Agentic data extraction workflows do a great job at simplifying the task of extracting important and relevant information from complex data sources. LlamaExtract allows you to define the fields you want extracted from a document and uses advanced document parsing and LLMs to extract the data relevant to these fields.
Additionally, in many cases, it might make sense to include reasons and citations as to why a certain field was extracted and what part of a given document certain information was extracted from. So, as a part of our latest improvements to LlamaExtract, we’ve introduced optional citations and reasoning for each extracted field.
Now, for every field we extract from a document, we provide the exact location that information was extracted from, alongside the agent’s reasoning for the extraction.
In this article, let’s walk through a simple example of extracting information from an SEC filing report.
Creating an Extraction Agent
LlamaParse users get the option to create an Extraction agent via the LlamaParse UI, as well as via the open-source SDKs.
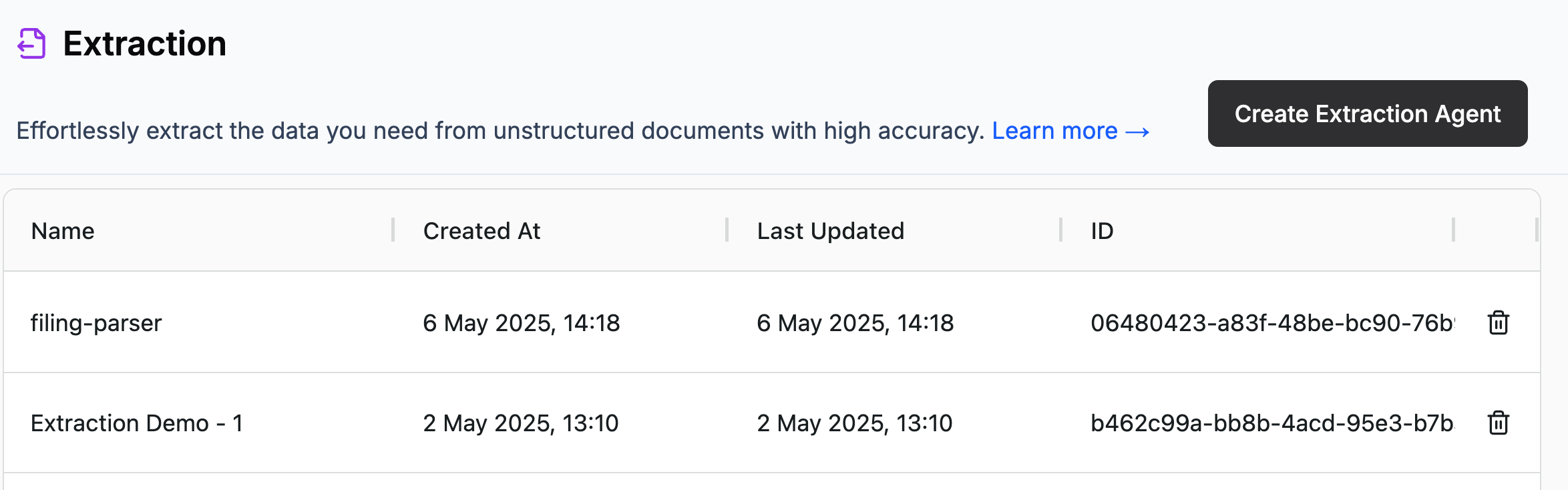
In LlamaParse, start with “Create Extraction Agent”
Defining Extraction Schema
When configuring an Extraction Agent via LlamaParse, you can chose from a predefined set of schemas. In this article, we’ll be extracting from the NVIDIA 10k SEC filing for 2025, so we can pick the pre-built 10K filing schema.
