Document parsing (or OCR) is the foundation of every AI agent that works with real-world files. Before an agent can approve a claim, analyze a financial report, or extract terms from a contract, it needs to correctly read the document. Not approximately. Not "close enough." Correctly.
And yet, until now, there hasn't been a benchmark that measures parsing quality the way agents actually need it: across the full range of enterprise documents, evaluated on the dimensions that cause real downstream failures.
Today we're releasing ParseBench, a benchmark of ~2,000 human-verified enterprise document pages with over 167,000 test rules, organized around five capability dimensions: tables, charts, content faithfulness, semantic formatting, and visual grounding. We evaluated 14 methods spanning vision-language models, specialized document parsers, and LlamaParse. While no single method is good at everything, LlamaParse Agentic was the only method tested that is competitive across five key dimensions, scoring 84.9% overall.
The benchmark dataset, evaluation code, and the full scientific paper behind the study are all publicly available:
- Dataset: HuggingFace
- Code & evaluation: GitHub
- Paper: arXiv
What Existing Benchmarks Miss
When a human reads a document, they can work around errors. A slightly misaligned table, a missing footnote reference, a chart that didn't render. Agents can't do that (yet). An agent approving an insurance claim reads a specific cell in a coverage table. If the table headers are misaligned, it reads the wrong column. If a decimal is missing, a calculation is off by multiple factors.
The bar for OCR and document parsing has shifted from "good enough for a human to read" to "reliable enough for an agent to act on." We call this semantic correctness: whether the parsed output preserves enough structure and meaning for correct downstream decisions.
Existing benchmarks don't measure this well in two main ways:
- Wrong documents. Most benchmarks draw from academic papers, web content, or narrow corpora. The enterprise documents that drive real automation (financial filings, contracts, regulatory submissions) are underrepresented. Even OmniDocBench, the most diverse benchmark available, draws 6% of its pages from enterprise content.
- Wrong metrics. Text-similarity metrics (BLEU, ROUGE, edit distance) penalize superficial differences like whitespace or whether you output HTML vs. Markdown, while missing critical errors like a transposed table header, a chart reduced to raw OCR text, or a strikethrough that got silently dropped.
What ParseBench Evaluates

ParseBench tests five capability dimensions that mater most to end-users:
1. Tables
Tables are everywhere in enterprise documents, and these real-world tables aren't the simple grids you see in academic benchmarks. Merged cells, hierarchical headers, and span across multiple pages, and multiple tables per page will trip up even the best document processing pipeline.
We introduce a new metric called TableRecordMatch that treats tables the way downstream systems actually consume them: as collections of records where each row is a set of values keyed by column headers. This means we don't penalize harmless differences like column reordering, but we heavily penalize the critical errors like transposed headers or dropped column names.
2. Charts
Most parsers we tested either skip charts entirely or dump out raw OCR text, neither of which gives an agent usable data. Instead, what is needed is the actual values with their correct series names and axis labels, so that it can be processed in downstream workflows.
We annotate up to 10 spot-check data points per chart, each with a numerical value, associated labels, and a tolerance. Charts with explicit value labels must match exactly; charts where values must be read from axes get a 1% tolerance, since pixel-perfect reading is unrealistic.
3. Content Faithfulness
The most fundamental requirement: did the parser actually capture all the text, in the right order, without making things up? We test for three failure modes:
- Omissions: dropped text at word, sentence, and digit levels
- Hallucinations: fabricated content that doesn't exist in the source
- Reading order violations: multi-column layouts linearized incorrectly
This is evaluated through dense rule-based tests (167K+ rules across the dataset), not fuzzy text similarity. If your OCR is dropping data, you need to understand what types of documents trigger that.
4. Semantic Formatting
Most parsers treat formatting as cosmetic and strip it. But some formatting carries meaning:
- A strikethrough price is not the current price
- A superscript "1" is a footnote reference, not the number one
- Bold text in a financial report often marks key aggregate values
- Title hierarchy determines document structure
If your agent can't distinguish $49.99 $39.99 from "$49.99 $39.99", it might quote the old price.
5. Visual Grounding
Can the parser trace every extracted element back to its source location on the page? This is critical for auditability in regulated industries. If an agent extracts a coverage limit from an insurance form, you need to be able to point to exactly where on the page that number came from.
We evaluate this as a joint problem: the parser must find the right region (localization), assign the right label (classification), and attach the right content (attribution).
How the dataset was built
All ~2,000 pages come from real, publicly available enterprise documents spanning insurance (SERFF filings), finance (public financial reports), government documents, and other domains. We deliberately sample from straightforward to adversarially hard cases.
Ground truth is generated through a two-pass pipeline:
- Auto-labeling: Frontier VLMs generate initial annotations
- Human verification: Annotators review and correct every page, with the review workflow tailored to each dimension's ground-truth format
ParseBench Results
We tested 14 methods across three categories: general-purpose VLMs (GPT-5 Mini, Haiku 4.5, Gemini 3 Flash, Qwen 3 VL, Dots OCR 1.5), specialized document parsers (Textract, Azure Document Intelligence, Google Cloud Document AI, Reducto, Docling, Extend, LandingAI), and LlamaParse (Cost Effective and Agentic modes).
