

The field of AI and large language models is evolving rapidly. One year ago, nobody ever used an LLM to enhance their productivity. Today, most of us can’t imagine working without or not offloading at least some minor tasks to LLMs. Due to much research and interest, LLMs are getting better and wiser every day. Not only that, but their comprehension is starting to span across multiple modalities. With the introduction of GPT-4-Vision and other LLMs that followed it, it seems that LLMs today can tackle and comprehend images very well. Here’s one example of ChatGPT describing what’s in the image.

As you can observe, ChatGPT is quite good at comprehending and describing images. We can use its ability to understand images in an RAG application, where instead of relying only on text to generate an accurate and up-to-date answer, we can now combine information from text and pictures to generate more accurate answers than ever before. Using LlamaIndex, implementing multimodal RAG pipelines is as easy as it gets. Inspired by their multimodal cookbook example, I decided to test if I could implement a multimodal RAG application with Neo4j as the database.
To implement a multimodal RAG pipeline with LlamaIndex, you simply instantiate two vector stores, one for images and one for text, and then query both of them in order to retrieve relevant information to generate the final answer.
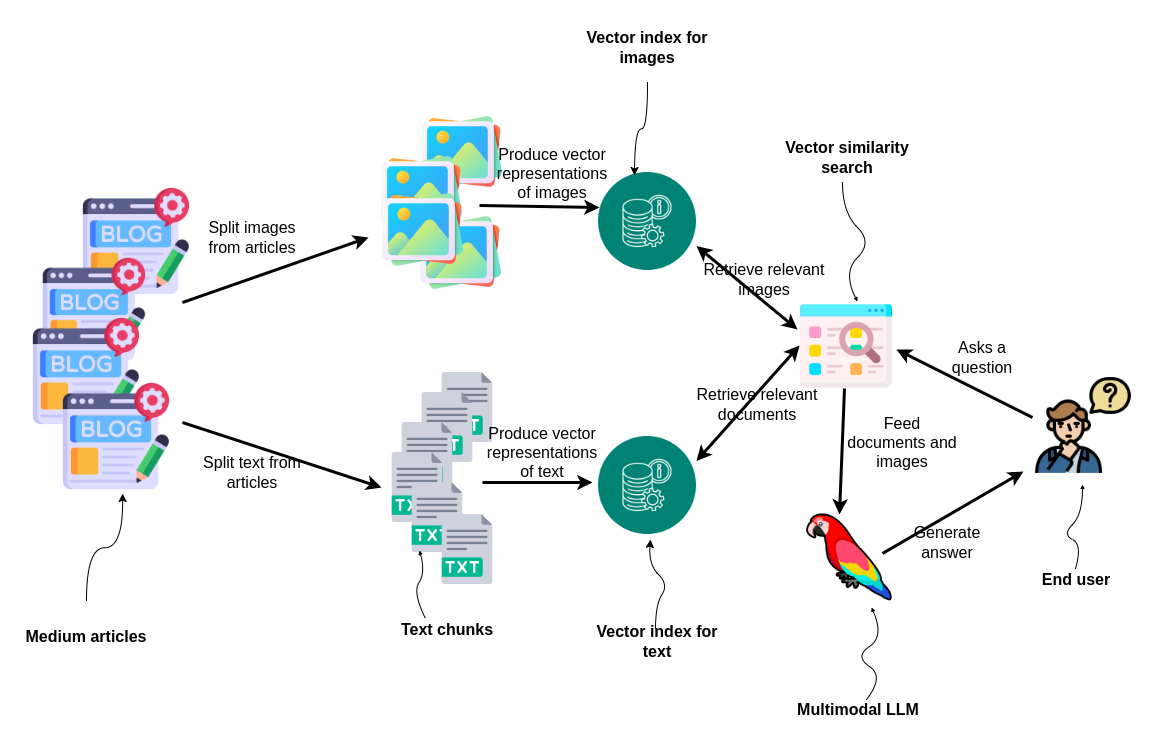
Articles are first split into images and text. These elements are then converted into vector representations and indexed separately. For text we will use ada-002 text embedding model, while for images we will be using dual encoder model CLIP, which can embed both text and images in the same embedding space. When a question is posed by an end user, two vector similarity search are performed; one to find relevant images and the other for documents. The results are fed into a multimodal LLM, which generates an answer for the user, demonstrating an integrated approach to processing and utilizing mixed media for information retrieval and response generation.
The code is available on GitHub.
Data preprocessing
We will use my Medium articles from 2022 and 2023 as the grounding dataset for an RAG application. The articles contain vast information about Neo4j Graph Data Science library and combining Neo4j with LLM frameworks. When you download your own articles from Medium, you get them in an HTML format. Therefore, we need to employ a bit of coding to extract text and images separately.
def process_html_file(file_path):
with open(file_path, "r", encoding="utf-8") as file:
soup = BeautifulSoup(file, "html.parser")
# Find the required section
content_section = soup.find("section", {"data-field": "body", "class": "e-content"})
if not content_section:
return "Section not found."
sections = []
current_section = {"header": "", "content": "", "source": file_path.split("/")[-1]}
images = []
header_found = False
for element in content_section.find_all(recursive=True):
if element.name in ["h1", "h2", "h3", "h4"]:
if header_found and (current_section["content"].strip()):
sections.append(current_section)
current_section = {
"header": element.get_text(),
"content": "",
"source": file_path.split("/")[-1],
}
header_found = True
elif header_found:
if element.name == "pre":
current_section["content"] += f"```{element.get_text().strip()}```\n"
elif element.name == "img":
img_src = element.get("src")
img_caption = element.find_next("figcaption")
caption_text = img_caption.get_text().strip() if img_caption else ""
images.append(ImageDocument(image_url=img_src))
elif element.name in ["p", "span", "a"]:
current_section["content"] += element.get_text().strip() + "\n"
if current_section["content"].strip():
sections.append(current_section)
return images, sectionsI won’t go into details for the parsing code, but we split the text based on headers h1–h4 and extract image links. Then, we simply run all the articles through this function to extract all relevant information.
