

If you have worked with LLM-based extraction, you have likely hit this frustrating wall: you feed in a 50-page catalog or a multi-page table, and the model dutifully extracts the first 40 entries, then stops. The rest? Lost to the attention span limitations of even the best LLMs.
Template-based extraction systems do not have this problem—they will reliably pull every row from a structured table. But they are brittle. Change the format slightly, add some visual noise, or introduce semi-structured content, and your carefully crafted regex patterns and parsing rules break.
LlamaExtract, our structured extraction API, leverages LLMs for their flexibility in extraction: it can handle varied formats, understand context, and adapt to nuances. But that flexibility comes with some failure modes. One of these is dealing with long lists of repeating entities.
In this blog, we’ll cover a new feature — a Table Row extraction target that addresses this limitation.
The Core Problem: Document-Level vs. Entity-Level Alignment
A standard extraction approach would look at the entire document and try to fit everything into your schema at once. This works great when you want to extract specific information or summarize information across a document. But what about when you have hundreds of hospitals in a table? Or thousands of products in a catalog? Document-level extraction treats this as "extract one big list," and LLMs struggle with exhaustive enumeration of repetitive data. LLMs have a U-shaped positional bias where they are good at retrieving from the beginning and end of context and much worse in the middle. They are pattern-matching machines, not patient data entry clerks.
The solution is to align your extraction granularity to the document structure. If your document contains repeating entities, extract at the entity level, not the document level. In LlamaExtract, we have a concept of an Extraction Target. Think of extraction targets as different "lenses" through which you view your document: the default view is of the full document but we can extract at a more granular level, when needed.
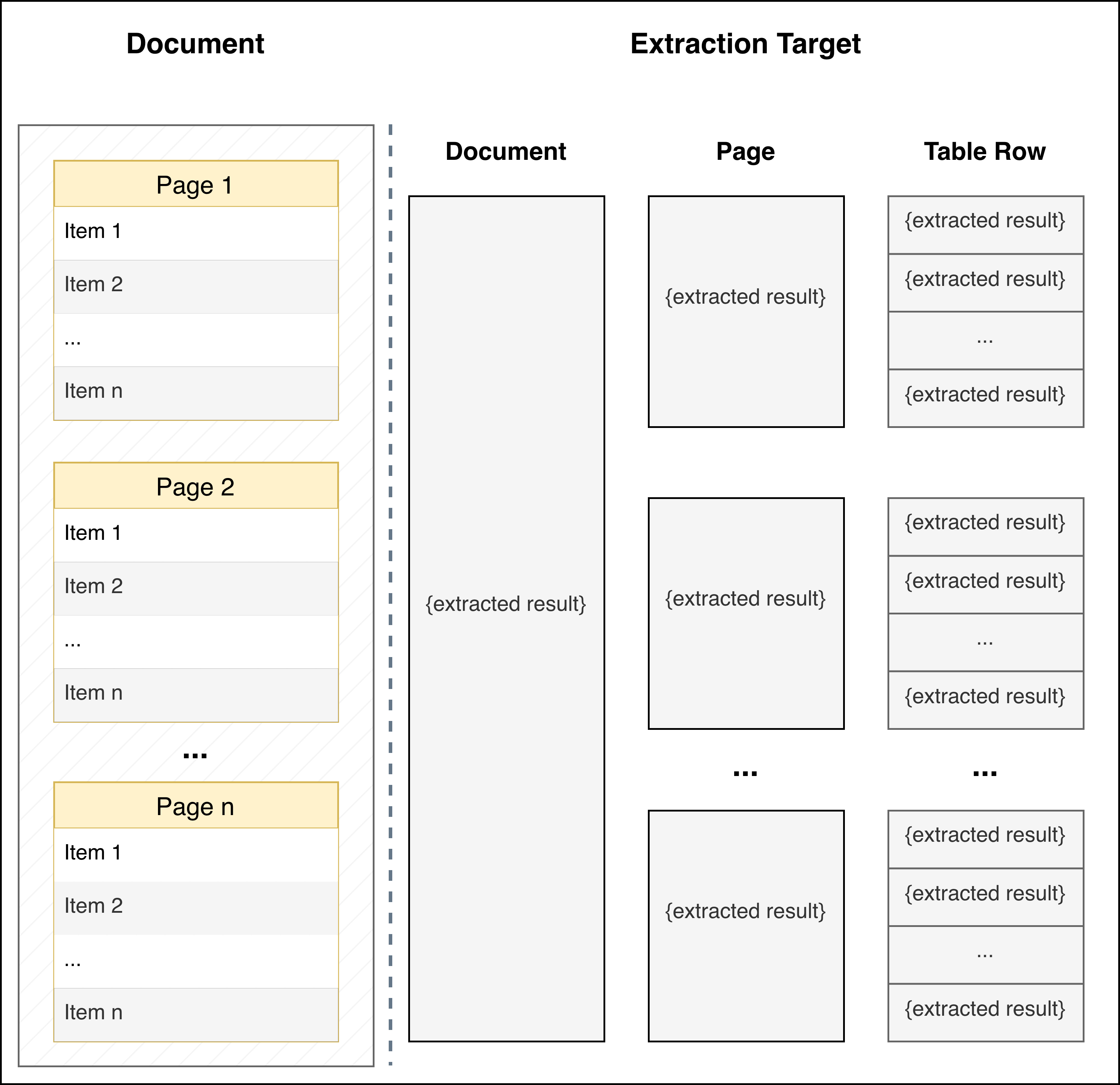
| Extraction Target | Use When | Returns |
|---|---|---|
PER_DOC |
You have a single entity or want document-level summary | One JSON object |
PER_PAGE |
