Organizations depend on structured data to drive analytics, compliance reporting, financial reconciliation, and operational automation. Yet a large portion of business-critical information remains confined within PDFs, scanned reports, invoices, and other documents. These documents frequently contain well-organized tables that are easy for humans to interpret but difficult for machines to process reliably.
A PDF is often little more than a digital rendering of structured content. What appears to be a clean grid of rows and columns is, at a technical level, a collection of positioned text fragments and graphical elements without explicit relational metadata. Systems that rely on standard text recognition can identify characters, but they cannot inherently reconstruct the relationships between cells, headers, and numeric values. As a result, structured information remains effectively trapped inside static documents.
OCR for tables addresses this constraint by converting visually structured tables into machine-readable formats such as JSON, CSV, or Excel. Modern implementations extend beyond basic optical character recognition and incorporate layout-aware processing, structural parsing, and schema-aligned extraction. This shift represents a broader transition from simple text recognition to intelligent document processing, where the objective is to reconstruct content in a way that preserves logical structure and enables reliable system integration.
Why Table Extraction Is Harder Than Standard OCR
Extracting paragraphs of text is fundamentally different from extracting tables. Traditional OCR processes text sequentially, interpreting characters and words in linear order. Tables, however, derive meaning from spatial relationships. A numeric value only becomes meaningful when interpreted relative to its column header and corresponding row.
This geometric dependency introduces risk. If a column boundary is misidentified, numeric values may shift into adjacent fields without obvious visual errors. A quantity could be interpreted as a price. A subtotal might be read as a line item. These structural misalignments can silently corrupt downstream datasets and propagate into financial systems.
Several structural factors compound this difficulty. Merged cells require hierarchical interpretation because a single header may span multiple columns. Multi-line rows must be preserved as a single logical record rather than fragmented into separate entries. Borderless tables rely on whitespace alignment instead of visible gridlines, making positional inference more complex for conventional OCR engines.
These characteristics illustrate why OCR for tables demands more than character detection. It requires coordinated layout analysis, structural reconstruction, contextual reasoning, and schema validation to ensure data integrity.
The Three Core Phases of Table Extraction
In production environments, reliable table extraction unfolds across three coordinated phases: detection, structure recognition, and data extraction.
The first phase, table detection, identifies where tabular content exists on a page. Computer vision models analyze alignment patterns, whitespace distribution, repeating numeric structures, and header positioning to determine bounding regions. Accurate detection is essential because downstream recognition depends on isolating structured regions from surrounding text.
The second phase, table structure recognition, reconstructs the grid. This involves identifying row boundaries, column divisions, header hierarchies, and merged regions. The system converts visual geometry into a logical coordinate system that defines how values relate to one another. Errors at this stage directly affect data alignment, even if character recognition is perfect.
The final phase, data extraction, applies OCR within each detected cell boundary and maps values to schema-defined fields. However, production-grade systems go further by incorporating validation logic. Arithmetic consistency checks, data-type validation, and cross-field consistency rules prevent structural misinterpretation from propagating into enterprise workflows.
This multi-phase architecture distinguishes modern table extraction from legacy OCR pipelines that treat documents as flat text.
Practical Example: Extracting Table Data from an Invoice
The invoice below illustrates how OCR for tables operates in a real-world context.

