


Authors: Avthar Sewrathan, Matvey Arye, Jerry Liu, Yi Ding
Introducing the Timescale Vector integration for LlamaIndex. Timescale Vector enables LlamaIndex developers to build better AI applications with PostgreSQL as their vector database: with faster vector similarity search, efficient time-based search filtering, and the operational simplicity of a single, easy-to-use cloud PostgreSQL database for not only vector embeddings but an AI application’s relational and time-series data too.
PostgreSQL is the world’s most loved database, according to the Stack Overflow 2023 Developer Survey. And for a good reason: it’s been battle-hardened by production use for over three decades, it’s robust and reliable, and it has a rich ecosystem of tools, drivers, and connectors.
And while pgvector, the open-source extension for vector data on PostgreSQL, is a wonderful extension (and all its features are offered as part of Timescale Vector), it is just one piece of the puzzle in providing a production-grade experience for AI application developers on PostgreSQL. After speaking with numerous developers at nimble startups and established industry giants, we saw the need to enhance pgvector to cater to the performance and operational needs of developers building AI applications.
Here’s the TL;DR on how Timescale Vector helps you build better AI applications with LlamaIndex:
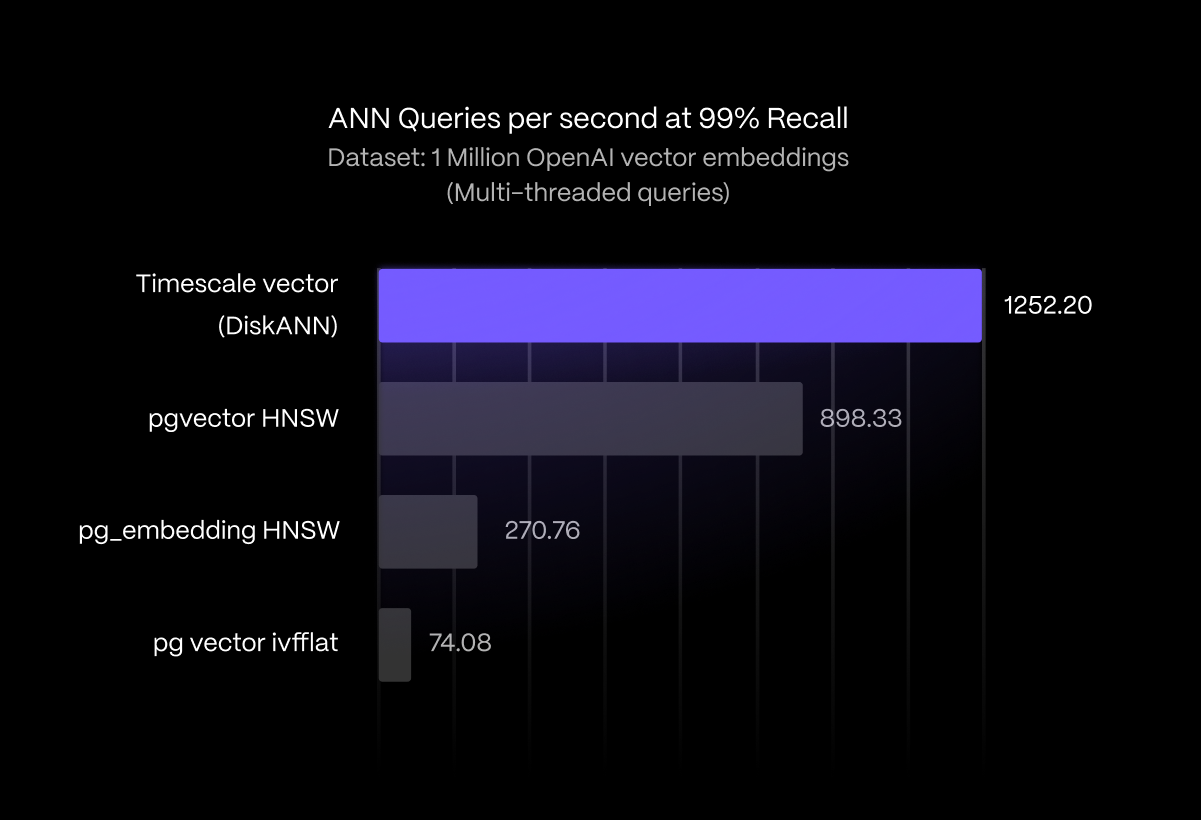
- Faster similarity search on millions of vectors: Thanks to the introduction of a new search index inspired by the DiskANN algorithm, Timescale Vector achieves 3X faster search speed at ~99% recall than a specialized database and outperforms all existing PostgreSQL search indexes by between 39.39% and 1,590.33% on a dataset of one million OpenAI embeddings. Plus, enabling product quantization yields a 10x index space savings compared to pgvector. Timescale Vector also offers pgvector’s Hierarchical Navigable Small Worlds (HNSW) and Inverted File Flat (IVFFlat) indexing algorithms.
