


Document OCR has been around for decades, but it has traditionally relied on complex hand-written pipelines and “traditional” ML systems. Over the past two years we’ve seen huge advancements in document understanding powered by general frontier models and specialized models. Models like dots.OCR, PaddleOCR, DeepSeek-OCR, and OlmOCR/OlmOCR2 are helping to drive this “brave-new world” of general visual understanding across an increasing long-tail of document types.
At the same time, it is clear that document parsing is not getting 100% solved anytime soon, even by the frontier models. This means we need comprehensive benchmarks in order to actually measure document parsing progress. Good benchmarks are proxy measurements to achieving the north star of universal OCR accuracy.
OlmOCR-Bench, introduced in the olmOCR paper earlier this year (and revisited in OlmOCR2), is one of the major modern attempts at a systematic document OCR benchmark. It contains 1400+ diverse PDFs that are meant to test the boundaries of VLM capabilities - including formulas, tables, tiny fonts, old scans, and more. It has become quite an influential general test suite.
At LlamaIndex we’ve been aggressively building and benchmarking document OCR for a while. I decided to take a deeper look at OlmOCR-Bench to share thoughts on what it gets right, where it’s incomplete, and paint a picture of what it means to build document parsing systems in general.
How OlmOCR-Bench Works
Unlike older document datasets - FUNSD, PubTabNet - which focus on a specific domain or type of extraction task (e.g. tables), OlmOCR-Bench tries to take a more comprehensive approach in both the data and evaluation methodology.
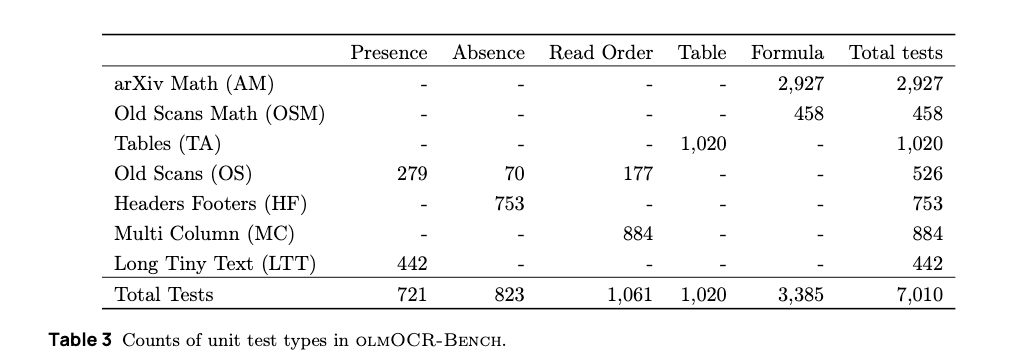
In terms of data, the benchmark covers 1400 PDFs that cover a range of the following document elements:
- Text presence/absence
- Reading order
- Formulas
- Long tiny text
- Old scans
- Headers/footers
- Multi-column layouts
These documents are also sourced from a variety of sources in order to capture these properties. This includes ArXiv papers, public domain math textbooks, Library of Congress digital archives, dense Internet Archive sources, and others.


The evaluation metric is based on a large quantity of binary pass-fail “unit tests”. It is a push against more “fuzzy”/continuous metrics like edit distance or LLM as a judge. These run the dual risk of rewarding a parsed output that is structurally wrong (e.g. reading order is broken), or penalizing correct-but-varied interpretations of the same visual output.
OlmOCR has 7000+ such unit tests. Each test is designed to be deterministic: “does this string appear?”, “does this cell appear above that cell?”, “does equation X show up in the OCR output with the same relative geometric structure?”
What It Gets Right
OlmOCR-Bench is a solid effort to help advance the overall document OCR space.
It does try to include a diverse set of content across a bunch of different dimensions: tiny text, historical scans, math from arXiv, basic table relationships. There are “sub-scores” calculated for each category, and they’re all averaged together to create the final score. This provides much more of a granular breakdown than a single score over a single type of element. Also all of these elements are important criteria in complex documents.