Each page is independent (multi-page forms, separate invoices) | One JSON object per page |
PER_TABLE_ROW |
You have repeating entities (tables, lists, catalogs) | List of JSON objects (one per entity) |
Table Row Extraction Target: Intelligent Document Segmentation
Instead of treating the entire document as a monolithic block or naively splitting by pages, PER_TABLE_ROW target identifies the natural boundaries between entities.
Here is what happens under the hood:
- Document Parsing: The system uses LlamaParse, our propritary parsing solution, to convert arbitrary documents into well-structured markdown output. This includes OCR capabilities, table identification, and document structure analysis.
- Pattern Recognition: The system analyzes your document to detect repeating structural patterns—table rows, list items, section breaks, visual separators, or consistent formatting cues.
- Entity Segmentation: Based on these patterns, it segments the document into chunks, where each chunk corresponds to a single entity or a small batch of entities. This ensures that when the LLM sees the content, it's focused on extracting 1-5 entities at a time, not hundreds.
- Schema Application: Your single-entity schema is applied to each segment independently. The LLM extracts the fields you have defined without getting overwhelmed by the repetitive nature of the data.
- Aggregation: All individual extractions are collected and returned as a list, giving you exhaustive coverage of the entire document.
This approach is experimental and actively being improved. We are working on better handling of edge cases (irregular formatting, nested structures) and more sophisticated pattern detection. But even in its current form, it dramatically improves extraction quality for documents with repeating entities. e.g., in many examples with hundreds of entities, it is common for document-level extraction to drop up to 80% of the entities.
By aligning the extraction window with the natural structure of your data, we get the best of both worlds: LLM flexibility and template-based reliability. Let's see how this works in practice with two real-world examples.
Example 1: Extracting from a Well-Formatted Table
Let's start with an ideal case: a clearly structured table. We have a PDF from Blue Shield of California listing hospitals by county and the insurance plans each accepts.