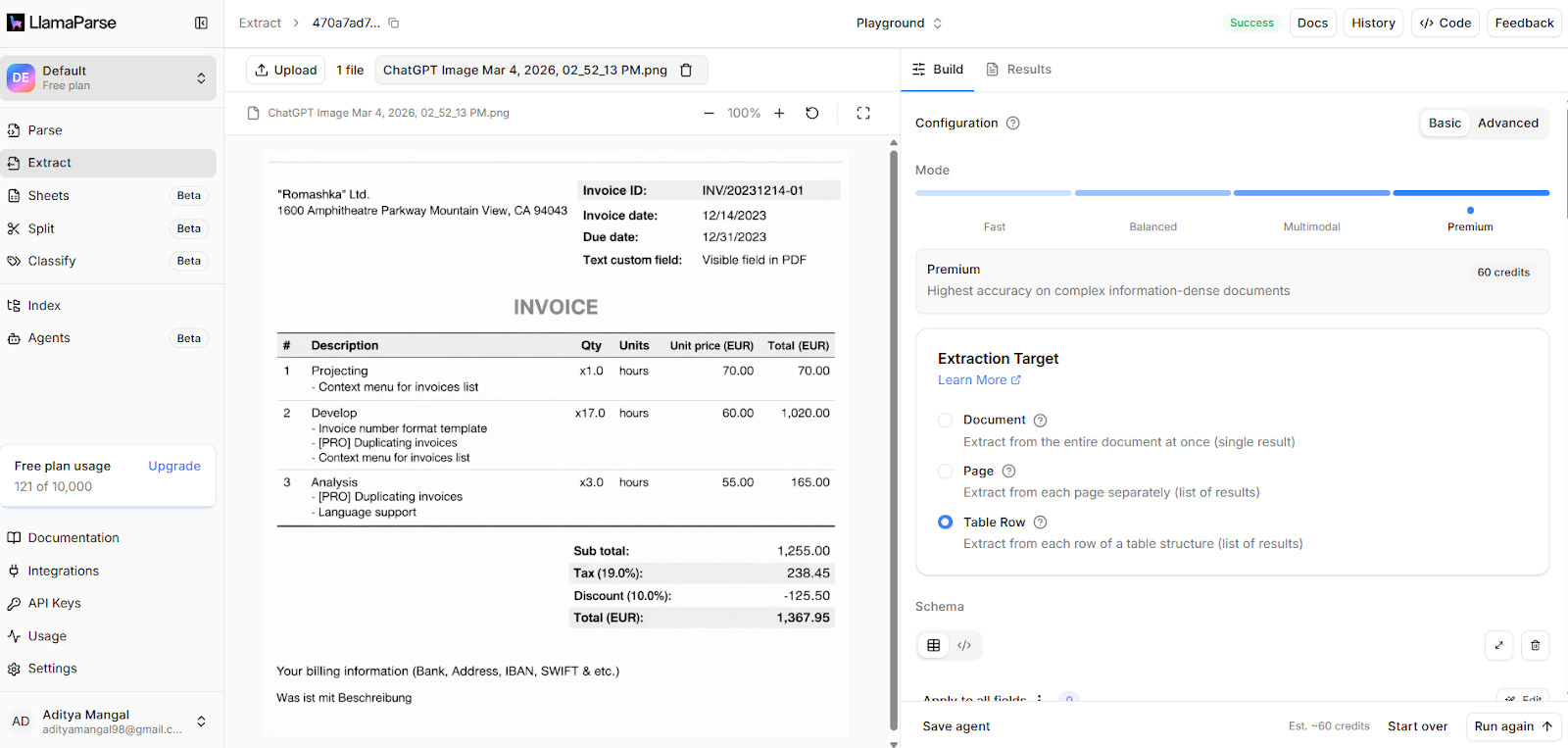
The document includes a structured line-item table composed of item numbers, descriptions, quantities, units, unit prices, and totals. Although visually organized, the PDF does not encode explicit row-column relationships. The table structure must be inferred through layout analysis.
When processed using LlamaParse, the workflow begins with ingestion and layout-aware detection. The system isolates the tabular region within the invoice body and separates it from surrounding metadata such as invoice identifiers and billing information.
Structural parsing then reconstructs row boundaries and column divisions. Multi-line descriptions remain attached to their corresponding row, preserving logical integrity. Header alignment ensures that numeric values map correctly to quantity, unit price, and total fields.
During extraction, values are assigned to a defined schema. For example:
html
[
{
"invoice_id": "INV/20231214-01",
"invoice_date": "12/14/2023",
"due_date": "12/31/2023",
"sender_company_name": "\"Romashka\" Ltd.",
"sender_company_address": "1600 Amphitheatre Parkway Mountain View, CA 94043",
"currency": "EUR",
"custom_field": {
"name": "Text custom field",
"value": "Visible field in PDF"
},
"line_items": [
{
"item_number": 1,
"description": "Projecting",
"notes": [
"Context menu for invoices list"
],
"quantity": {
"value": 1,
"unit": "hours"
},
"unit_price": 70,
"total_amount": 70
},
{
"item_number": 2,
"description": "Develop",
"notes": [
"Invoice number format template",
"[PRO] Duplicating invoices",
"Context menu for invoices list"
],
"quantity": {
"value": 17,
"unit": "hours"
},
"unit_price": 60,
"total_amount": 1020
},
{
"item_number": 3,
"description": "Analysis",
"notes": [
"[PRO] Duplicating invoices",
"Language support"
],
"quantity": {
"value": 3,
"unit": "hours"
},
"unit_price": 55,
"total_amount": 165
}
],
"sub_total": 1255,
"tax": {
"percentage": 19,
"amount": 238.45
},
"discount": {
"percentage": 10,
"amount": -125.5
},
"total_amount_due": 1367.95,
"payment_instructions": "Your billing information (Bank, Address, IBAN, SWIFT & etc.)"