There are also certainly a lot of advantages towards using binary, verifiable unit tests. The examples in both olmOCR papers illustrate this well. For instance, with formulas, edit distance can declare the “wrong” output better because it just counts character differences — even though the equation visually renders incorrectly (see Figure 2 from OlmOCR2 above).
The sliding scale on “prebuilt” continuous metrics isn’t always correlated with how “correct” we think it is. With a normal edit distance metric, a small error in the math formula (e.g. having an x swapped for a y is a 1 char mistake) which is the same as a random tiny OCR mistake; or even worse, it gets completely overshadowed by 100 char mistakes due to missing a footer, having wrong reading order, etc. With binary unit tests, you can decide yourself on how to weight the errors depending on your specific use case - maybe for your use case formula recognition is much more important
The creators of the benchmark have clearly spent a lot of time creating a comprehensive set of 7k+ tests.
I do appreciate all the effort here. To be very clear OlmOCR-Bench is a great effort towards a general benchmark, and its tests are reproducible, low latency/cost, and easy to setup and maintain.
Regardless of my suggestions/constructive feedback in the following sections, I think any attempt to help measure document parsing progress is great to have in order to keep pace with all the advancements happening on the core capabilities. I also understand that this is something the authors are likely evolving over time.
Where It’s Incomplete
From our own experience working with hundreds of customers on their document processing needs, I do think that there is still a gap between OlmOCR-Bench and a benchmark that reflects the needs of most real-world use cases.
Specifically:
- The data actually isn’t quite diverse enough
- The binary unit tests are still quite coarse over complex elements like tables and reading order.
- The binary unit tests use exact match which can be quite brittle.
- Some unit tests don’t necessarily reflect actual desired behavior (e.g. headers/footers).
- There is inductive bias in using the models to generate tests.
The data and tests actually are not quite diverse enough: This is one of the biggest flags in the benchmark. The underlying PDF distribution is ~56% academic, plus books, brochures, and legal/public documents. The benchmark categories reinforce this: arXiv math, old textbooks, multi-column journal pages.
A LOT of real-world use cases involve other document types - these types include invoices, forms, financial statements, heavily visual presentations, and more. These real-world use cases contain elements that the benchmark doesn’t quite test:
- Deep complex tables with merged cells (the authors only included tables that Gemini Flash could consistently parse)
- Chart understanding
- Form rendering/checkboxes (the authors explicitly excluded fillable forms)
- Handwriting
- Foreign language text (the authors explicitly excluded non-English text from the dataset).
As a benchmark OlmOCR-Bench is primarily focused on text linearization, and ignores general complexities present in other real-world data.
The binary unit tests are still quite coarse: For certain content types — especially tables and reading order — the tests are still too coarse to capture what “good” actually means in real-world documents. The table tests only check narrow adjacency relationships — essentially “is cell X above cell Y?” — which ignores the larger table structure, spanning, grouping, and completeness that matter for real downstream use. Likewise, the reading-order tests only check local pairwise ordering and deliberately avoid difficult cases like captions, footnotes, floating elements, or wrapped columns. This means a model can satisfy most unit tests while still producing globally incorrect or incomplete outputs. The unit tests catch localized errors, but they’re not expressive enough to capture document-level fidelity.
The binary unit tests use exact match: In the Presence and Absence categories (Section 3.1, first paper ), the benchmark checks whether a specific substring appears verbatim in the OCR output. Small differences — an extra space, a missing comma, a hyphenation change, a slightly different Unicode normalization, or a harmless formatting token — can cause a test to fail. Conversely, a model might drop entire paragraphs or mis-handle a table but still pass because the one referenced phrase happens to match exactly.
Some unit tests don’t necessarily reflect actual desired behavior (e.g. headers/footers): There is an entire section dedicated towards header-footer unit tests that test for the “absence” of headers/footers, with the assumption that the “user” would not want to see this in the final output.
This is objectively not true. In the age of rendering PDFs for LLM text tokens, adding in these elements as metadata (along with other text as metadata) near the top of every page can be extremely helpful to ground the LLM for RAG use cases.