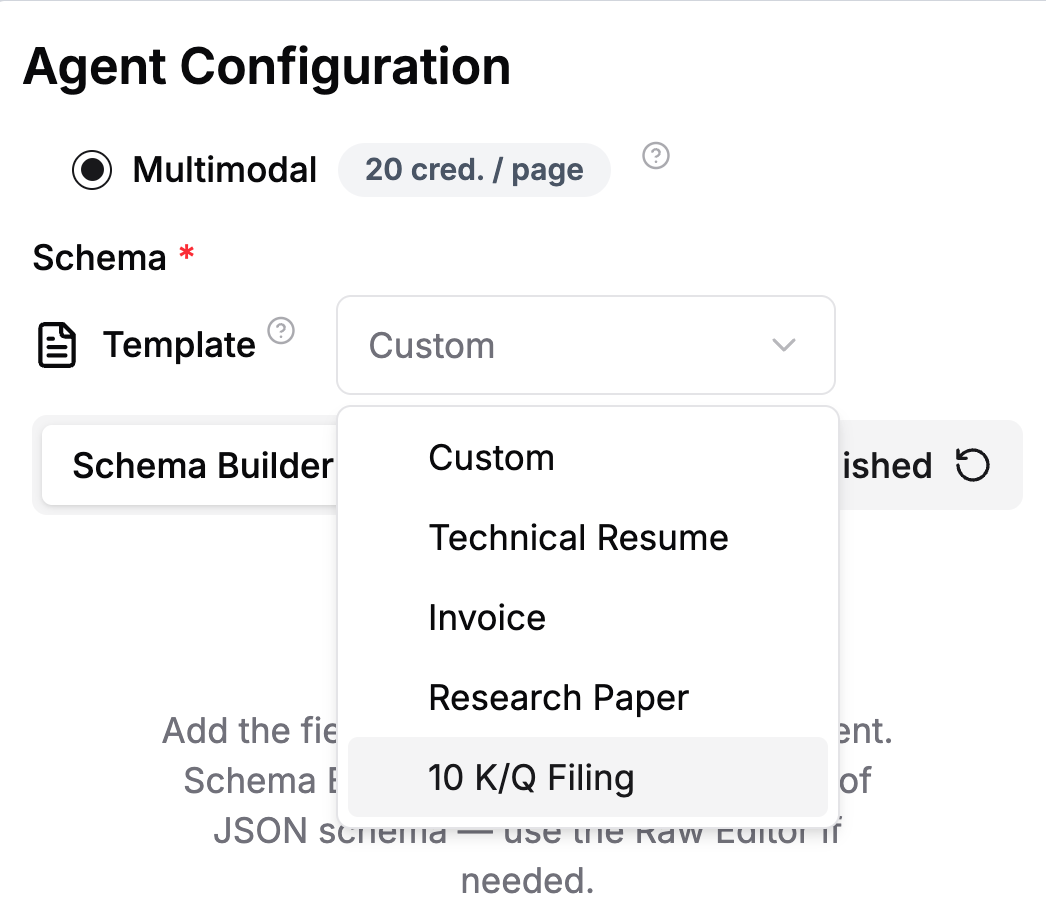
We also have the option of defining our own custom schema, which we can build in the UI, or we can create it programatically. For example, when creating the Extraction Agent via the Python SDK, we can initialize it with our own schema using Pydantic:
python
from pydantic import BaseModel, Field
from enum import Enum
class FilingType(str, Enum):
ten_k = '10 K'
ten_q = '10-Q'
ten_ka = '10-K/A'
ten_qa = '10-Q/A'
class FinancialReport(BaseModel):
company_name: str = Field(description="The name of the company")
description: str = Field(description="Basic information about the filing")
filing_type: FilingType = Field(description="Type of SEC filing")
filing_date: str = Field(description="Date when filing was submitted to SEC")
fiscal_year: int = Field(description="Fiscal year")
unit: str = Field(description="Unit of financial figures (thousands, millions, etc.)")
revenue: int = Field(description="Total revenue for period")The descriptions for each field provided additional context to the agent, explaining what the underlying LLM should aim to extract from the SEC filing document.
Requesting Citations and Reasoning
While configuring our Extraction Agent, we can also turn on some advanced settings. This is where we can ask for the agent to include citations for every field, and reasoning for each citation.
