


(co-authored by Haotian Zhang, Laurie Voss, and Jerry Liu @ LlamaIndex)
Overview
In this blog we’re excited to present a fundamentally new paradigm: multi-modal Retrieval-Augmented Generation (RAG). We present new abstractions in LlamaIndex that now enable the following:
- Multi-modal LLMs and Embeddings
- Multi-modal Indexing and Retrieval (integrates with vector dbs)
Multi-Modal RAG
One of the most exciting announcements at OpenAI Dev Day was the release of the GPT-4V API. GPT-4V is a multi-modal model that takes in both text/images, and can output text responses. It’s the latest model in a recent series of advances around multi-modal models: LLaVa, and Fuyu-8B.
This extends the capabilities of LLMs in exciting new directions. In the past year, entire application stacks have emerged around the text-in/text-out paradigm. One of the most notable examples is Retrieval Augmented Generation (RAG) — combine an LLM with an external text corpus to reason over data that the model isn’t trained on. One of the most significant impacts of RAG for end-users was how much it accelerated time-to-insight on unstructured text data. By processing an arbitrary document (PDF, web page), loading it into storage, and feeding it into the context window of an LLM, you could extract out any insights you wanted from it.
The introduction of GPT-4V API allows us to extend RAG concepts into the hybrid image/text domain, and unlock value from an even greater corpus of data (including images).
Think about all the steps in a standard RAG pipeline and how it can be extended to a multi-modal setting.
- Input: The input can be text or images.
- Retrieval: The retrieved context can be text or images.
- Synthesis: The answer can be synthesized over both text and images.
- Response: The returned result can be text and/or images.
This is just a small part of the overall space too. You can have chained/sequential calls that interleave between image and text reasoning, such as Retrieval Augmented Image Captioning or multi-modal agent loops.
Abstractions in LlamaIndex
We’re excited to present new abstractions in LlamaIndex that help make multi-modal RAG possible. For each abstraction, we explicitly note what we’ve done so far and what’s still to come.
Multi-modal LLM
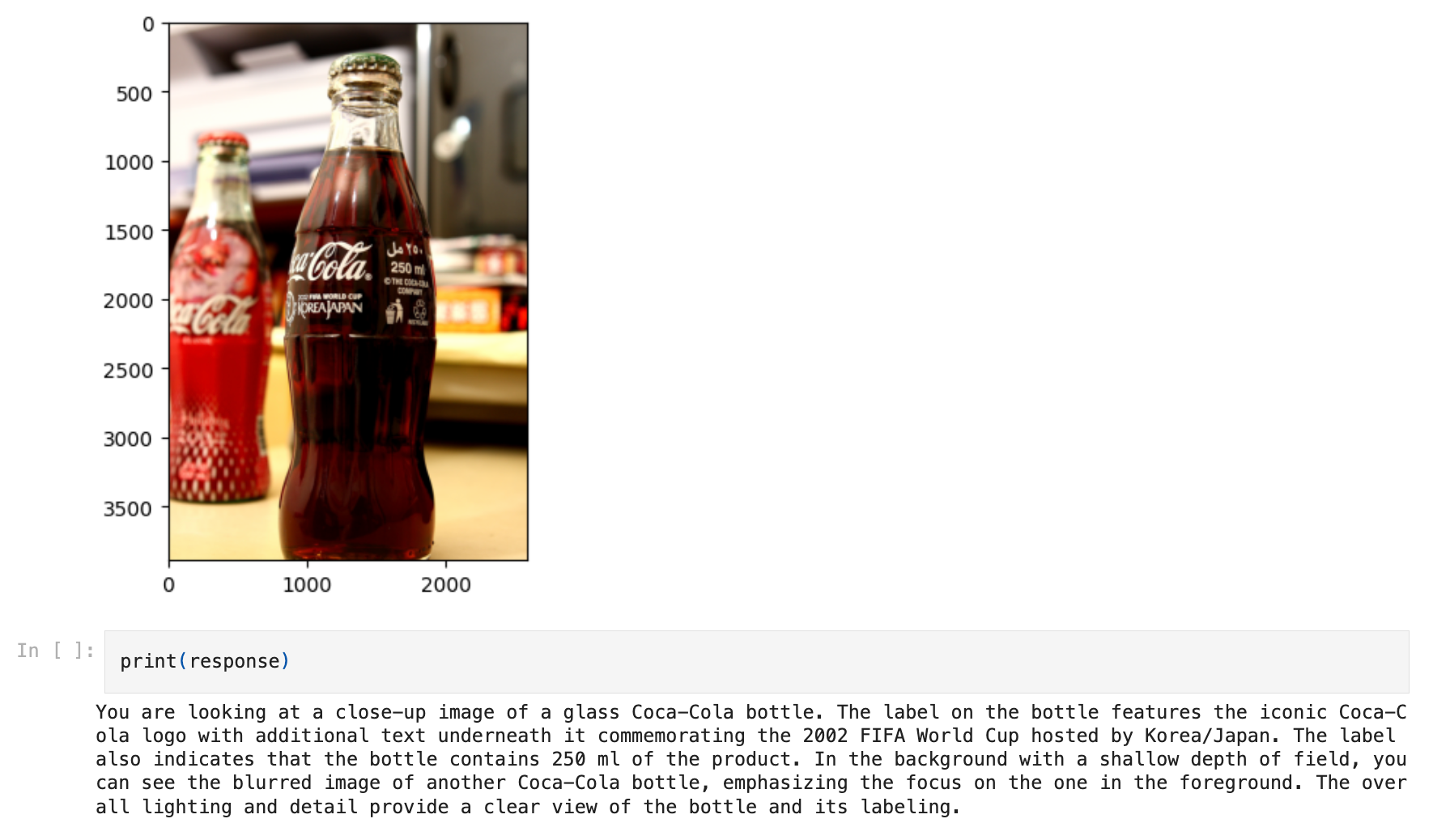
We have direct support for GPT-4V via our OpenAIMultiModal class and support for open-source multi-modal models via our ReplicateMultiModal class (currently in beta, so that name might change). Our SimpleDirectoryReader has long been able to ingest audio, images and video, but now you can pass them directly to GPT-4V and ask questions about them, like this:
from llama_index.multi_modal_llms import OpenAIMultiModal
from llama_index import SimpleDirectoryReader
image_documents = SimpleDirectoryReader(local_directory).load_data()
openai_mm_llm = OpenAIMultiModal(
model="gpt-4-vision-preview", api_key=OPENAI_API_TOKEN, max_new_tokens=300
)
response = openai_mm_llm.complete(
prompt="what is in the image?", image_documents=image_documents
) This is a new base model abstraction. Unlike our default LLM class, which has standard completion/chat endpoints, the multi-modal model (MultiModalLLM) can take in both image and text as input.
