The Model Context Protocol (MCP) has sparked significant excitement in the AI community. It gives every data‑ or SaaS‑owner a universal “USB‑C port” that any agent can discover at run‑time. As standardized tool endpoints proliferate — the official MCP servers repository features everything from Auth0 to Zapier — developers are asking important questions about whether they should bother using vector indexing and retrieval pipelines, i.e. RAG pipelines. If agents can route queries directly to specialized MCP servers each owned by an external software/data provider (what we'll call "federated MCP"), do we still need the traditional approach of crawling, indexing, and retrieving from centralized knowledge bases?
Our thesis is that agents will still need preprocessing and indexing layers for rapid semantic lookup and search of unstructured data. At the same time, for already structured data, federated MCP tools will enable agents to perform deeper context lookup and manipulation of structured data sources.
The Promise of Federated MCP: all your data in real time
MCP introduces a compelling alternative to vector indexing for some use cases. Instead of crawling Salesforce data into a vector store, you can expose Salesforce as a live queryable tool. An agent handling "How many support tickets did we close this week?" could call a Jira MCP server directly, getting real-time results without maintaining a parallel search infrastructure.
This approach promises fresher data since results come straight from the source at query time, and it can simplify pipelines for structured data sources. For well-organized SaaS tools like Jira issues or Salesforce records, MCP shifts the paradigm from "retrieve from my index" to "ask the source itself."
This “federated MCP” approach of building an agent that can connect directly to MCP servers owned by third-party providers is equivalent to federated search. In an agentic federated search architecture, the agent queries multiple specialized servers as tools and combines their results.
Counterpoint: Federated Search is still Worse than a Global Indexing Layer (for now)
While federated search through MCP sounds elegant in theory, it introduces several practical challenges that traditional unified indexing solves more effectively.
- No Global Understanding. When an agent queries five different MCP servers—say Confluence, Salesforce, Google Drive, Jira, and a document repository—each system returns results based on its own internal ranking. A Confluence page about "Q4 strategy" might rank highly in Confluence's results, while a more relevant Salesforce opportunity record ranks lower in its results. Without a unified ranking algorithm that understands relationships across sources, the agent struggles to surface the most relevant information. As Qatalog's research on federated vs. enterprise search demonstrates, this fundamental limitation of federated approaches has been well-documented—each index is searched separately, making it impossible to achieve true relevance ranking across heterogeneous data sources.
- Performance and Latency Bottlenecks: Enterprise queries often need to span multiple data sources simultaneously. Consider asking "What were the customer complaints about our mobile app launch last quarter?" This might require data from: With federated MCP queries, you're making multiple API calls in parallel and waiting for the slowest response. Coveo's analysis of federated search highlights how this "slowest link" problem becomes particularly acute at enterprise scale, where you might be querying dozens of systems simultaneously.
- Customer support tickets (Jira/Zendesk)
- Sales feedback (Salesforce)
- Product analytics (internal databases)
- Engineering post-mortems (Confluence)
- The Quality Dependency Problem: MCP federated search is only as good as each provider's search implementation. Many enterprise SaaS tools have basic keyword search capabilities that pale compared to modern semantic search. You're in effect outsourcing your retrieval quality to vendors who may not prioritize search as a core competency. Glean's recent analysis puts this in stark terms: while federated search sounds simple in theory, third-party SaaS search endpoints are often basic keyword searches that lack the semantic understanding and ranking sophistication needed for enterprise AI applications.
What this means in practice: If you try to replicate RAG by just hooking your agent up to a bunch of federated MCP servers, your users will experience longer wait times, less relevant results, and inconsistent quality depending on which systems happen to contain their answers. For enterprise use cases where information workers need fast, comprehensive answers, these limitations can make MCP-only approaches frustrating rather than helpful.
Instead, providing a centralized indexing and retrieval layer across heterogenous data sources and exposing that as a centralized MCP retrieval tool to the agent can enable rapid lookup of semantically relevant content.
