


StackAI Uses LlamaParse to Power High-Accuracy Retrieval for its Enterprise Document Agents
Background
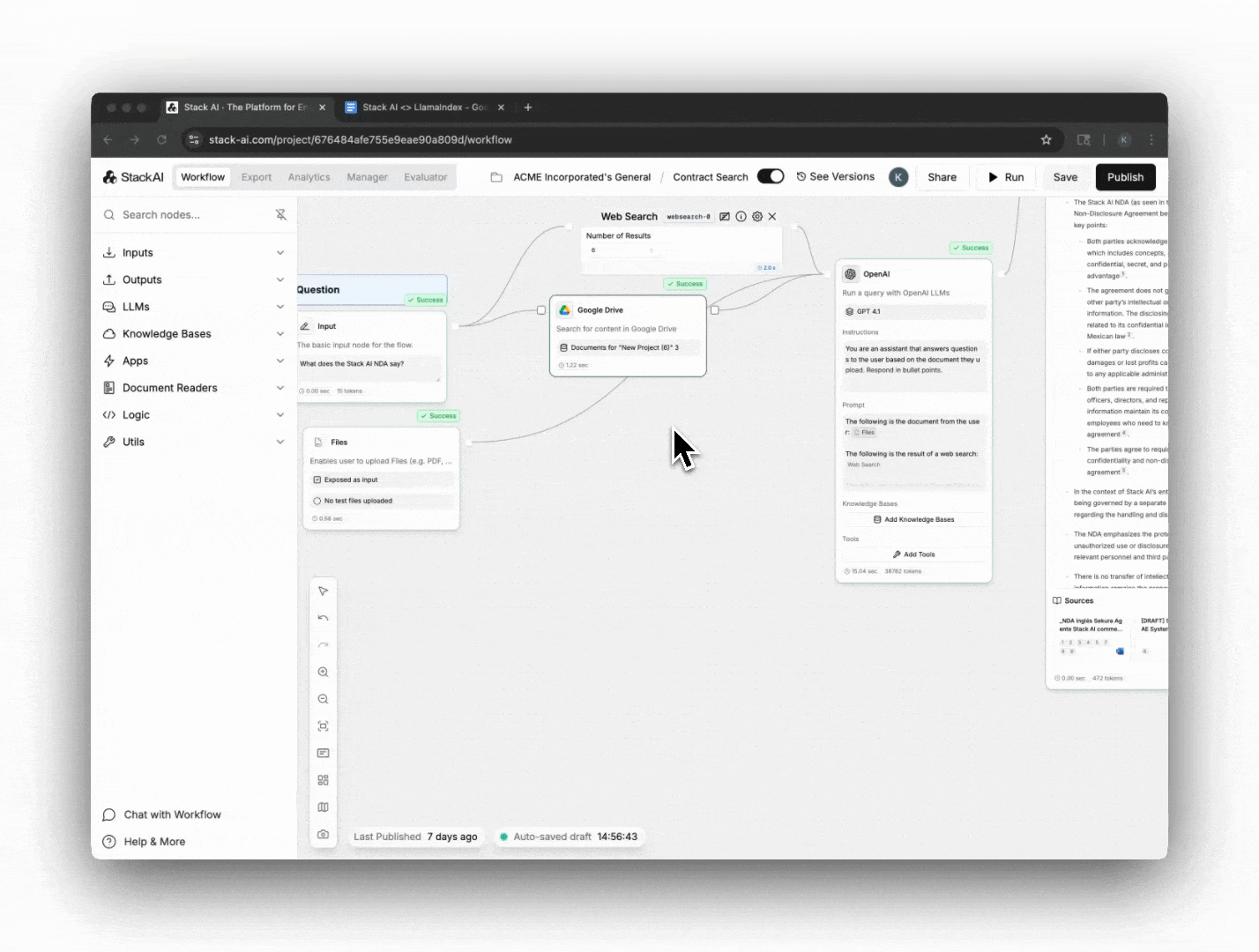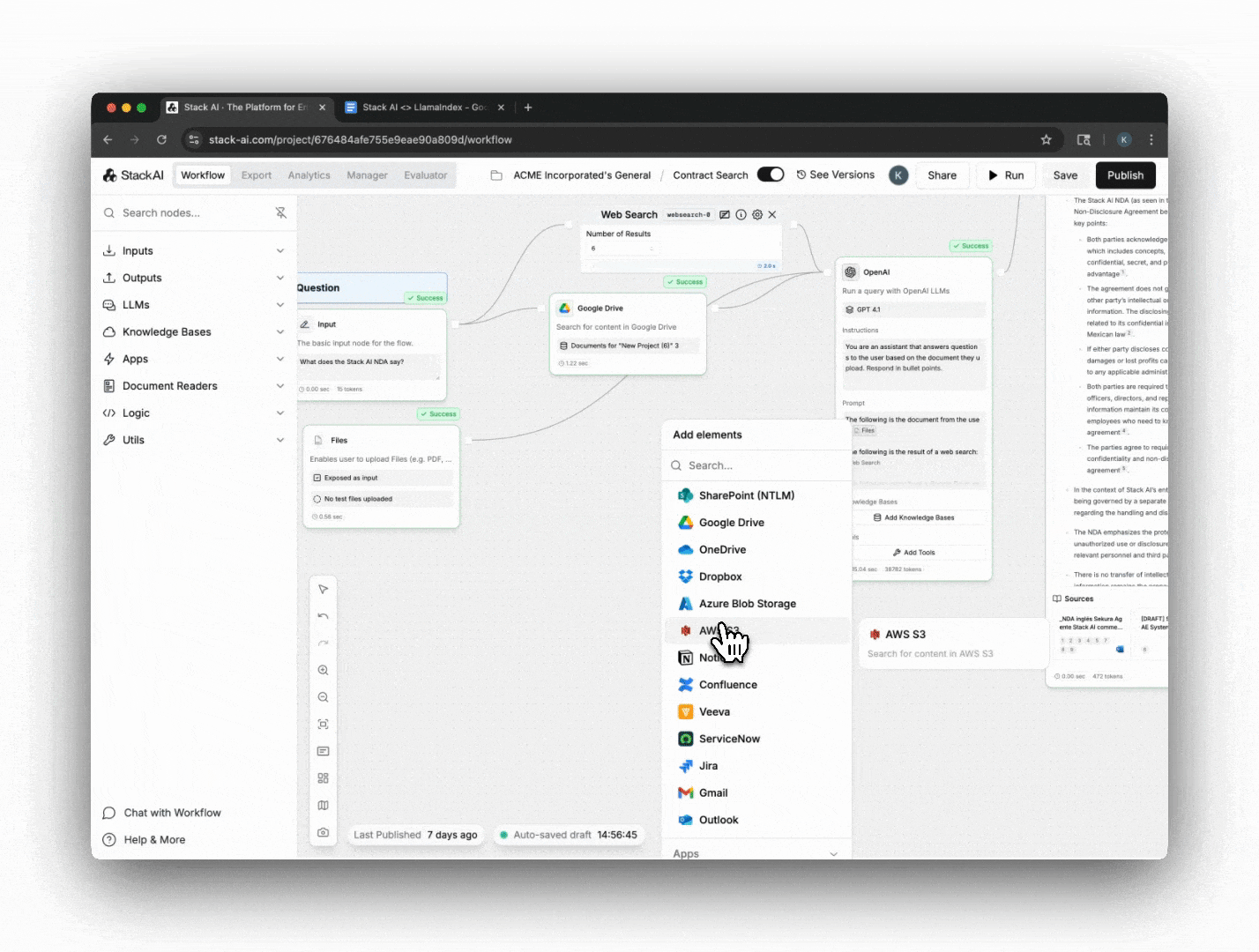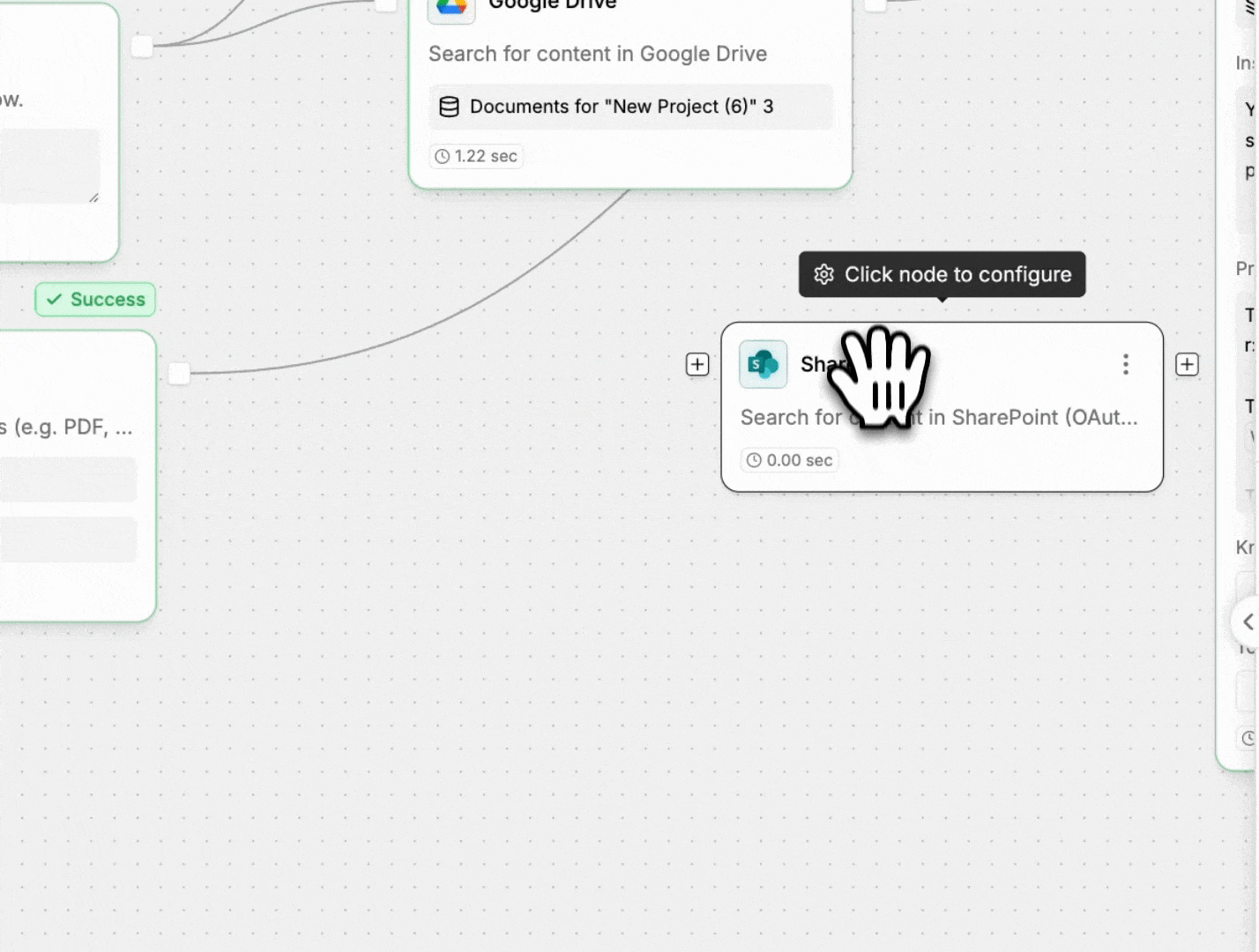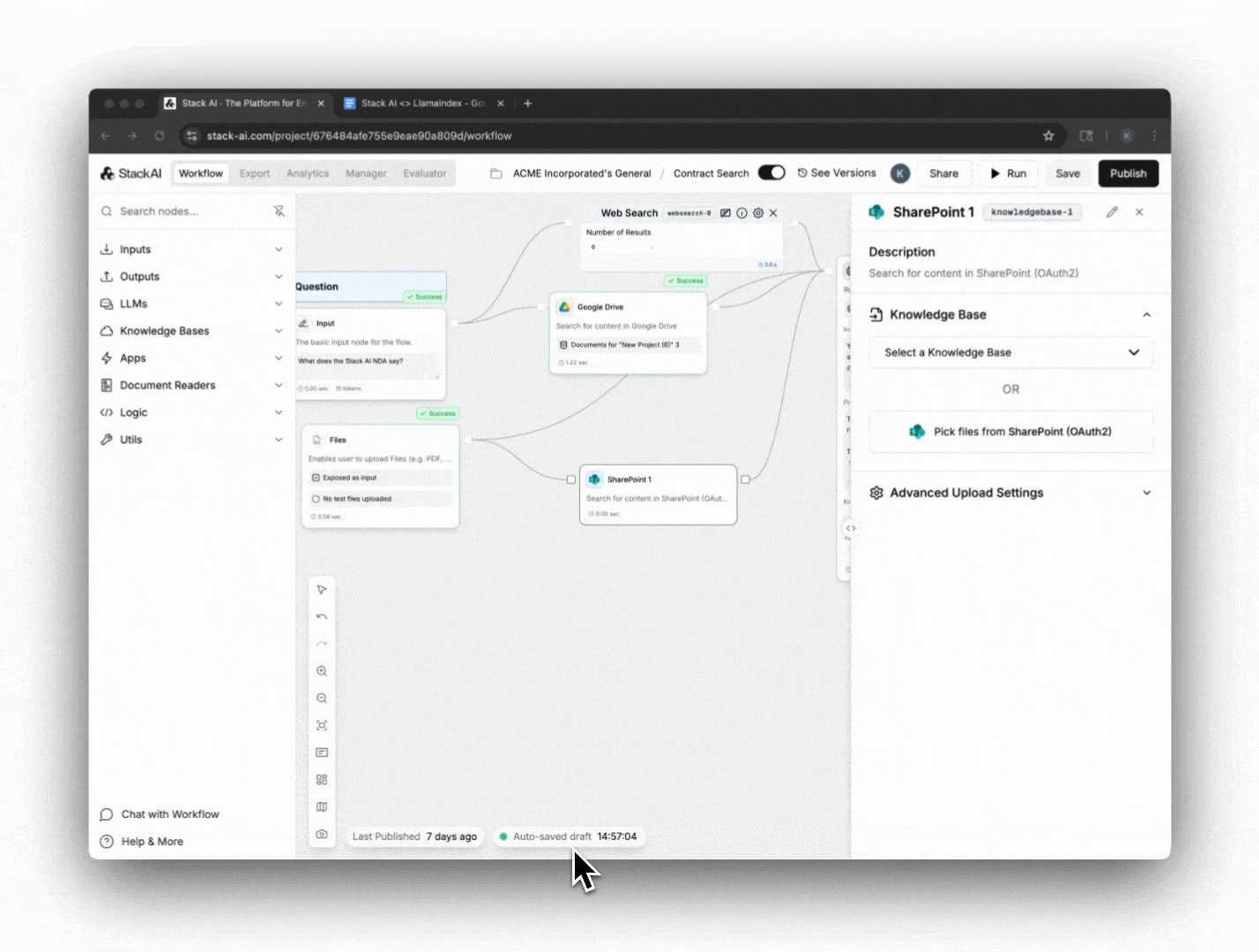
StackAI is an enterprise platform that enables organizations to build custom AI agents for diverse use cases—from IT ticket processing to financial analysis. Many of these agents rely on the ability to ingest, parse, and reason over large volumes of highly unstructured documents, such as scanned insurance forms, data room files, and financial statements. To deliver accurate, production-grade AI applications, StackAI needed a document processing foundation that was fast, reliable, and capable of scaling to millions of documents.
Problem