- Efficient similarity search with time-based filtering: Timescale Vector optimizes time-based vector search queries, leveraging the automatic time-based partitioning and indexing of Timescale’s hypertables to efficiently find recent embeddings, constrain vector search by a time range or document age, and store and retrieve large language model (LLM) response and chat history with ease. Time-based semantic search also enables you to use Retrieval Augmented Generation (RAG) with time-based context retrieval to give users more useful LLM responses.
- Simplified AI infra stack: By combining vector embeddings, relational data, and time-series data in one PostgreSQL database, Timescale Vector eliminates the operational complexity that comes with managing multiple database systems at scale.
- Simplified metadata handling and multi-attribute filtering: Developers can leverage all PostgreSQL data types to store and filter metadata and JOIN vector search results with relational data for more contextually relevant responses. In future releases, Timescale Vector will further optimize rich multi-attribute filtering, enabling even faster similarity searches when filtering on metadata.
On top of these innovations for vector workloads, Timescale Vector provides a robust, production-ready cloud PostgreSQL platform with flexible pricing, enterprise-grade security, and free expert support.
In the rest of this post, we’ll dive deeper (with code!) into the unique capabilities Timescale Vector enables for developers wanting to use PostgreSQL as their vector database with LlamaIndex:
- Faster similarity search with DiskANN, HNSW and IVFFlat index types.
- Efficient similarity search when filtering vectors by time.
- Retrieval Augmented Generation (RAG) with time-based context retrieval.
(If you want to jump straight to the code, explore this tutorial).
🎉 LlamaIndex Users Get 3 Months of Timescale Vector for Free
We’re giving LlamaIndex users an extended 90-day trial of Timescale Vector. This makes it easy to test and develop your applications on Timescale Vector, as you won’t be charged for any cloud PostgreSQL databases you spin up during your trial period. Try Timescale Vector for free today.
Faster Vector Similarity Search in PostgreSQL
Timescale Vector speeds up Approximate Nearest Neighbor (ANN) search on large-scale vector datasets, enhancing pgvector with a state-of-the-art ANN index inspired by the DiskANN algorithm. Timescale Vector also offers pgvector’s HNSW and IVFFlat indexing algorithms, giving developers the flexibility to choose the right index for their use case.
Our performance benchmarks using the ANN benchmarks suite show that Timescale Vector achieves between 39.43% and 1,590.33% faster search speed at ~99% recall than all existing PostgreSQL search indexes, and 3X faster search speed at ~99% recall than specialized vector databases on a dataset of one million OpenAI embeddings. You can read more about the performance benchmark methodology, the databases compared and results here.
Using Timescale Vector’s DiskANN, HNSW, or IVFFLAT indexes in LlamaIndex is incredibly straightforward.
Simply create a Timescale Vector vector store and add the data nodes you want to query as shown below:
from llama_index.vector_stores import TimescaleVectorStore
# Create a timescale vector store with specified params
ts_vector_store = TimescaleVectorStore.from_params(
service_url=TIMESCALE_SERVICE_URL,
table_name="your_table_name",
time_partition_interval= timedelta(days=7),
)
ts_vector_store.add(nodes)Then run:
# Create a timescale vector index (DiskANN)
ts_vector_store.create_index()This will create a timescale-vector index with the default parameters.
We should point out that the term “index” is a bit overloaded. For many VectorStores, an index is the thing that stores your data (in relational databases this is often called a table), but in the PostgreSQL world an index is something that speeds up search, and we are using the latter meaning here.
We can also specify the exact parameters for index creation in the create_index command as follows:
# create new timescale vector index (DiskANN) with specified parameters
ts_vector_store.create_index("tsv", max_alpha=1.0, num_neighbors=50)Advantages to this Timescale Vector’s new DiskANN-inspired vector search index include the following:
- Faster vector search at 99% accuracy in PostgreSQL.
- Optimized for running on disks, not only in memory use.
- Quantization optimization compatible with PostgreSQL, reducing the vector size and consequently shrinking the index size (by 10x in some cases!) and expediting searches.
- Efficient hybrid search or filtering additional dimensions.
For more on how Timescale Vector’s new index works, see this blog post.