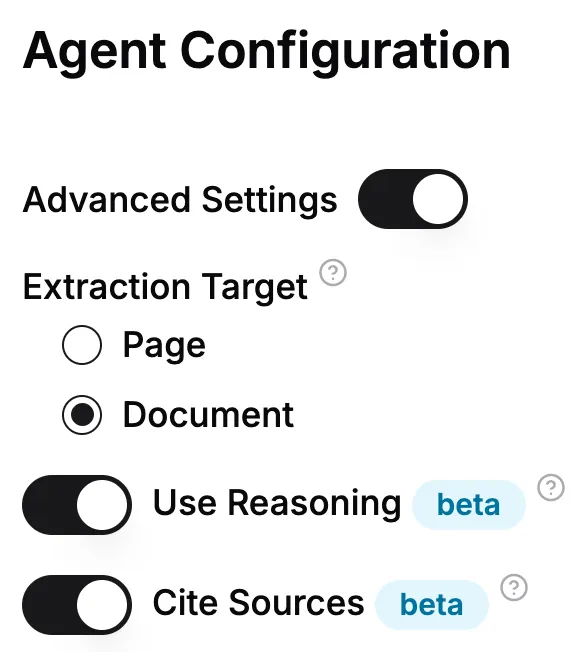
This can also be set by providing our own ExtractConfig and setting use_reasoning and cite_resources to True.
python
from llama_cloud.types import ExtractConfig, ExtractMode
config = ExtractConfig(use_reasoning=True,
cite_sources=True,
extraction_mode=ExtractMode.MULTIMODAL)
agent = llama_extract.create_agent(name="filing-parser",
data_schema=FinancialReport,
config=config)Example of Extracting Data from SEC Filings
For example, for the example PDF document on NVIDIA SEC filings, with the custom schema we provided above, we get the following data:
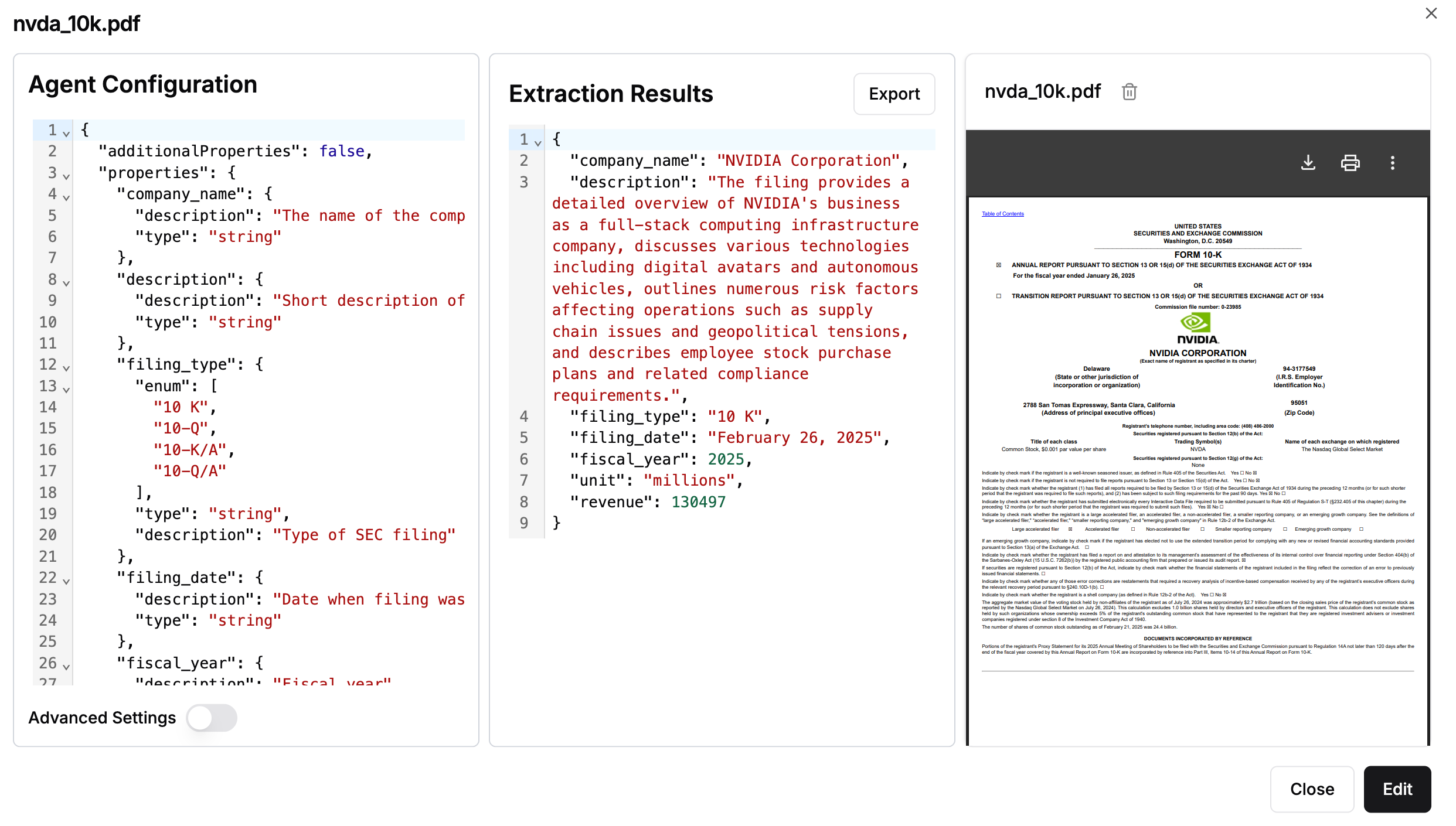
Now, we can also inspect the citations for each field that was extracted, in extraction_metadata :

Let’s have a look at the citations and reasoning in more detail. The reasoning field explains why an extracted field was extracted. While this field may include more explanation, you may also notice that some of them will simply quote "VERBATIM EXTRACTION" , meaning the field was extracted because it’s directly mentioned in the text.
In some cases where field was not extracted or left blank, you may also notice that the reasoning field mentions "INSUFFICIENT DATA" , indicating that there was no supporting data in the source document.
For example, our Extraction Agent above extracted NVIDIA Corporation for company_name , the reasoning and citation to support this extraction is the following:
json
"company_name": {
"reasoning": "VERBATIM EXTRACTION",
"citation": [
{
"page": 1,
"matching_text": "NVIDIA CORPORATION"
},
{
"page": 2,
"matching_text": "NVIDIA Corporation"
},
{
"page": 3,
