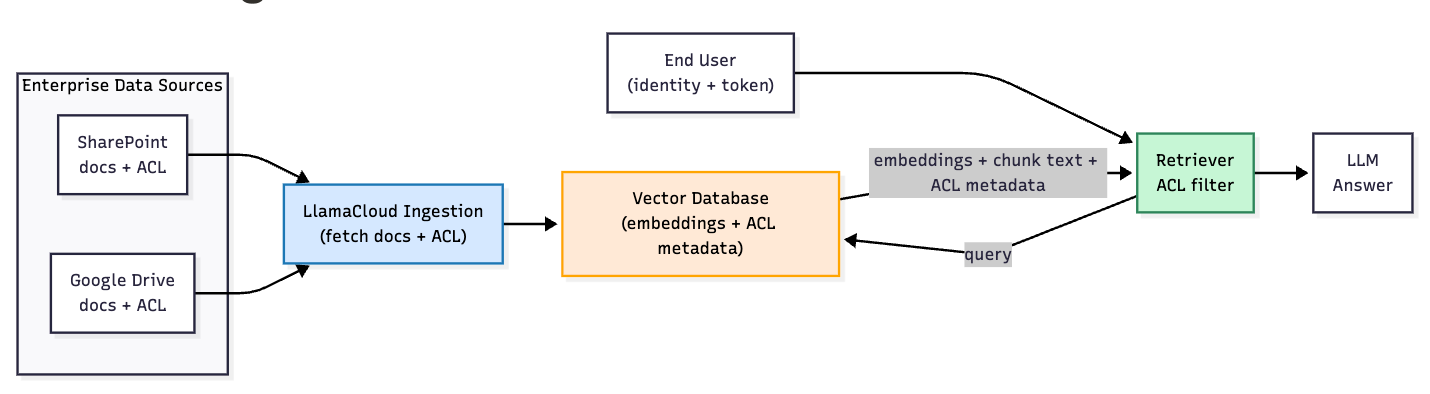
However, these employees often have different levels of access to different documents within the organization. This leads to a critical challenge in RAG: maintaining access controls when ingesting data. Your system must not only efficiently store and index documents, but also maintain a robust permissions model that respects the existing access control logic of your organization's various data sources.
Within LlamaParse, several of our data-source connectors have support for ingesting the permissions info for each file ingested from that data-source. This permissions info is ingested into the downstream vector database as metadata values. From there, retrieval requests against the vector database can be scoped to only embeddings from files the end-user has access to by attaching the right permissions-related metadata filters.
Document Parsing
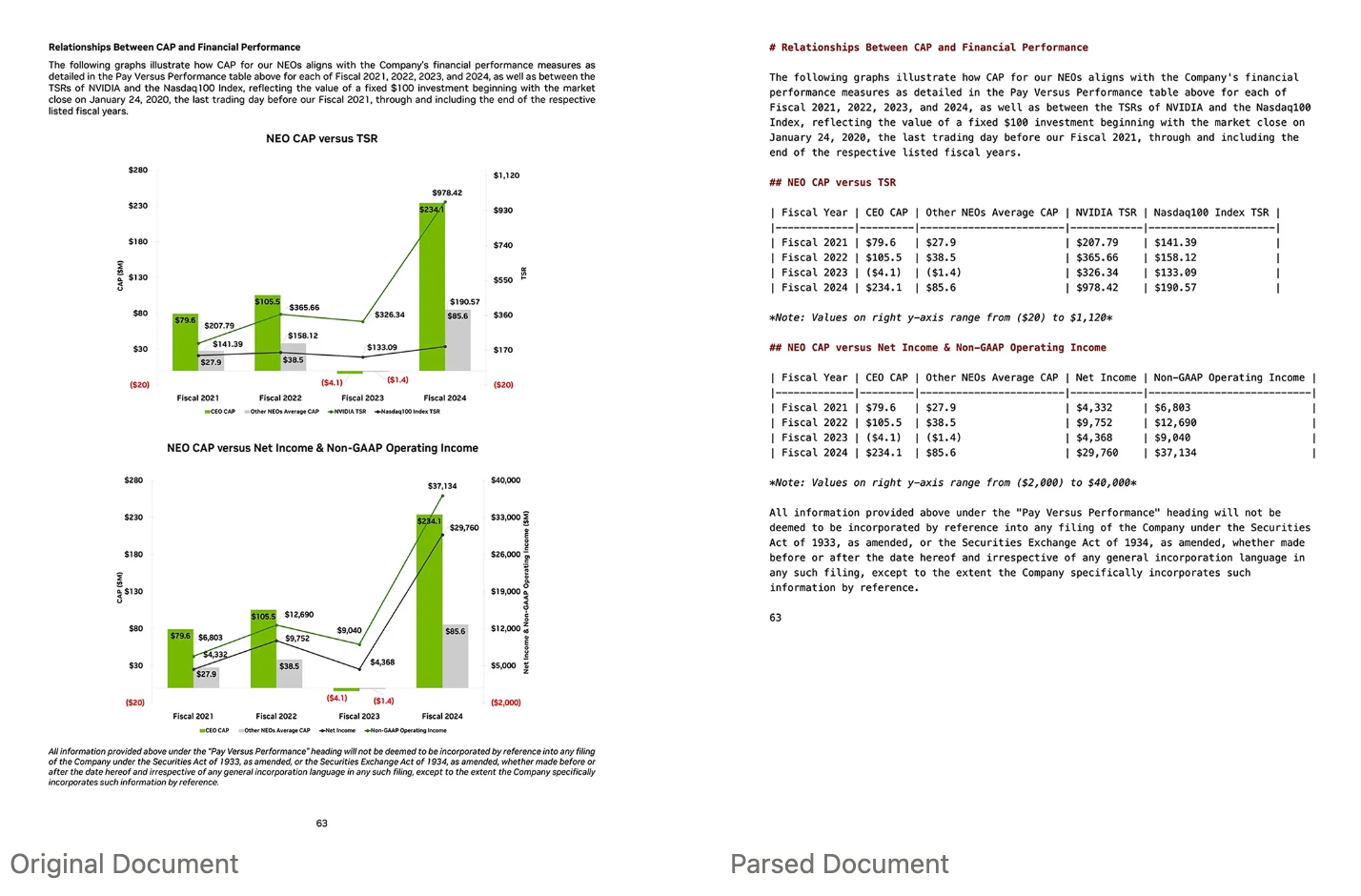
As you’ve probably heard from us before, document parsing is critical for enterprise RAG. Enterprise data spans diverse formats - complex PDFs, PowerPoints with charts, Word documents with rich formatting, Excel sheets with complex, multi-sheet layouts. The key challenge is converting these varied formats into standardized, LLM-ready text.
LlamaParse is our document parsing solution directly aimed at solving this problem, offering several benefits:
- Semantic structure preservation - LlamaParse preserves document hierarchy by maintaining headings, paragraphs, and lists with their semantic relationships intact
- Table extraction - Tables are converted to markdown format, preserving structure while remaining LLM-interpretable
- Image and Figure extraction - LlamaParse can identify and extract page screenshots and images embedded within docs, which can later be retrieved to incorporate multi-modal context for your application.
- Consistent markdown output - All documents, regardless of their original format, are converted to a standardized markdown representation that's optimized for LLM processing
LlamaParse is seamlessly integrated into LlamaParse indexes, making it easy to incorporate our best-in class document parser into your RAG ingestion pipeline.
Plan for Failures