}
]Subtotals, taxes, discounts, and final totals in the invoice can also be extracted and validated against computed values. This validation layer ensures arithmetic correctness before the data is synchronized with ERP systems or analytics pipelines.
Because LlamaParse preserves structural relationships rather than flattening text blocks, extracted table data remains logically aligned and immediately usable without post-processing scripts.
LlamaParse for OCR for Tables
LlamaParse provides a production-ready platform for extracting structured data from tables within complex documents. It integrates layout-aware detection, structural parsing, schema mapping, and validation orchestration within a unified pipeline.
Rather than treating tables as flat text segments, LlamaParse reconstructs their geometry and preserves header relationships, merged cell semantics, and row integrity. Structured JSON output enables direct integration with enterprise systems, analytics workflows, and vector databases.
Because LlamaParse operates within a broader intelligent document processing ecosystem, table extraction can be orchestrated alongside metadata indexing, confidence scoring, and downstream automation workflows. This coordinated architecture reduces fragmentation between OCR output and business logic, enabling reliable end-to-end automation.
Architectural Approaches to OCR for Tables
Several architectural strategies are used to extract table data, each with different trade-offs.
Template-driven systems rely on predefined positional rules. These approaches are effective for documents with fixed layouts but become fragile when formats change. Maintenance overhead increases as document variability grows.
Machine learning and computer vision models interpret layout patterns dynamically. By analyzing spatial relationships rather than fixed coordinates, these systems adapt to heterogeneous document formats, including scanned invoices and borderless tables.
Vision-language models represent an emerging approach in which large language models interpret visual table structures and generate schema-aligned output. This zero-shot extraction capability enables flexible processing across varied layouts. However, production environments still require structured validation layers to ensure numeric accuracy and governance compliance.
Improving Extraction Accuracy in Production
Extraction reliability depends on disciplined preprocessing. Deskewing, orientation correction, binarization, and noise reduction significantly improve layout detection performance, particularly for scanned documents.
Confidence scoring mechanisms determine when human review is required. A human-in-the-loop workflow ensures that ambiguous tables are validated before integration into operational systems, balancing automation efficiency with governance oversight.
Output normalization further strengthens system reliability. Dates, currencies, percentages, and numeric formats must be standardized to prevent downstream ingestion errors. Organizations should also evaluate performance across complex scenarios such as multi-page tables, nested header hierarchies, and borderless layouts to ensure resilience in real-world environments.
Industry Applications
OCR for tables plays an important role in industries where large volumes of structured information are embedded in operational documents. Many of these documents are distributed as PDFs or scanned files, which makes automated data processing difficult without reliable table extraction.
Financial Services
In financial services, table extraction is commonly used to process bank statements, transaction summaries, and reconciliation reports. Financial institutions frequently receive documents containing tabular transaction records that must be reconciled against internal accounting systems. By extracting structured data directly from these tables, organizations can automate reconciliation workflows, reduce manual data entry, and improve audit readiness. Structured extraction also helps detect inconsistencies in financial records by enabling automated validation across datasets.
Logistics and Supply Chain
In logistics and supply chain operations, OCR for tables is widely used to process documents such as bills of lading, shipment manifests, and customs declarations. These documents typically contain line-item tables describing quantities, product identifiers, shipment weights, and destination details. Extracting this information in structured form allows logistics systems to automatically update inventory records, track shipments, and synchronize operational data across supply chain platforms.
Healthcare
Healthcare organizations also rely on table extraction when processing medical reports, laboratory results, and patient documentation. Lab reports frequently present test results in tabular format, where each row represents a diagnostic measurement and its corresponding value range. Extracting this data accurately enables hospitals and healthcare providers to digitize patient records, integrate test results into electronic health systems, and support downstream analytics for medical research and clinical monitoring.
Conclusion
OCR for tables transforms visually structured documents into machine-actionable data by combining layout analysis, structural reconstruction, and schema-aligned extraction. Unlike standard OCR, it must preserve spatial relationships and validate logical consistency to ensure enterprise-grade reliability.
As organizations modernize document workflows, accurate table extraction becomes foundational to automation and analytics initiatives. LlamaParse provides a structured and production-ready approach to extracting table data while preserving integrity and enabling seamless downstream integration.
To explore how LlamaParse can support your workflows, feel free to review the platform documentation or request a tailored demonstration aligned with your document processing requirements.