CounterPoint 2: Your Unstructured Data Still Needs a High-Quality Document Intelligence Layer
Despite the promise of MCP for structured data sources, 90% of enterprise data is in the form of PDFs, PPTs, scans, and spreadsheets—formats that lack a native query API. This content needs to be preprocessed and structured before an AI agent can access that content through MCP. That means:
- Document Parsing - Converting complex PDFs, Word docs, PowerPoint, and other file formats into structured, searchable content
- Extraction - pulling out the right metadata, e.g. a table of financial metrics or key fields from an invoice
- Chunking + Indexing - breaking the document down into relevant context chunks - this helps return bite-sized context for the agent in a way that helps to more easily embed this data but also return data.
LlamaParse helps to solve this by providing best-in-class document parsing that can handle complex layouts, tables, charts, scanned images, and multi-column text. We transform documents into clean, structured data using templates or custom schemas for batch document processing, then enable advanced, agentic hybrid retrieval with metadata filtering.
Unstructured data as MCP tools
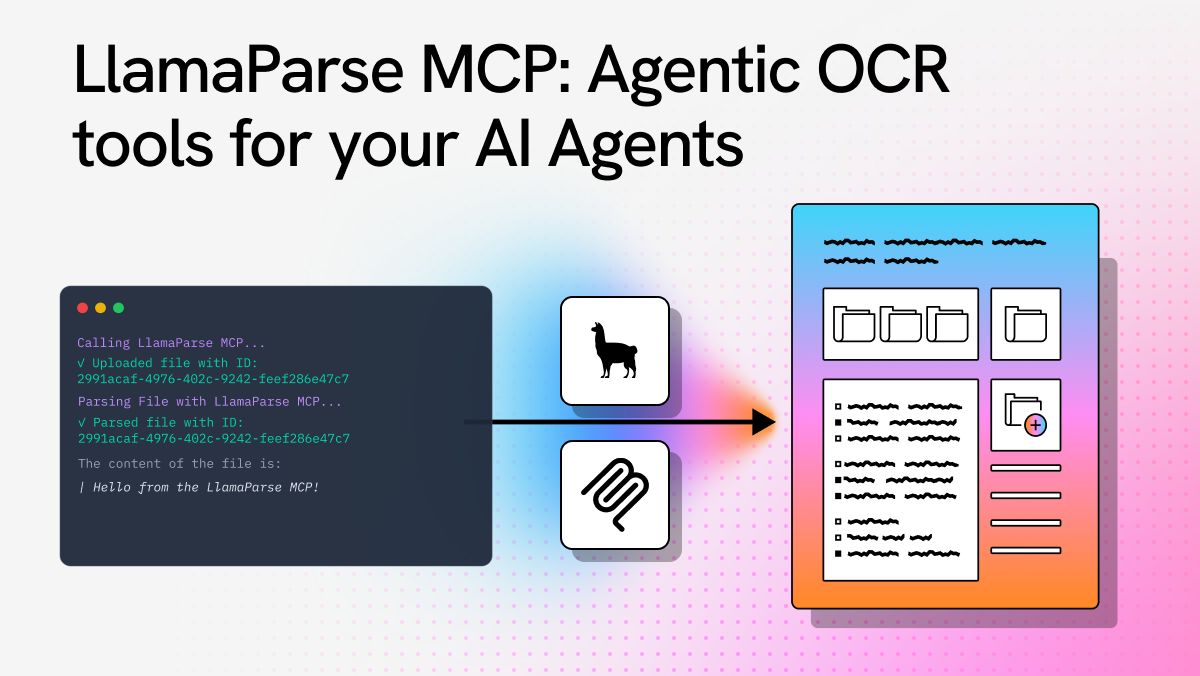
In the world of documents, we see MCP as an opportunity to expose sophisticated document intelligence through standardized tool interfaces (we support this through the LlamaParse MCP demo repo).
A "document MCP toolbox" might include:
- Document Parser Tool: Converts any file format into structured, searchable content
- Semantic Search Tool: Performs vector search across processed document collections
- Document QA Tool: Answers questions about specific documents with full context
- Schema Extraction Tool: Pulls structured data (invoices, contracts, forms) into standardized formats
Where Federated MCP is Better than Vector Search Right now
Today, there are already certain interaction modes where having an agent directly connect to a third-party MCP server is strictly better than trying to index that data and use RAG.