This also unifies the interface between both GPT-4V and open-source models.
Resources
We have initial implementations for both GPT-4V and vision models hosted on Replicate. We also have a docs page for multi-modal models:
What’s still to come:
- More multi-modal LLM integrations
- Chat endpoints
- Streaming
Multi-Modal Embeddings
We introduce a new MultiModalEmbedding base class that can embed both text and images. It contains all the methods as our existing embedding models (subclasses BaseEmbedding ) but also exposes get_image_embedding.
Our primary implementation here is ClipEmbedding with the CLIP model. See below for a guide on using this in action.
What’s still to come
- More multi-modal embedding integrations
Multi-Modal Indexing and Retrieval
We create a new index, a MultiModalVectorIndex that can index both text and images into underlying storage systems — specifically a vector database and docstore.
Unlike our existing (most popular) index, the VectorStoreIndex , this new index can store both text and image documents. Indexing text is unchanged — it is embedded using a text embedding model and stored in a vector database. Indexing images involves a separate process:
- Embed the image using CLIP
- Represent the image node as a base64 encoding or path, and store it along with its embedding in a vector db (separate collection from text).
We store images and text separately since we may want to use a text-only embedding model for text as opposed to CLIP embeddings (e.g. ada or sbert).
During retrieval-time, we do the following:
- Retrieve text via vector search on the text embeddings
- Retrieve images via vector search on the image embeddings
Both text and images are returned as Nodes in the result list. We can then synthesize over these results.
What’s still to Come
- More native ways to store images in a vector store (beyond base64 encoding)
- More flexible multi-modal retrieval abstractions (e.g. combining image retrieval with any text retrieval method)
- Multi-modal response synthesis abstractions. Currently the way to deal with long text context is to do “create-and-refine” or “tree-summarize” over it. It’s unclear what generic response synthesis over multiple images and text looks like.
Notebook Walkthrough
Let’s walk through a notebook example. Here we go over a use case of querying Tesla given screenshots of its website/vehicles, SEC fillings, and Wikipedia pages.
We load the documents as a mix of text docs and images:
documents = SimpleDirectoryReader("./mixed_wiki/").load_data()We then define two separate vector database collections in Qdrant: a collection for text docs, and a collection for images. We then define a MultiModalVectorStoreIndex .
# Create a local Qdrant vector store
client = qdrant_client.QdrantClient(path="qdrant_mm_db")
text_store = QdrantVectorStore(
client=client, collection_name="text_collection"
)
image_store = QdrantVectorStore(
client=client, collection_name="image_collection"
)
storage_context = StorageContext.from_defaults(vector_store=text_store)
# Create the MultiModal index
index = MultiModalVectorStoreIndex.from_documents(
documents, storage_context=storage_context, image_vector_store=image_store
)We can then ask questions over our multi-modal corpus.
