


At first glance, receipts appear simple. They are typically short documents, often narrow in layout, and rarely extend beyond a few dozen line items. Because of this, they are frequently underestimated as easy OCR tasks.
And yet, receipts are one of the fastest ways to expose whether your document processing system is production-grade or held together by regex and hope.
In real-world automation systems, receipts are not an OCR problem, but rather a document intelligence problem.
Unfortunately, most legacy OCR stacks were not designed for this level of structural reliability. In this article, we’ll examine why traditional OCR pipelines break under real-world receipt variability, and what an agentic, architecture-first approach does differently.
The Illusion of “Good OCR”
Many teams evaluate receipt extraction by asking: “Did we get the text out?”
That’s the wrong question.
The right question is: “Can we reliably reconstruct structured financial data across thousands of variable layouts without constant rule maintenance?”
In production systems, extraction is not the goal, but rather, automation is. Automation begins to degrade when line items no longer remain grouped correctly, totals are misidentified or confused with card amounts, merchant names are only partially detected, or when multi-line descriptions drift away from their associated prices. In large-scale receipt processing environments, these conditions occur regularly and lead to compounding downstream complexity.
Traditional OCR engines are optimized for character transcription rather than structural interpretation. They return text, but do not preserve relationships between fields, numeric hierarchies, or the layout-based groupings. The result is a flat text output that downstream systems must reinterpret and normalize.
When structure is not preserved during extraction, teams end up compensating with manual checks and extra rules downstream.
Why Receipts Are a Stress Test for Document Systems
Receipts are deceptively small financial documents with almost no standardization. Unlike invoices or tax forms, there is no consistent template governing how merchants structure line items, totals, taxes, or payment details. In fact, it’s not uncommon for two receipts from the same retailer to vastly differ from one another.
They also come with structural and visual complexity. For instance, line items are often abbreviated, descriptions wrap unpredictably, and multiple numeric values appear close together without clear labels. Logos and stylized fonts introduce visual noise, while images captured with mobile tend to add skew and uneven lighting. Over time, thermal printing reduces contrast and legibility.
All in all, they are challenging for systems built on positional assumptions or rule-based post-processing. What works for one template often fails for the next. As the number of merchants grows, so does the volume of edge cases, and maintaining accuracy turns into a constant process of adding new rules.
Rethinking the Architecture: From OCR Pipelines to Parsing with AI Agents
Traditional document stacks follow a familiar pattern:
OCR → Heuristics → Regex → Cleanup → Validation → Manual Corrections
When layouts shift or formatting changes, teams typically respond by adding new rules or expanding prompts. Over time, the effort required to maintain these adjustments can exceed the cost of the original extraction.
LlamaCloud approaches this differently. It operates as a unified, VLM-powered agentic OCR engine that performs visual recognition, layout understanding, structural reasoning, and validation within a single coordinated system. This results in:
- Layout-aware computer vision segments document regions
- Vision-language models interpret complex visual elements
- Language models reason about structure and grouping
- Deployment of the right specialist model for the task (charts, text, tables, etc.)
- Validation loops check numeric consistency
- Smart reconstruction produces structured JSON, Markdown, or HTML
The output is structured, validated, AI-ready data, rather than flat text.
Hands-On Example: Real Receipt, Real Conditions
To evaluate this approach, we processed multiple real retail receipts under typical conditions:
- Slight skew
- Uneven lighting
- Mixed line-item formatting
- Subtotal, tax, and grand total fields
- Embedded merchant branding
Ingestion Through LlamaCloud
The document was uploaded directly into LlamaCloud’s parsing environment.
OCR is not a separate preprocessing step. Within LlamaParse, visual recognition, layout understanding, structural reasoning, and structured reconstruction operate as a unified, VLM-powered agentic system—producing structured outputs directly.
In other words, parsing and structured extraction occur within the same coordinated engine.
Instead of flat text, the output preserved:
- Merchant name
- Date and timestamp
- Ordered line items
- Associated prices
- Subtotal
- Tax
- Final total
- Structured JSON output
Line items remained grouped correctly even when descriptions wrapped across lines.
Totals were distinguished semantically—not just by numeric magnitude.