MCP Provides Ways to Manipulate Your Services
This advantage is straightforward but crucial. Native search indexes are designed for lookup, not action-taking. When you want an agent to:
- Write and send an email through Gmail
- Create a new Jira ticket with specific assignees and priority
- Update a Salesforce opportunity status
- Schedule a meeting in Google Calendar
- Post a message to a specific Slack channel
You need the actual service APIs, not indexed representations of past data. Service providers maintain a natural moat here since they already expose these capabilities through well-documented APIs.
Direct MCP Interfaces Provide Deeper Ways to Query a Specific Data Source
Sometimes the type of context a user or agent wants to look up from a data source can't be satisfied by a simple search. Semantic search through a vector database excels at finding relevant documents or passages, but it struggles with structured queries that require understanding relationships, constraints, and complex logic.
Consider these examples where MCP shines:
Structured Query Interfaces: Any text-to-SQL scenario where you need precise data filtering. A query like "give me all high-priority tickets assigned to the ML team created in the last two weeks" isn't best answered through semantic search. Instead, it requires an agent to write JQL (Jira Query Language) or SQL to return a concrete list of structured data.
Real-time State Queries: Questions like "What's the current status of our deployment pipeline?" or "Which team members are available for a meeting at 5pm?" require live data that may change by the time you rebuild your search index.
Complex Business Logic: Queries involving calculations, aggregations, or business rules that are baked into the source system. For instance, "What's our projected revenue impact if we delay the Q2 feature release by three weeks?" might require Salesforce's built-in forecasting logic rather than static indexed data.
MCP Will (Eventually) Provide Better Authentication Integration
While still evolving, MCP's roadmap includes sophisticated user-level authentication that could significantly simplify enterprise deployments. Currently, one of the practical advantages of any centralized search index/RAG service is centralizing permissions—your search index can enforce access controls across multiple data sources.
As MCP authentication matures, this advantage may diminish. Agents will be able to directly access data sources with native user permissions, eliminating the complex permission-mapping challenges that enterprise search systems face today.