There is inductive bias in using the models to generate tests: The authors use Sonnet 3.7 to render multi-column page to HTML, and then use the HTML to generate unit tests on reading order. They also use Gemini 2.0 Flash to perform text extraction on headers/footers as well as tables, and throw away any data that Gemini 2.0 Flash cannot parse.
This creates an inherent bias where if the underlying model is distilled from Sonnet/Flash, then it generally has an advantage on the benchmark, even if the text outputs are correct. In OlmOCR 2.0 the authors use synthetically generated HTML pages to create unit test rewards for RL-finetuning, and the HTML pages are generated from Sonnet 4.0. This will create subtle alignment effects, since models trained with this pipeline will do better on tests derived from the same HTML template.
Benchmarking Document OCR for your Use Cases
Building a general document parsing benchmark is hard. We don’t discourage using existing general benchmarks like OlmOCR-Bench.
However we also encourage you to build a simple test suite over your own data. The test suite itself doesn’t need to be super comprehensive but also doesn’t have to - even a simple one can give you a more direct signal of which parsing models work well for your use cases:
- Build a subset of your own data: it will obviously be much more representative of that exact data vs. the biases introduced by any benchmark. It can be as few as ~5-20 documents.
- Get annotated ground-truth where you can: Get annotated ground-truth of each page through human labels. You can do it fully manually, or you can pre-generate it with a model. If you do the latter, just keep in mind the biases above.
- Eyeball or use LLM as a Judge: Eyeballing is honestly not a bad strategy if you don’t have too much data. LLM-as-a-Judge will introduce model bias but from our experience also counteracts some of the downside of trying to define a ton of deterministic binary metrics - frontier LLMs do a good job comparing the semantic representation of the entire page vs. the ground-truth.
- Obtain an overall score or obtain element-specific scores: One of the really good things about OlmOCR-Bench is the fact that it measures data/task-specific scores - math, tables, reading order, tiny text, and more. If you can split it up even better!
This section is worth an entire series of blog posts on its own for how you can setup evals. More coming soon!
What a Next-Gen Document Parsing Benchmark Could Look Like
If we want to move toward a benchmark that better reflects real-world document workflows (the stuff LlamaIndex customers actually care about), we need something more multi-dimensional.
This is a rough sketch of ideas:
| Dimension | Details |
|---|---|
| Cross-Page Structure | Continuation paragraphs, multi-page tables, repeated headers, etc. |
| Tables (Full Fidelity) | Row/col spans, hierarchical headers, nested structures, alignment |
| Reading Order (Global) | Entire narrative flow, floating elements (figures, captions, sidebars) |
| Semantic Correctness | Whether the extracted content means the same thing. |
| Hallucination Robustness | Detecting added/missing content, esp. on low-resolution scans. |
| Data Coverage | Contracts, invoices, forms, regulatory filings, multilingual PDFs, etc. |
| Layout Preservation | High-level formatting, bounding boxes, citations, style signals for downstream agent workflows. |
| End-to-End Utility | How well the OCR output supports actual tasks (RAG, extraction, analysis workflows). |
Closing Thoughts
OlmOCR-Bench is a step forward. The unit-test framing is elegant, and the benchmark has already nudged the field toward more structured, layout-aware evaluation. But there are gaps on real-world business document use cases.
We’ve done extensive internal benchmarking of our own agentic OCR solution LlamaParse across data types, and are iterating on how to share both general representative datasets but also techniques to allow you to benchmark easily on your own data.
FWIW: our preliminary experiments show that for our default “agentic” mode we are competitive with the other SOTA (olmOCR2, Chandra) on tables/multi-column/tiny text/formulas - but the justification for our price point comes from deep visual reasoning over figures, diagrams, forms, and complex table cells.
If you’re looking at OCR solutions over real business documents, come check us out or get in touch!
LlamaParse: https://cloud.llamaindex.ai/
Contact Us: https://www.llamaindex.ai/contact