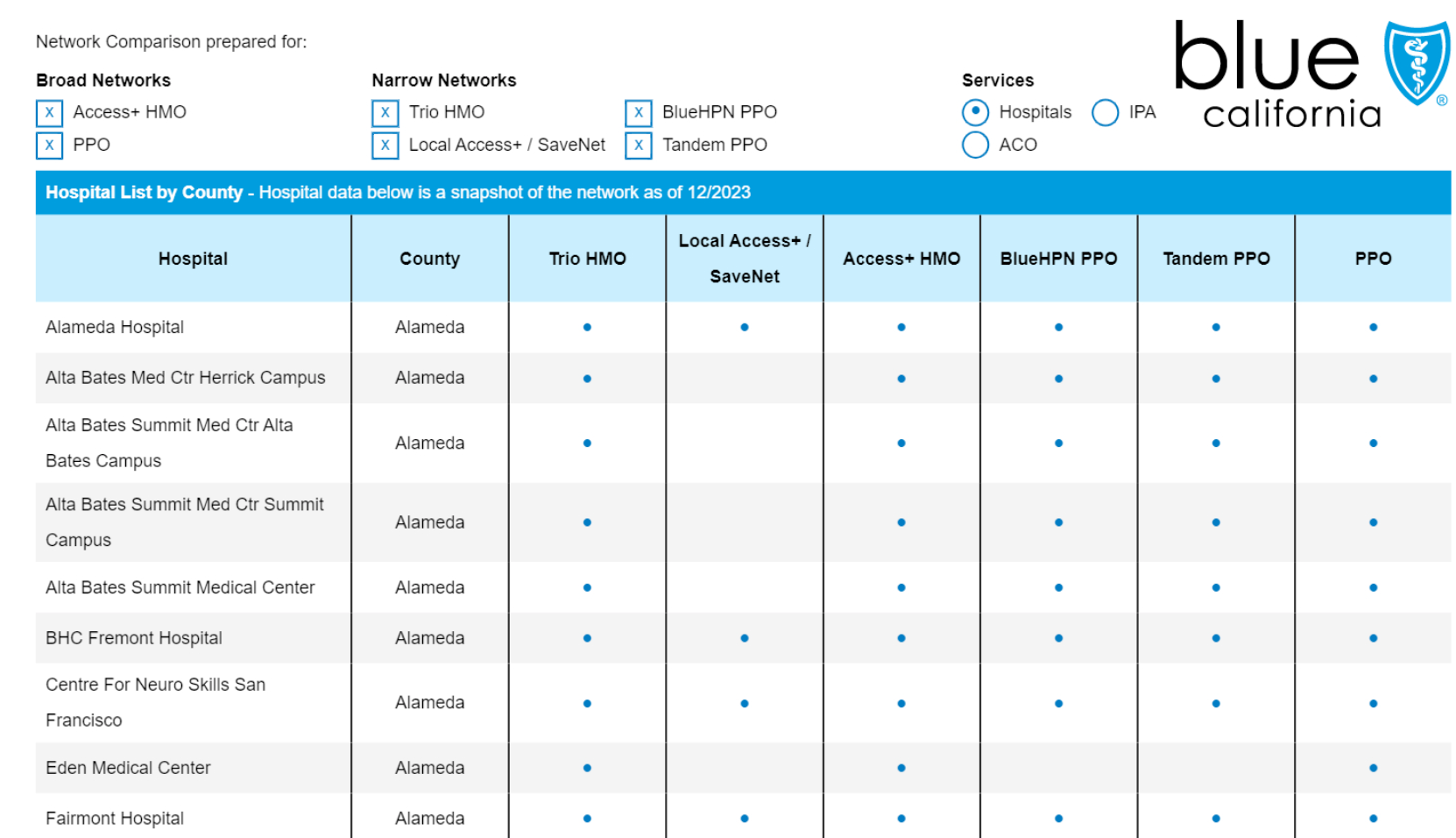
This is a perfect use case for PER_TABLE_ROW extraction:
- Clear structure: Explicit table formatting with rows and columns
- Repeating entities: Each row represents one hospital with consistent attributes
- Local information: All data for each hospital (county, name, plans) is in its row
Note that we define our schema for a single hospital, not the entire document:
python
from pydantic import BaseModel, Field
from llama_cloud_services import LlamaExtract
from llama_cloud_services.extract import ExtractConfig, ExtractMode, ExtractTarget
class Hospital(BaseModel):
"""Single hospital entry with county and available insurance plans"""
county: str = Field(description="County name")
hospital_name: str = Field(description="Name of the hospital")
plan_names: list[str] = Field(
description="List of plans available at the hospital. One of: Trio HMO, SaveNet, Access+ HMO, BlueHPN PPO, Tandem PPO, PPO"
)
llama_extract = LlamaExtract()
result = await llama_extract.aextract(
