Although the principles behind the term ‘context engineering’ are not new, the wording is a useful abstraction that allows us to reason about the most pressing challenges when it comes to building effective AI agents. So let’s break it down. In this article, I want to cover three things: what we mean by context engineering, how it’s different from “prompt engineering”, and how you can use LlamaIndex and LlamaParse to design agentic systems that adhere to context engineering principles.
What is Context Engineering
AI agents require the relevant context for a task, to perform that task in a reasonable way. We’ve known this for a while, but given the speed and fresh nature of everything AI, we are continuously coming up with new abstractions that allow us to reason about best practices and new approaches in easy to understand terms.
Andrey Karpathy’s post about this is a great summary:
People associate prompts with short task descriptions you'd give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step.
While the term “prompt engineering” focused on the art of providing the right instructions to an LLM at the forefront, although these two terms may seem very similar, “context engineering” puts a lot more focus on filling the context window of an LLM with the most relevant information, wherever that information may come from.
You may ask “isn’t this just RAG? This seems a lot like focusing on retrieval”. And you’d be correct to ask that question. But the term context engineering allows us to think beyond the retrieval step and think about the context window as something that we have to carefully curate, taking into account its limitations as well: quite literally, the context window limit.
What Makes Up Context
Before writing this blog, we read “The New Skill in AI is Not Prompting, It’s Context Engineering”, by Philipp Schmid, where he does a great job of breaking down what makes up the context of an AI Agent or LLM. So, here’s what we narrow down as “context” based on both his list, and a few additions from our side:
- The system prompt/instruction: sets the scene for the agent about what sort of tasks we want it to perform
- The user input: can be anything from a question to a request for a task to be completed.
- Short term memory or chat history: provides the LLM context about the ongoing chat.
- Long-term memory: can be used to store and retrieve both long-term chat history or other relevant information.
- Information retrieved from a knowledge base: this could still be retrieval based on vector search over a database, but could also entail relevant information retrieved from any external knowledge base behind API calls, MCP tools or other sources.
- Tools and their definitions: provide additional context to the LLM as to what tools it has access to.
- Responses from tools: provide the responses from tool runs back to the LLM as additional context to work with.
- Structured Outputs: provide context on what kind of information we are after from the LLM. But can also go the other way in providing condensed, structured information as context for specific tasks.
- Global State/Context: especially relevant to agents built with LlamaIndex, allowing us to use workflow
Contextas a sort of scratchpad that we can store and retrieve global information across agent steps.
Some combination of the above make up the context for the underlying LLM in practically all agentic AI applications now. Which brings us to the main point: thinking about precisely which of the above should make up your agent context, and in what manner is exactly what context engineering calls for. So with that, let’s look at some examples of situations in which we might want to think about our context strategy, and how you may implement these with LlamaIndex and LlamaParse.
Techniques and Strategies to Consider for Context Engineering
A quick glance at the list above and you may already notice that there’s a lot that could make up our context. Which means we have 2 main challenges: selecting the right context, and making that context fit the context window. While I’m fully aware that this list could grow and grow, let’s look at a few architectural choices that will be top of mind when curating the right context for an agent:
Knowledge base or tool selection
When we think of RAG, we are mostly talking about AI applications that are designed to do question answering over a single knowledge base, often a vector store. But, for most agentic applications today, this is no longer the case. We now see applications that need to have access to multiple knowledge bases, maybe with the addition of tools that can either return more context or perform certain tasks.
Before we retrieve additional context from a knowledge base or tool though, the first context the LLM has is information about the available tools or knowledge bases in the first place. This is context that allows us to ensure that our agentic ai application is choosing the right resource.