Before adopting LlamaParse, StackAI faced the challenge of processing unstructured, messy documents at both speed and scale. Customers often uploaded massive knowledge bases containing mixed file formats—PDFs, spreadsheets, images, and notes—that needed to be accurately parsed and transformed into structured, retrieval-ready data. The complexity was compounded by:
- Variability in document quality, including low-resolution scans and inconsistent layouts.
- High accuracy demands, since small parsing errors could cascade into downstream reasoning mistakes.
- Need for elastic scalability, as workloads ranged from small pilots to enterprise workflows with thousands of documents.
Before adopting LlamaParse, StackAI relied on basic PDF readers and tools like AWS Textract—but results were inconsistent, especially at scale. Parsing volumes of documents for LLM input or vector indexing was a major bottleneck.
Without a robust parsing layer, these challenges slowed agent deployment and risked degrading end-user trust.
Solution
StackAI integrated LlamaParse’s LlamaParse API directly into its agent development platform as the core document ingestion step. Using LlamaParse’s parsing capabilities, StackAI can:
- Process thousands of documents with high accuracy, from complex insurance forms to financial filings.
- Scale parsing dynamically, adjusting quality and speed settings based on workload and cost requirements.
- Maintain developer simplicity, connecting LlamaParse outputs directly into StackAI’s knowledge base architecture without custom parsing logic.
“It’s fast, the quality is good, and we can scale up and down depending on the level of quality we need.” — Bernard Aceituno, Co-Founder @ StackAI
With LlamaParse, StackAI’s agents now work with structured, high-fidelity data, even from challenging unstructured inputs. The first aha moment when the team realized they solved a major problem was when they uploaded a long bank report and could see all the data from the document clean and organized for an LLM to understand: text, charts, and tables.
Impact
Since adopting LlamaParse, the StackAI team has:
- Over 1 million documents processed for enterprise customers, powering knowledge bases across insurance, finance, and legal sectors.
- Significant accuracy gains in downstream AI agent performance, especially for scanned and low-quality documents.
- Reduced development overhead, allowing StackAI to focus on agent logic and customer-facing features instead of document preprocessing.
- Improved customer trust, with clients reporting better results from agents due to cleaner, more reliable data ingestion.
“Customers tell us our document parsing is ‘really, really good’—and that’s in large part thanks to LlamaParse.” — Bernard Aceituno, Co-Founder @ StackAI