data_schema=Hospital,
files="./BSC-Hospital-List-by-County.pdf",
config=ExtractConfig(
extraction_mode=ExtractMode.PREMIUM,
extraction_target=ExtractTarget.PER_TABLE_ROW,
parse_model="anthropic-sonnet-4.5",
),
)You can configure the same in the LlamaExtract UI too:
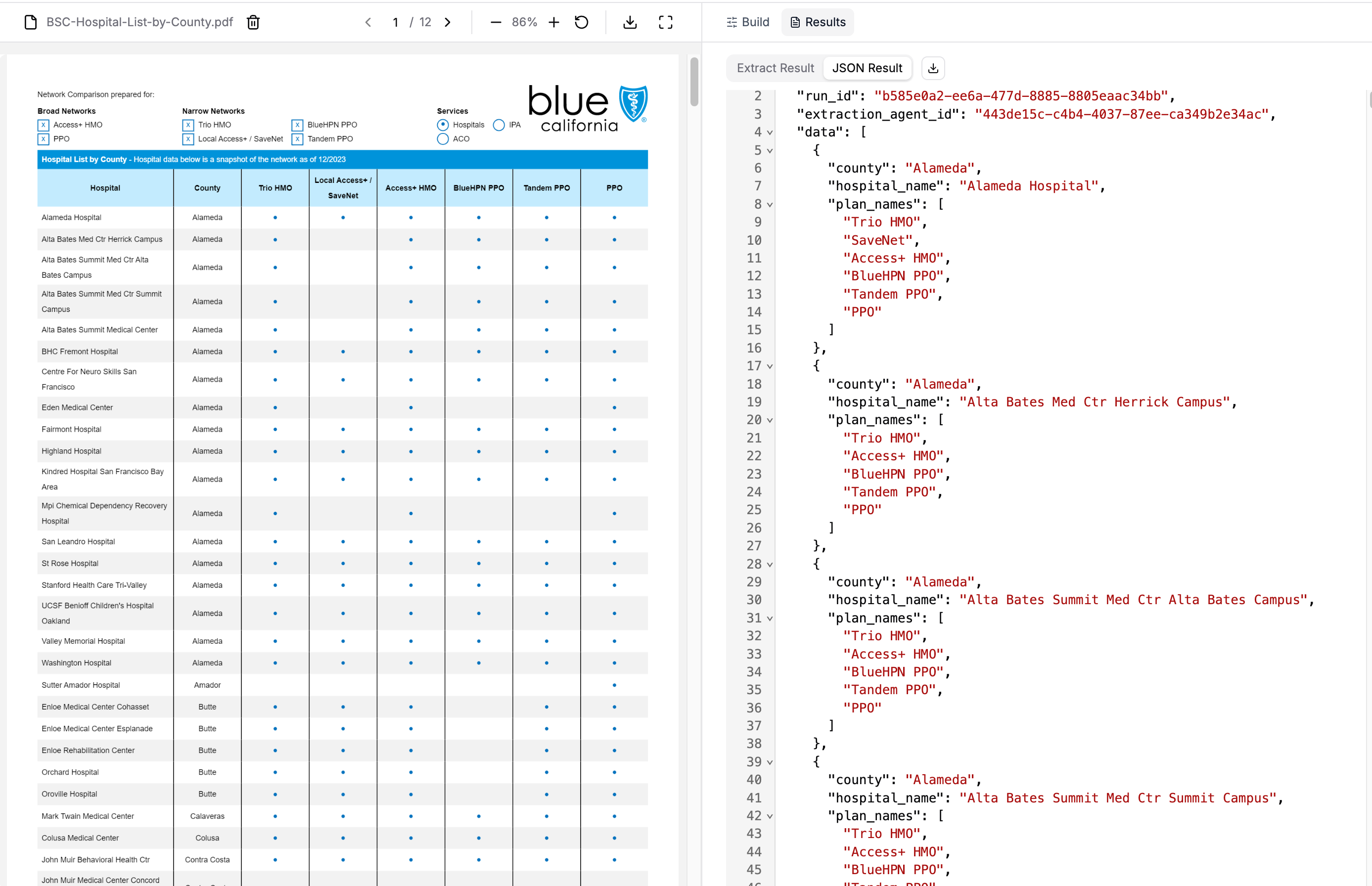
The results:
python
len(result.data) # 380 hospitals extracted!
result.data[:3]
# [
# {
# 'county': 'Alameda',
# 'hospital_name': 'Alameda Hospital',
# 'plan_names': ['Trio HMO', 'SaveNet', 'Access+ HMO', 'BlueHPN PPO', 'Tandem PPO', 'PPO']
# },
# {
# 'county': 'Alameda',
# 'hospital_name': 'Alta Bates Med Ctr Herrick Campus',
# 'plan_names': ['Trio HMO', 'Access+ HMO', 'BlueHPN PPO', 'Tandem PPO', 'PPO']
# },
# {
# 'county': 'Alameda',
# 'hospital_name': 'Alta Bates Summit Med Ctr Alta Bates Campus',
# 'plan_names': ['Trio HMO', 'Access+ HMO', 'BlueHPN PPO', 'Tandem PPO', 'PPO']
# }
# ]
Success! All 380 hospitals extracted from the multi-page PDF. With PER_DOC , we were only able to fetch up to 40 hospitals.