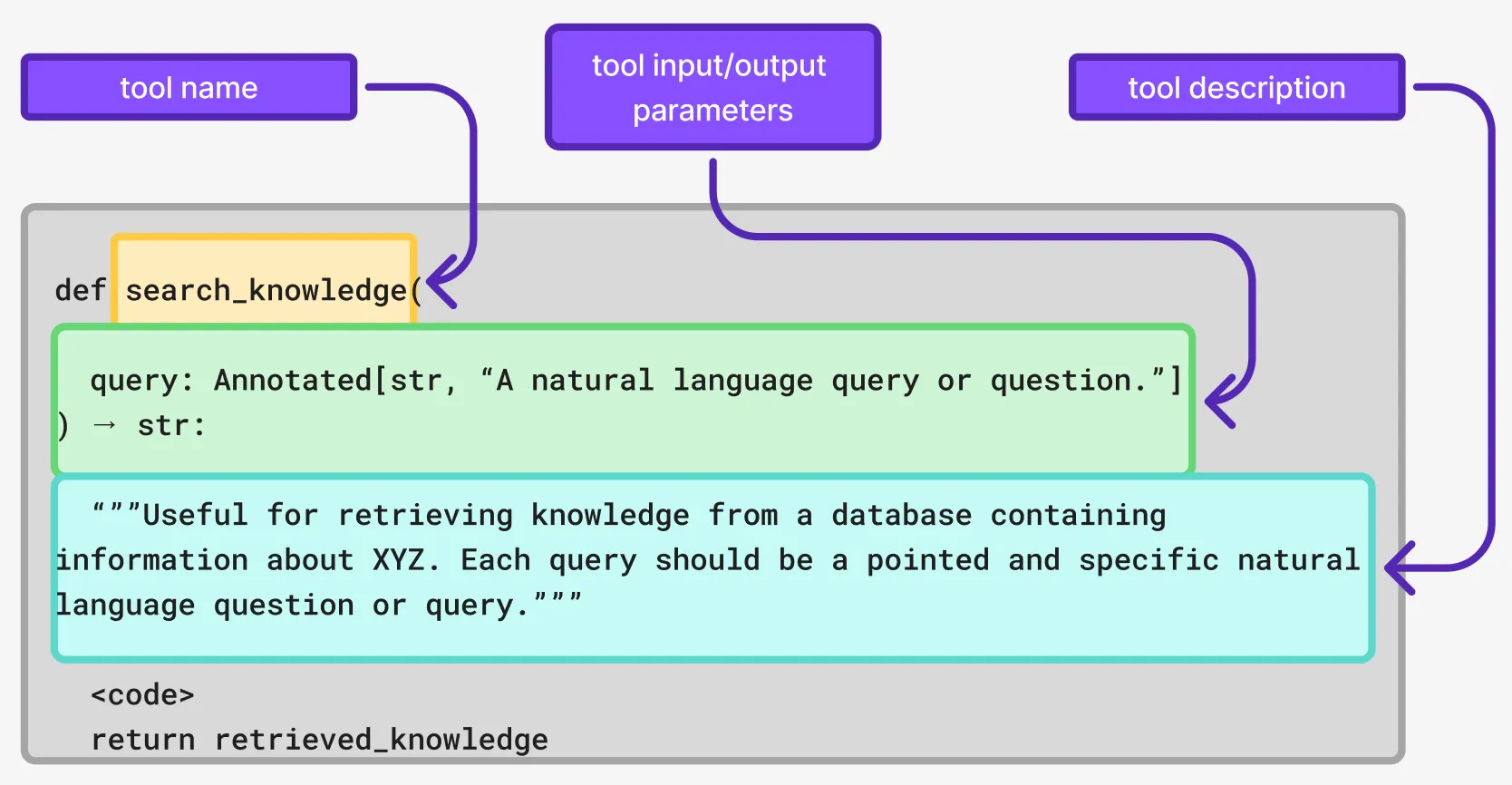
Context ordering or compression
Another important consideration when it comes to context engineering is the limitations we have when it comes to the context limit. We simply have a limited space to work with. This has lead to some implementations where we try to make the most out of that space by employing techniques such as context summarization where after a given retrieval step, we summarize the results before adding it to the LLM context.