"matching_text": "All references to \\"NVIDIA,\\" \\"we,\\" \\"us,\\" \\"our,\\" or the \\"Company\\" mean NVIDIA Corporation and its subsidiaries."
},
...
}
However, for the extraction for fiscal_year we also get more of an explanation in the reasoning:
json
"fiscal_year": {
"reasoning": "The fiscal year ended January 26, 2025, indicates the fiscal year is 2025. Additionally, multiple references throughout the text confirm the fiscal year 2025 in various contexts.",
"citation": [
{
"page": 1,
"matching_text": "For the fiscal year ended January 26, 2025"
},
{
"page": 6,
"matching_text": "In fiscal year 2025, we launched the NVIDIA Blackwell architecture"
},
{
"page": 12,
"matching_text": "fiscal year 2025"
},
{
"page": 17,
"matching_text": "our gross margins in the second quarter of fiscal year 2025 were negatively impacted"
},
...
}
What Next?
LlamaExtract streamlines the process of extracting structured data from complex documents, making it both efficient and transparent. It allows you to define custom extraction schemas and configure settings for reasoning and citations. Whether through the LlamaParse UI or the open-source SDKs, you can quickly deploy powerful extraction agents tailored to your specific needs. With the addition of citations and reasoning, LlamaExtract allows you to verify the extracted information—bringing clarity and confidence to automated document processing.
In this article, we briefly went over the new reasoning and citation feature in LlamaExtract. As a next step, you can follow the full recipe “Extract Data from Financial Reports - with Citations and Reasoning”.
Get started today! Sign up for LlamaParse with LlamaExtract.