Example 2: Semi-Structured Content
Here's where it gets interesting. PER_TABLE_ROW isn't just for tables—it works for any document with repeating entities that have distinguishable formatting patterns.
Consider a toy catalog. Not a formal table, but a list of products with consistent visual structure:

Each toy entry has:
- Section headers for grouping
- Product codes and names
- Specifications (age range, players, materials)
- Descriptions with dimensions
The pattern is consistent, but it's not a table in the traditional sense. Let's see if row-level extraction can handle it:
python
from pydantic import BaseModel, Field
from llama_cloud_services import LlamaExtract
from llama_cloud_services.extract import (
ExtractConfig,
ExtractMode,
ExtractTarget,
)
class ToyCatalog(BaseModel):
"""Single toy product entry from catalog"""
section_name: str = Field(
description="The name of the toy section (e.g. Table Toys, Active Toys)."
)
product_code: str = Field(
description="The unique product code for the toy (e.g., GA457)."
)
toy_name: str = Field(description="The name of the toy.")
age_range: str = Field(
description="The recommended age range for the toy (e.g., 6+, 4+)."
)
player_range: str = Field(
description="The number of players the toy is designed for (e.g., 2, 2-4, 1-6)."
)
material: str = Field(
description="The primary material(s) the toy is made of (e.g., wood, cardboard)."
)
description: str = Field(
description="A brief description of the toy and its components and dimensions."
)
result = await llama_extract.aextract(
data_schema=ToyCatalog,
files="./Click-BS-Toys-Catalogue-2024.pdf",
config=ExtractConfig(
extraction_mode=ExtractMode.PREMIUM,
extraction_target=ExtractTarget.PER_TABLE_ROW,
parse_model="anthropic-sonnet-4.5",
),
)Results:
python
len(result.data) # 153 products
result.data[:3]