In some other cases, it’s not only the content of the context that matters, but also the order in which it appears. Consider a use-case where we not only need to retrieve data, but the date of the information is also highly relevant. In that situation, incorporating a ranking step which allows the LLM to receive the most relevant information in terms of ordering can also be quite effective.
python
def search_knowledge(
query: Annotated[str, “A natural language query or question.”]
) → str:
"""Useful for retrieving knowledge from a database containing information about""" XYZ. Each query should be a pointed and specific natural language question or query.”””
nodes = retriever.retrieve(query)
sorted_and_filtered_nodes = sorted(
[item for item in data if datetime.strptime(item['date'], '%Y-%m-%d') > cutoff_date],
key=lambda x: datetime.strptime(x['date'], '%Y-%m-%d')
)
return "\\n----\\n".join([n.text for n in sorted_and_filtered_nodes])
Choices for Long-term memory storage and retrieval
If we have an application where we need ongoing conversations with an LLM, the history of that conversation becomes context in itself. In LlamaIndex, we’ve provided an array of long-term memory implementations for this exact reason, as well as providing a Base Memory Block that can be extended to implement any unique memory requirements you may have.
For example, some of the pre-built memory blocks we provide are:
-
VectorMemoryBlock: A memory block that stores and retrieves batches of chat messages from a vector database. -
FactExtractionMemoryBlock: A memory block that extracts facts from the chat history. -
StaticMemoryBlock: A memory block that stores a static piece of information.
With each iteration we have with an agent, if long-term memory is important to the use case, the agent will be retrieving additional context from it before deciding on the next best step. This makes deciding on what kind of long-term memory we need and just how much context it should return a pretty significant decision. In LlamaIndex, we’ve made it so that you can use any combination of the long-term memory blocks above.
Structured Information
A common mistake we see people make when creating agentic AI systems is often providing all the context when it simply isn’t required; it can potentially overcrowd the context limit when it’s not necessary.
Structured outputs have been one of my absolute favorite features introduced to LLMs in recent years for this reason. They can have a significant impact on providing the most relevant context to LLMs. And it goes both ways:
- The requested structure: this is a schema that we can provide an LLM, to ask for output that matches that schema.
- Structured data provided as additional context: which is a way we can provide relevant context to an LLM without overcrowding it with additional, unnecessary context.
LlamaExtract is a LlamaParse tool that allows you to make use of the structured output functionality of LLMs to extract the most relevant data from complex and long files and sources. Once extracted, these structured outputs can be used as condensed context for downstream agentic applications.
Workflow Engineering
While context engineering focuses on optimizing what information goes into each LLM call, workflow engineering takes a step back to ask: what sequence of LLM calls and non-LLM steps do we need to reliably complete this work? Ultimately this allows us to optimize the context as well. LlamaIndex Workflows provides an event-driven framework that lets you:
- Define explicit step sequences: Map out the exact progression of tasks needed to complete complex work
- Control context strategically: Decide precisely when to engage the LLM versus when to use deterministic logic or external tools
- Ensure reliability: Build in validation, error handling, and fallback mechanisms that simple agents can't provide
- Optimize for specific outcomes: Create specialized workflows that consistently deliver the results your business needs
From a context engineering perspective, workflows are crucial because they prevent context overload. Instead of cramming everything into a single LLM call and hoping for the best, you can break complex tasks into focused steps, each with its own optimized context window.
The strategic insight here is that every AI builder is ultimately building specialized workflows - whether they realize it or not. Document processing workflows, customer support workflows, coding workflows - these are the building blocks of practical AI applications.
Time to build
If this discussion and these techniques have inspired you to overhaul your own approach to agentic engineering, we encourage you to use LlamaIndex, both for our easy to use retrieval infrastructure but also our popular Workflows orchestration framework, which went 1.0 earlier this week, as well as our powerful enterprise tools like LlamaExtract and LlamaParse.