Here are the headline results:
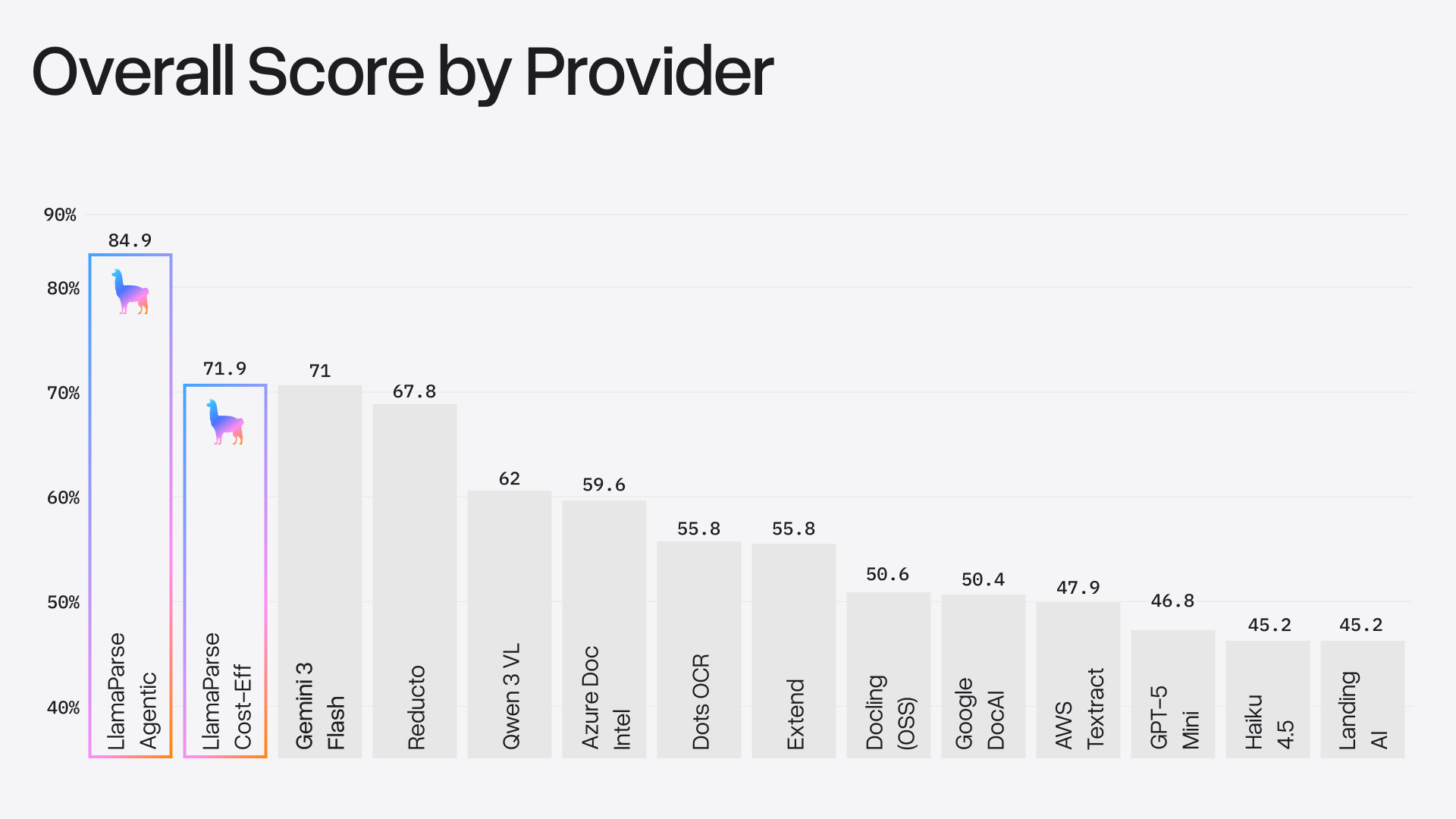
A few key takeaways:
Charts are the great divider. Only four providers exceed 50%. Most specialized parsers score below 6% since they do not extract chart data into structured tables.
Content faithfulness is mostly solved (but not quite). The best methods hit ~90%, which sounds good until you realize that means agents still encounter meaningful omissions and hallucinations on 1 in 10 pages. For high-stakes workflows, that's not good enough. ParseBench helps us (and our users) understand which types of documents need extra care.
Formatting is widely ignored. Most parsers treat strikethrough, superscripts, and bold as cosmetic decoration and strip them. Scores range from 1.0% (Docling) to 85.2% (LlamaParse Agentic).
Visual grounding separates VLMs from specialized parsers. GPT-5 Mini and Haiku score below 8% on grounding. Accurate element-level localization requires spatial reasoning beyond what a single LLM pass provides. Meanwhile, traditional document parsers that were built around layout detection score 55-80%.