Pgvector is packaged as part of Timescale Vector, so you can also access pgvector’s HNSW and IVFFLAT indexing algorithms in your LlamaIndex applications. The ability to conveniently create ANN search indexes from your LlamaIndex application code makes it easy to create different indexes and compare their performance:
# Create an HNSW index
# Note: You don't need to specify m and ef_construction parameters as we set smart defaults.
ts_vector_store.create_index("hnsw", m=16, ef_construction=64)
# Create an IVFFLAT index
# Note: You don't need to specify num_lists and num_records parameters as we set smart defaults.
ts_vector_store.create_index("ivfflat", num_lists=20, num_records=1000)Add Efficient Time-Based Search Functionality to Your LlamaIndex AI Application
Timescale Vector optimizes time-based vector search, leveraging the automatic time-based partitioning and indexing of Timescale’s hypertables to efficiently search vectors by time and similarity.
Time is often an important metadata component for vector embeddings. Sources of embeddings, like documents, images, and web pages, often have a timestamp associated with them, for example, their creation date, publishing date, or the date they were last updated, to name but a few.
We can take advantage of this time metadata in our collections of vector embeddings to enrich the quality and applicability of search results by retrieving vectors that are not just semantically similar but also pertinent to a specific time frame.
Here are some examples where time-based retrieval of vectors can improve your LlamaIndex applications:
- Finding recent embeddings: Finding the most recent embeddings that are semantically similar to a query vector. For example, finding the most recent news, documents, or social media posts related to elections.
- Search within a time-range: Constraining similarity search to only vectors within a relevant time range. For example, asking time-based questions about a knowledge base (“What new features were added between January and March 2023?”).
- Chat history: Storing and retrieving LLM response history. For example, chatbot chat history.
Let’s take a look at an example of performing time-based searches on a git log dataset. In a git log, each entry has a timestamp, an author, and some information about the commit.
To illustrate how to use TimescaleVector’s time-based vector search functionality, we’ll ask questions about the git log history for TimescaleDB. Each git commit entry has a timestamp associated with it, as well as a message and other metadata (e.g., author).
We’ll illustrate how to create nodes with a time-based UUID and how to run similarity searches with time range filters using the Timescale Vector vector store..
Create nodes from each commit in the gitlog
First, we load the git log entries from the demo CSV file using Pandas:
import pandas as pd
from pathlib import Path
# Read the CSV file into a DataFrame
file_path = Path("../data/csv/commit_history.csv")
df = pd.read_csv(file_path)Next, we’ll create nodes of type `TextNode` for each commit in our git log dataset, extracting the relevant information and assigning it to the node’s text and metadata, respectively.
from llama_index.schema import TextNode, NodeRelationship, RelatedNodeInfo
# Create a Node object from a single row of data
def create_node(row):
record = row.to_dict()
record_name = split_name(record["author"])
record_content = str(record["date"]) + " " + record_name + " " + str(record["change summary"]) + " " + str(record["change details"])
node = TextNode(
id_=create_uuid(record["date"]),
text= record_content,
metadata={
'commit': record["commit"],
'author': record_name,
'date': create_date(record["date"]),
}
)
return node
nodes = [create_node(row) for _, row in df.iterrows()]Note: The code above references two helper functions to get things in the right format (`split_name()` and `create_date()`), which we’ve omitted for brevity. The full code is included in the tutorial linked in the Resources section at the end of this post.
Create UUIDs for each node based on the date of each git commit
We will take a closer look at a helper function we use to create each node’s id_. For time-based search in LlamaIndex, Timescale Vector uses the ‘datetime’ portion of a UUID v1 to place vectors in the correct time partition. Timescale Vector’s Python client library provides a simple-to-use function named `uuid_from_time` to create a UUID v1 from a Python DateTime object, which we’ll then use as our `ids` for the TextNodes.
from timescale_vector import client
# Function to take in a date string in the past and return a uuid v1
def create_uuid(date_string: str):
if date_string is None:
return None
time_format = '%a %b %d %H:%M:%S %Y %z'
datetime_obj = datetime.strptime(date_string, time_format)
uuid = client.uuid_from_time(datetime_obj)
return str(uuid)Since we are dealing with timestamps in the past, we take advantage of the `uuid_from_time` function to help generate the correct UUIDs for each node. If you want the current date and time associated with your Nodes (or Documents) for time-based search, you can skip this step. A UUID associated with the current date and time will be automatically generated as the nodes are added to the table in Timescale Vector by default.