# [
# {
# 'section_name': 'Table Toys',
# 'product_code': 'GA457',
# 'toy_name': 'Dots and Boxes',
# 'age_range': '6+',
# 'player_range': '2',
# 'material': 'wood',
# 'description': 'base 17x17 cm\\\\n50 border pieces 4x1,2x0,3 cm\\\\n34 trees 2,6x1,4 cm'
# },
# {
# 'section_name': 'Table Toys',
# 'product_code': 'GA456',
# 'toy_name': '3 In a Row',
# 'age_range': '8+',
# 'player_range': '2',
# 'material': 'wood, pine, cardboard',
# 'description': 'base 24x22,5x2,5 cm\\\\n30 cards 5,5x5 cm\\\\n6 chips'
# },
# {
# 'section_name': 'Table Toys',
# 'product_code': 'GA467',
# 'toy_name': 'Which Cow am i?',
# 'age_range': '6+',
# 'player_range': '2',
# 'material': 'wood, beech',
# 'description': '2 cow bases 56x4x4,5 cm\\\\n16 cards 4x5 cm'
# }
# ]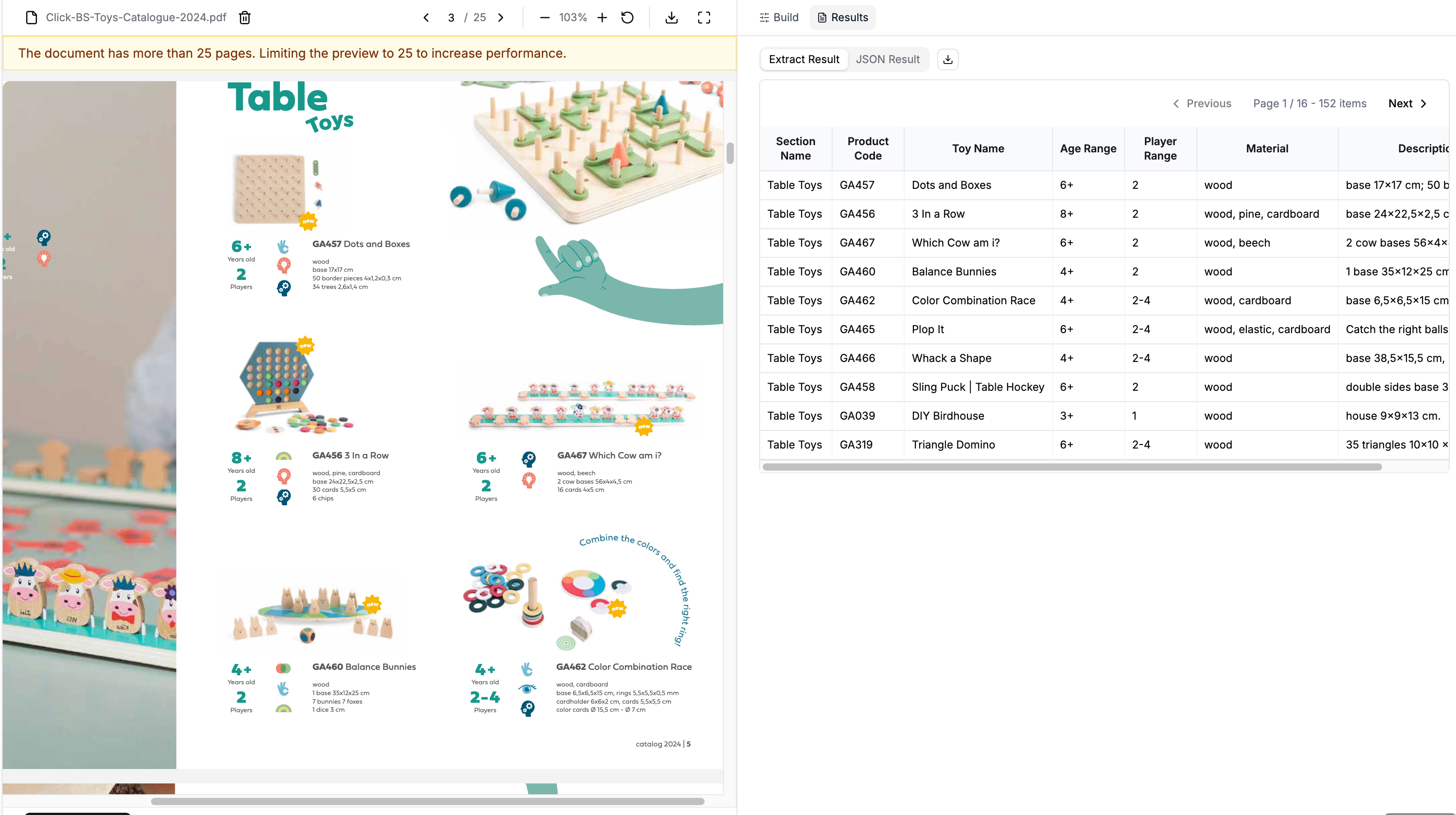
We get a full list of catalog items. The system detected the visual patterns that separate each product entry—section headers, spacing, consistent field ordering, and applied our schema to each one. Using PER_DOC , we were only able to retrieve 18 of the catalog items.
Key Takeaways for Tabular Extraction
1. Match extraction granularity to document structure
When you have repeating entities, define your schema for a single entity, not the whole document. The system will return list[YourSchema] with exhaustive coverage.
2. Row-level extraction works beyond tables
Any document with distinguishable repeating entities can work:
- Formal tables with rows and columns
- Bulleted or numbered lists
- Catalog entries with visual separation
- Sequential sections with consistent headers
The common requirement: each entity should contain all necessary information within its local context.
3. Automatic pattern detection is powerful
You don't need to tell the system "look for bullets" or "split on headers." LlamaExtract identifies formatting patterns automatically. Your job is to define what a single entity looks like in your schema.
4. Understanding the limitations:
PER_TABLE_ROW works when entities are self-contained. If you need to combine global document-level data with entity-level extraction (e.g., extract both "document title" and "list of all line items"), this target won't work well. We're exploring these hybrid use cases in future work.
Want to try this yourself? Check out the notebook for this example in our GitHub repository. Refer to the LlamaExtract documentation to get started.