The best solutions will combine MCP and RAG
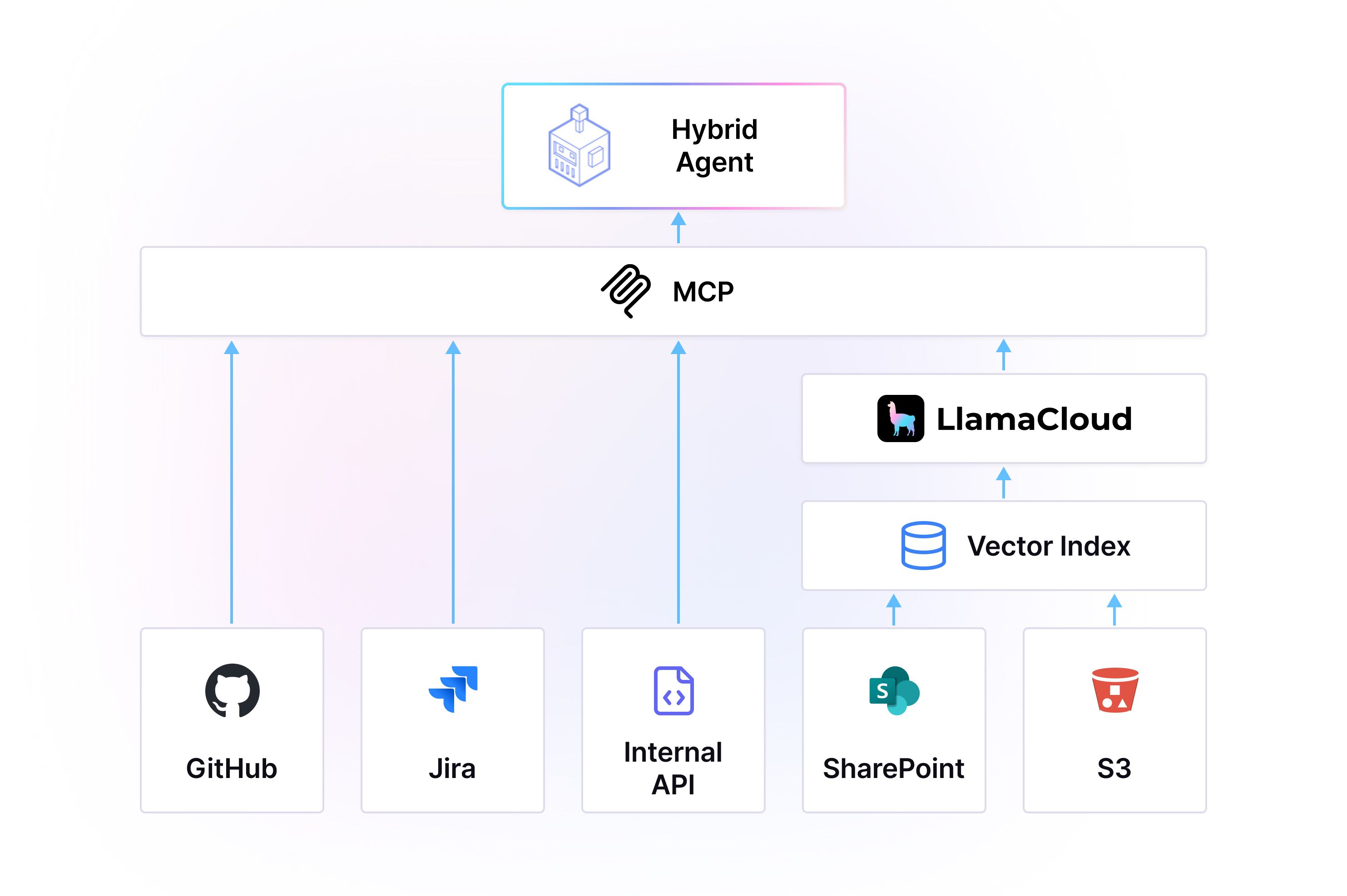
As we see things, the best agents will use a mix of MCP tools: tools that directly connect to third-party services, and retrieval tools over pre-indexed data.
Imagine an agent architecture that mimics how humans actually work:
- Fast Lookup Phase: Use retrieval tools powered by preprocessed indexes to quickly identify relevant context and get the lay of the land
- Deep Dive Phase: Use native MCP interfaces to drill down into specific data sources for precise information or to take actions
- Synthesis Phase: Combine insights from both approaches to provide comprehensive, actionable responses
For example, when asked "Should we approve this $2M equipment purchase?", an agent might:
- RAG Search: Find past equipment ROI analyses, CapEx policies, and vendor contracts from document archives
- MCP Queries: Check current budget status in ERP and pull live equipment maintenance costs
- Action Taking: Create purchase orders, update budgets, and notify stakeholders through enterprise systems
Use LlamaParse to provide your MCP tools over your unstructured data
MCP represents a significant evolution in how AI systems access and manipulate data, but it doesn't replace the fundamental need for intelligent information processing. Instead, it creates new opportunities to build more modular, capable systems.
The winners in this new landscape will be platforms that:
- Combine both approaches strategically: Use MCP for real-time structured data and actions, while maintaining sophisticated indexing for complex document understanding and cross-source search
- Provide intelligent preprocessing: Transform raw data into formats that agents can actually use effectively
- Expose capabilities through standard interfaces: Make advanced functionality accessible through MCP while maintaining the underlying intelligence layer
- Enable hybrid architectures: Allow developers to mix and match approaches based on specific use case requirements
LlamaParse is the document MCP server for your agents - use it to parse, process, and index your unstructured document data, then expose it as an MCP server. Plug it into any MCP client to take actions on downstream services. With our specialized document parsing capabilities, deep extraction technology, and enterprise-grade indexing, we handle the complex challenge of making your documents truly accessible to AI agents.
If you’re interested in using LlamaParse, come get in touch.