Anyone with an inkling of knowledge around distributed systems knows that job failures are a fact of life. But every type of software system has its own idiosyncratic failure modes. What are the specific failure modes to watch out in enterprise RAG ingestion? There’s quite a few!
- Integrating with AI Services - Unless you’re planning to host GPU clusters yourself, you will likely need to integrate with 3rd party AI services like OpenAI, Anthropic, Bedrock etc. to use LLM and Embedding models hosted on their platforms. These services will often have rate limits, variable response times, and full-scale outages - all of which your code will need to be able to handle through custom retry logic.
- Data-source limitations - While some storage systems like S3 and Azure Blob have interfaces optimized for large data transfers, many others have significant limitations. Some paginated APIs slow down with higher page counts, while others face credential expiration during lengthy data loads. If you need to ingest data from these sources, it will require custom handling and dedicated developer attention.
- Checkpointing - just because your data ingestion process failed halfway through doesn’t mean you need to restart it from scratch! You will need to design a system that can save its progress incrementally and pick back up from it’s last saved state when things go wrong. Not only does LlamaParse do this internally, it also provides insight into this incremental progress through its UI and APIs!
Build for scale, or let LlamaParse do it for you
Often, the functional requirements for a new application can be deprioritized or reduced in scope. However, it’s often the non-functional requirements that are major dealbreakers. While many of these requirements may be generalizable to any Enterprise SaaS or ETL system, we think its important to portray how they will surface in the context of RAG ingestion.
Ignoring these lessons above will prevent your RAG application from seeing the light of day within your enterprise organization. LlamaParse handles these challenges so you can focus on building your core application instead of infrastructure.
You can learn more about LlamaParse or just sign up today and get started for free!