Let’s take a look at the contents of a node:
print(nodes[0].get_content(metadata_mode="all"))commit: 44e41c12ab25e36c202f58e068ced262eadc8d16
author: Lakshmi Narayanan Sreethar
date: 2023-09-5 21:03:21+0850
Tue Sep 5 21:03:21 2023 +0530 Lakshmi Narayanan Sreethar Fix segfault in set_integer_now_func When an invalid function oid is passed to set_integer_now_func, it finds out that the function oid is invalid but before throwing the error, it calls ReleaseSysCache on an invalid tuple causing a segfault. Fixed that by removing the invalid call to ReleaseSysCache. Fixes #6037Create vector embeddings for the text of each node
Next, we’ll create vector embeddings of the content of each node so that we can perform similarity searches on the text associated with each node. We’ll use the `OpenAIEmbedding` model to create the embeddings.
# Create embeddings for nodes
from llama_index.embeddings import OpenAIEmbedding
embedding_model = OpenAIEmbedding()
for node in nodes:
node_embedding = embedding_model.get_text_embedding(
node.get_content(metadata_mode="all")
)
node.embedding = node_embeddingLoad nodes into Timescale Vector vector store
Next, we’ll create a `TimescaleVectorStore` instance and add the nodes we created to it.
# Create a timescale vector store and add the newly created nodes to it
ts_vector_store = TimescaleVectorStore.from_params(
service_url=TIMESCALE_SERVICE_URL,
table_name="li_commit_history",
time_partition_interval= timedelta(days=7),
)
ts_vector_store.add(nodes)To take advantage of Timescale Vector’s efficient time-based search, we need to specify the `time_partition_interval` argument when instantiating a Timescale Vector vector store. This argument represents the length of each interval for partitioning the data by time. Each partition will consist of data that falls within the specified length of time.
In the example above, we use seven days for simplicity, but you can pick whatever value makes sense for the queries used by your application — for example, if you query recent vectors frequently, you might want to use a smaller time delta like one day, or if you query vectors over a decade-long time period, then you might want to use a larger time delta like six months or one year. As a rule of thumb, common queries should touch only a couple of partitions and at the same time your full dataset should fit within a 1000 partitions, but don’t stress too much — the system is not very sensitive to this value.
Similarity search with time filters
Now that we’ve loaded our nodes that contain vector embeddings data and metadata into a Timescale Vector vector store, and enabled automatic time-based partitioning on the table our vectors and metadata are stored in, we can query our vector store with time-based filters as follows:
# Query the vector database
vector_store_query = VectorStoreQuery(query_embedding = query_embedding, similarity_top_k=5)
# Time filter variables for query
start_dt = datetime(2023, 8, 1, 22, 10, 35) # Start date = 1 August 2023, 22:10:35
end_dt = datetime(2023, 8, 30, 22, 10, 35) # End date = 30 August 2023, 22:10:35
# return most similar vectors to query between start date and end date date range
# returns a VectorStoreQueryResult object
query_result = ts_vector_store.query(vector_store_query, start_date = start_dt, end_date = end_dt)Let’s take a look at the date and contents of the nodes returned by our query:
# for each node in the query result, print the node metadata date
for node in query_result.nodes:
print("-" * 80)
print(node.metadata["date"])
print(node.get_content(metadata_mode="all"))--------------------------------------------------------------------------------
2023-08-3 14:30:23+0500
commit: 7aeed663b9c0f337b530fd6cad47704a51a9b2ec
author: Dmitry Simonenko
date: 2023-08-3 14:30:23+0500
Thu Aug 3 14:30:23 2023 +0300 Dmitry Simonenko Feature flags for TimescaleDB features This PR adds..
--------------------------------------------------------------------------------
2023-08-29 18:13:24+0320
commit: e4facda540286b0affba47ccc63959fefe2a7b26
author: Sven Klemm
date: 2023-08-29 18:13:24+0320
Tue Aug 29 18:13:24 2023 +0200 Sven Klemm Add compatibility layer for _timescaledb_internal functions With timescaledb 2.12 all the functions present in _timescaledb_internal were…
--------------------------------------------------------------------------------
2023-08-22 12:01:19+0320
commit: cf04496e4b4237440274eb25e4e02472fc4e06fc
author: Sven Klemm
date: 2023-08-22 12:01:19+0320
Tue Aug 22 12:01:19 2023 +0200 Sven Klemm Move utility functions to _timescaledb_functions schema To increase schema security we do not want to mix…
--------------------------------------------------------------------------------
2023-08-29 10:49:47+0320
commit: a9751ccd5eb030026d7b975d22753f5964972389
author: Sven Klemm
date: 2023-08-29 10:49:47+0320
Tue Aug 29 10:49:47 2023 +0200 Sven Klemm Move partitioning functions to _timescaledb_functions schema To increase schema security…
--------------------------------------------------------------------------------
2023-08-9 15:26:03+0500
commit: 44eab9cf9bef34274c88efd37a750eaa74cd8044
author: Konstantina Skovola
date: 2023-08-9 15:26:03+0500
Wed Aug 9 15:26:03 2023 +0300 Konstantina Skovola Release 2.11.2 This release contains bug fixes since the 2.11.1 release…Success! Notice how only vectors with timestamps within the specified start and end date ranges of 1 August, 2023, and 30 August, 2023, are included in the results.