all_documents = []
all_images = []
# Directory to search in (current working directory)
directory = os.getcwd()
# Walking through the directory
for root, dirs, files in os.walk(directory):
for file in files:
if file.endswith(".html"):
# Update the file path to be relative to the current directory
images, documents = process_html_file(os.path.join(root, file))
all_documents.extend(documents)
all_images.extend(images)
text_docs = [Document(text=el.pop("content"), metadata=el) for el in all_documents]
print(f"Text document count: {len(text_docs)}") # Text document count: 252
print(f"Image document count: {len(all_images)}") # Image document count: 328We get a total of 252 text chunks and 328 images. It’s a bit surprising that I created so many photos, but I know that some are only images of table results. We could use a vision model to filter out irrelevant photos, but I skipped this step here.
Indexing data vectors
As mentioned, we have to instantiate two vector stores, one for images and the other for text. The CLIP embedding model has a dimension of 512, while the ada-002 has 1536 dimension.
text_store = Neo4jVectorStore(
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
index_name="text_collection",
node_label="Chunk",
embedding_dimension=1536
)
image_store = Neo4jVectorStore(
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
index_name="image_collection",
node_label="Image",
embedding_dimension=512
)
storage_context = StorageContext.from_defaults(vector_store=text_store)Now that the vector stores have been initiated, we use the MultiModalVectorStoreIndex to index both modalities of information we have.
# Takes 10 min without GPU / 1 min with GPU on Google collab
index = MultiModalVectorStoreIndex.from_documents(
text_docs + all_images, storage_context=storage_context, image_vector_store=image_store
)Under the hood, MultiModalVectorStoreIndex uses text and image embedding models to calculate the embeddings and store and index the results in Neo4j. Only the URLs are stored for images, not actual base64 or other representations of images.
Multimodal RAG pipeline
This piece of code is copied directly from the LlamaIndex multimodal cookbook. We begin by defining a multimodal LLM and the prompt template and then combine everything as a query engine.
openai_mm_llm = OpenAIMultiModal(
model="gpt-4-vision-preview", max_new_tokens=1500
)
qa_tmpl_str = (
"Context information is below.\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"Given the context information and not prior knowledge, "
"answer the query.\n"
"Query: {query_str}\n"
"Answer: "
)
qa_tmpl = PromptTemplate(qa_tmpl_str)
query_engine = index.as_query_engine(
multi_modal_llm=openai_mm_llm, text_qa_template=qa_tmpl
)Now we can go ahead and test how well it performs.
query_str = "How do vector RAG application work?"
response = query_engine.query(query_str)
print(response)Response

We can also visualize which images the retrieval fetched and were used to help inform the final answer.
The LLM got two identical images as input, which just shows that I reuse some of my diagrams. However, I am pleasantly surprised by CLIP embeddings as they were able to retrieve he most relevant image out of the collection. In a more production setting, you might want to clean and deduplicate images, but that is beyond the scope of this article.
Conclusion
LLMs are evolving faster than what we are historically used to and are spanning across multiple modalities. I firmly believe that by the end of the next year, LLMs will be soon able to comprehend videos, and be therefore able to pick up non-verbal cues while talking to you. On the other hand, we can use images as input to RAG pipeline and enhance the variety of information passed to an LLM, making responses better and more accurate. The multimodal RAG pipelines implementation with LlamaIndex and Neo4j is as easy as it gets.
The code is available on GitHub.