Full JSON -> output.json
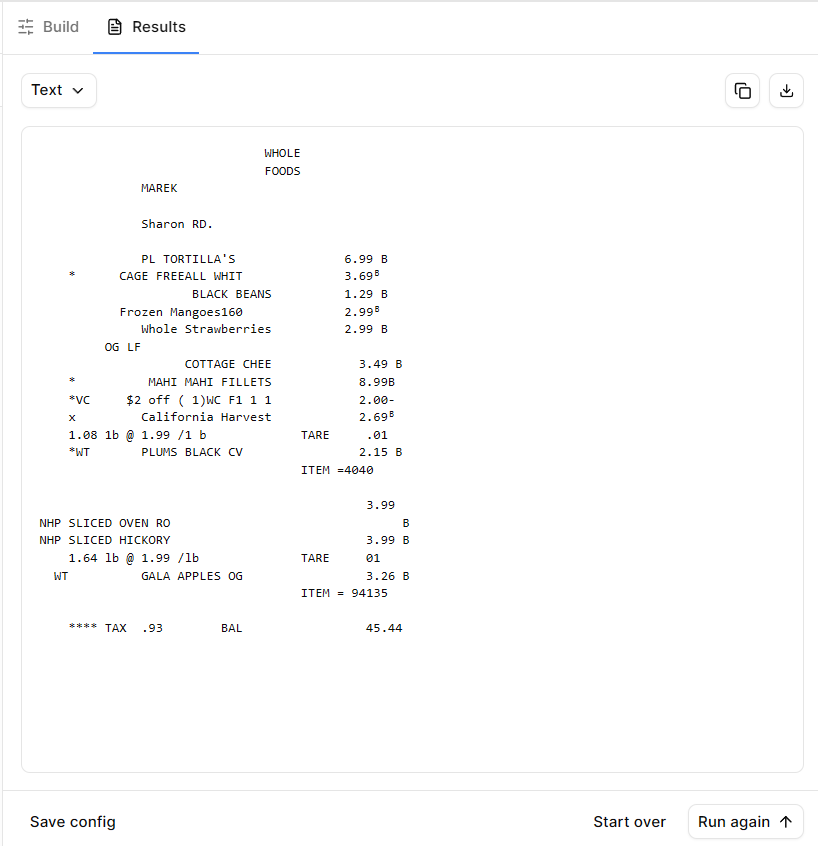
Each extracted field is returned with associated metadata and confidence signals, enabling human-in-the-loop validation when needed.
Where Agentic Parsing Outperforms Traditional OCR
The difference between traditional OCR and agentic parsing is most apparent when layout complexity increases. Beyond character accuracy, the key measure is whether structure and field relationships are preserved and validated before downstream use.
To be more precise, here’s how agentic OCR trumps traditional tools:
- Layout Awareness: Header, body, and footer sections remain intact rather than flattened.
- Line Item Grouping: Wrapped descriptions stay attached to correct prices.
- Semantic Totals Detection: The engine distinguishes subtotal vs grand total using reasoning, not just pattern matching.
- Validation Loops: Numeric totals are checked for internal consistency.
- Verifiable Outputs: Confidence scores and metadata support human-in-the-loop review.
The above factors eliminate the need for brittle downstream normalization logic.
This shift materially changes the economics of document automation by reducing downstream rule maintenance and increasing straight-through processing reliability.
Traditional OCR systems attempt to extract text and then rely on downstream systems to repair errors. LlamaCloud reverses that model. It combines state-of-the-art agentic OCR, layout-aware computer vision, multi-model orchestration, and structured validation into a single coordinated engine, reducing downstream rule maintenance and increasing straight-through processing.
Traditional OCR systems focus primarily on character extraction. When layouts shift, these systems often require retraining, new templates, or additional downstream correction logic. They also struggle when receipts contain embedded visuals, unusual formatting, or inconsistent spacing.
In contrast, an agentic document parsing approach treats the document as a structured object from the outset. Layout understanding, multi-model coordination, validation logic, and structured reconstruction are integrated within a single system, reducing reliance on brittle post-processing layers.
What This Means for Production Systems
Teams building systems like expense automation platforms, accounting ingestion pipelines, audit workflows, etc. require structured reliability at scale. These systems depend on consistently reconstructed financial data that can move directly into ledgers and reporting tools—minus manual review.
When ingestion, reasoning, validation, and reconstruction happen within one coordinated system, downstream systems become simpler with fewer rules, breakages, and higher straight-through processing rates. As a result, engineering effort shifts from constant repair work to expanding coverage and hardening the system
Final Perspective
Although receipts are relatively small documents, they frequently expose architectural weaknesses in document processing systems at scale. Systems built on brittle OCR pipelines accumulate rules. Systems built on agentic document parsing accumulate reliability.
LlamaParse represents that architectural shift, with a unified, VLM-powered agentic OCR engine designed to produce structured, validated outputs directly and support end-to-end document agents without fragile post-processing layers.