Quality vs. cost
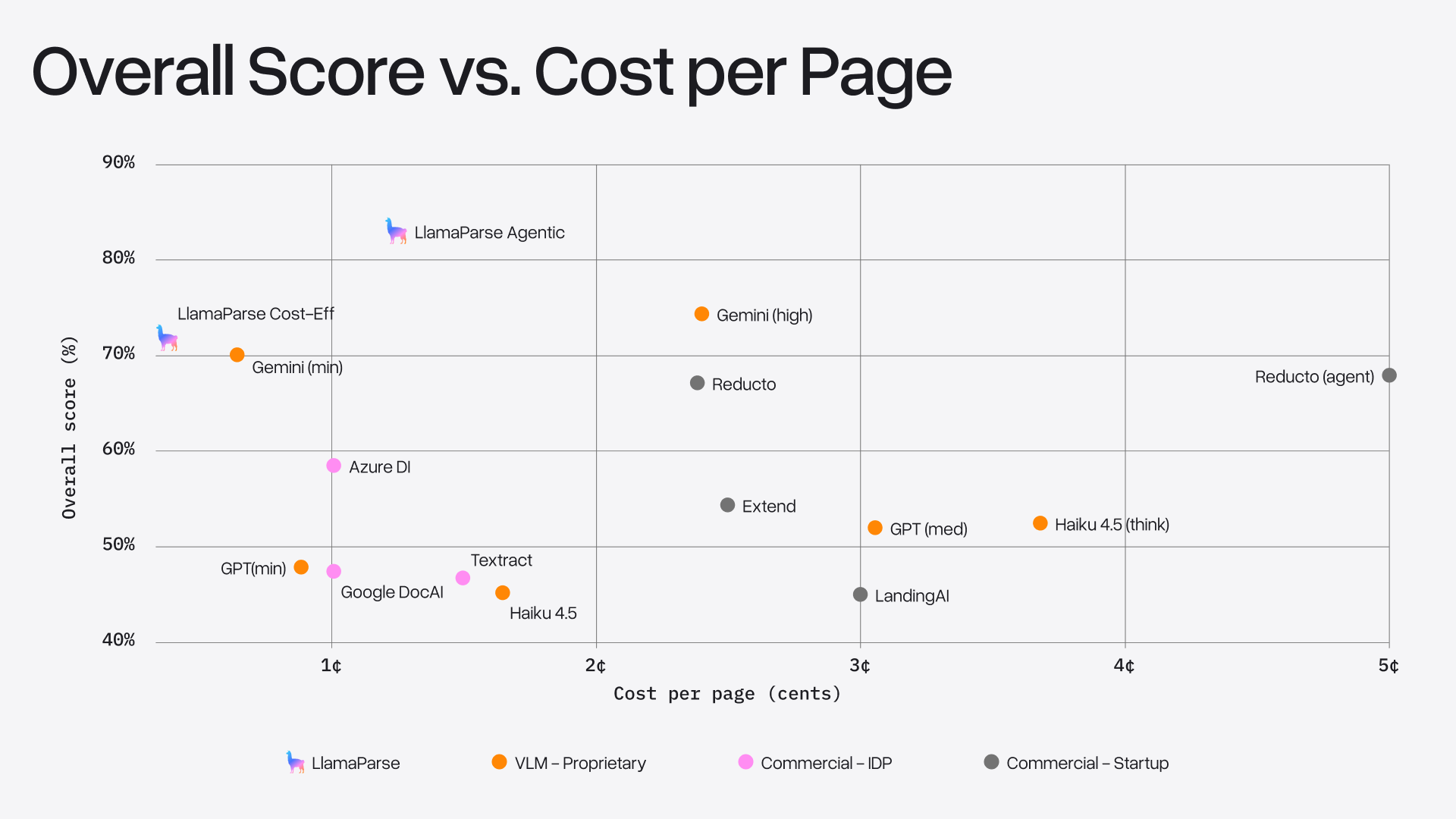
We also analyzed the quality-cost tradeoff. Two patterns stand out:
- Throwing more compute at VLMs gives diminishing returns. Gemini gains ~5 points going from minimal to high thinking at 4x the cost. GPT-5 Mini and Haiku see even smaller gains at 3-4x the cost.
- LlamaParse sits on the OCR frontier. Agentic mode (~1.2¢/page, 84.9% overall) outperforms all other providers at any cost level. Cost Effective mode (<0.4¢/page) is the cheapest option while remaining competitive with Gemini at minimal thinking.
Try it yourself
ParseBench is fully open source. You can evaluate any parsing tool on the benchmark:
html
# Clone
git clone <https://github.com/run-llama/ParseBench>
cd ParseBench
# Install
uv sync --extra runners
# Run the benchmark on any supported pipeline
uv run parse-bench run <pipeline_name>
# View interactive reports
uv run parse-bench serve <pipeline_name>The benchmark includes 90+ pre-configured pipelines and all our evaluation code. Adding your own OCR model is straightforward (and encouraged!). Be on the lookout for an official leaderboard soon as well.
- Dataset: HuggingFace
- Code & evaluation: GitHub
- Paper: arXiv