Here’s some intuition for why Timescale Vector’s time-based partitioning speeds up ANN queries with time-based filters.
Timescale Vector partitions the data by time and creates ANN indexes on each partition individually. Then, during search, we perform a three-step process:
- Step 1: filter our partitions that don’t match the time predicate.
- Step 2: perform the similarity search on all matching partitions.
- Step 3: combine all the results from each partition in step 2, rerank, and filter out results by time.
Timescale Vector leverages TimescaleDB’s hypertables, which automatically partition vectors and associated metadata by a timestamp. This enables efficient querying on vectors by both similarity to a query vector and time, as partitions not in the time window of the query are ignored, making the search a lot more efficient by filtering out whole swaths of data in one go.
When performing a vector similarity search on `TimescaleVectorStore`, rather than specifying the start and end dates for our search, we can also specify a time filter with a provided start date and time delta later:
# return most similar vectors to query from start date and a time delta later
query_result = ts_vector_store.query(vector_store_query, start_date = start_dt, time_delta = td)And we can specify a time filter within a provided end_date and time delta earlier. This syntax is very useful for filtering your search results to contain vectors before a certain date cutoff.
# return most similar vectors to query from end date and a time delta earlier
query_result = ts_vector_store.query(vector_store_query, end_date = end_dt, time_delta = td)Powering Retrieval Augmented Generation With Time-Based Context Retrieval in LlamaIndex Applications With Timescale Vector
Let’s put everything together and look at how to use the TimescaleVectorStore to power RAG on the git log dataset we examined above.
To do this, we can use the TimescaleVectorStore as a QueryEngine. When creating the query engine, we use TimescaleVector’s time filters to constrain the search to a relevant time range by passing our time filter parameters as `vector_strore_kwargs`.
from llama_index import VectorStoreIndex
from llama_index.storage import StorageContext
index = VectorStoreIndex.from_vector_store(ts_vector_store)
query_engine = index.as_query_engine(vector_store_kwargs = ({"start_date": start_dt, "end_date":end_dt}))
query_str = "What's new with TimescaleDB functions? When were these changes made and by whom?"
response = query_engine.query(query_str)
print(str(response))We asked the LLM a question about our gitlog, namely, “What’s new with TimescaleDB functions. When were these changes made and by whom?”
Here’s the response we get, which synthesizes the nodes returned from semantic search with time-based filtering on the Timescale VectorStore:
TimescaleDB functions have undergone changes recently. These changes include the addition of several GUCs (Global User Configuration) that allow for enabling or disabling major TimescaleDB features. Additionally, a compatibility layer has been added for the "_timescaledb_internal" functions, which were moved into the "_timescaledb_functions" schema to enhance schema security. These changes were made by Dmitry Simonenko and Sven Klemm. The specific dates of these changes are August 3, 2023, and August 29, 2023, respectively.This is a simple example of a powerful concept — using time-based context retrieval in your RAG applications can help provide more relevant answers to your users. This time-based context retrieval can be helpful to any dataset with a natural language and time component. Timescale Vector uniquely enables this thanks to its efficient time-based similarity search capabilities, and taking advantage of it in your LlamaIndex application is easy thanks to the Timescale Vector integration.
Resources and next steps
Now that you’ve learned how Timescale Vector can help you power better AI applications with PostgreSQL, it’s your turn to dive in. Take the next step in your learning journey by following one of the tutorials or reading one of the blog posts in the resource set below:
- Up and Running Tutorial: learn how to use Timescale Vector in LlamaIndex using a real-world dataset. You’ll learn how to use Timescale Vector as a Vectorstore, Retriever, and QueryEngine and perform time-based similarity search on vectors.
- Timescale Vector explainer: learn more about the internals of Timescale Vector.
- Timescale Vector website: learn more about Timescale Vector and Timescale’s AI Launch Week.
🎉 And a reminder: LlamaIndex Users get Timescale Vector free for 90 days
We’re giving LlamaIndex users an extended 90-day trial of Timescale Vector. This makes it easy to test and develop your applications on Timescale Vector, as you won’t be charged for any cloud PostgreSQL databases you spin up during your trial period. Try Timescale Vector for free today.