Example 1: Retrieval Augmented Captioning
Here we copy/paste an initial image caption as the input to get a retrieval-augmented output:
retriever_engine = index.as_retriever(
similarity_top_k=3, image_similarity_top_k=3
)
# retrieve more information from the GPT4V response
retrieval_results = retriever_engine.retrieve(query_str)The retrieved results contain both images and text:

We can feed this to GPT-4V to ask a followup question or synthesize a coherent response:
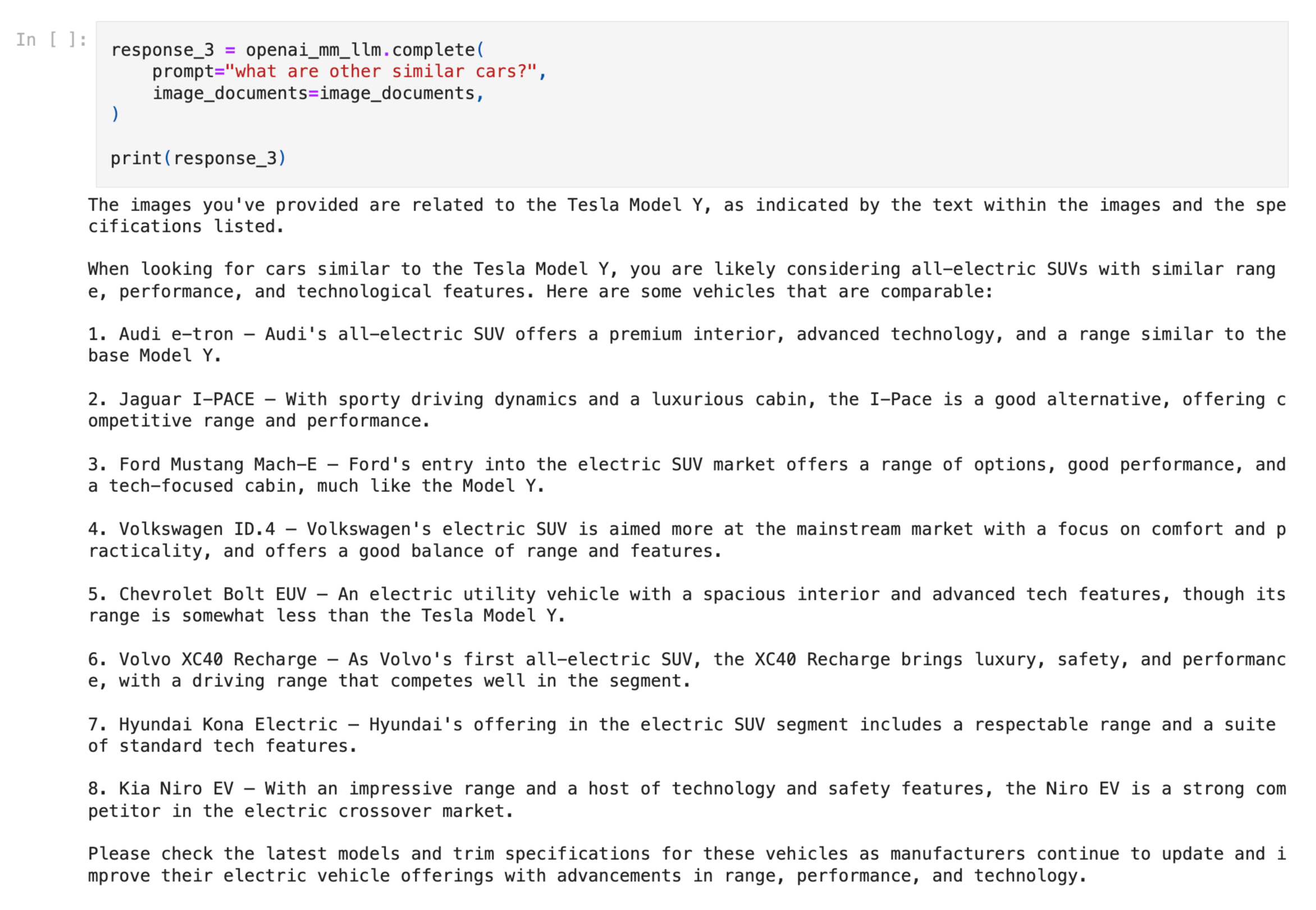
Example 2: Multi-Modal RAG Querying
Here we ask a question and get a response from the entire multi-modal RAG pipeline. The SimpleMultiModalQueryEngine first retrieves the set of relevant images/text, and feeds the input to a vision model in order to synthesize a response.
from llama_index.query_engine import SimpleMultiModalQueryEngine
query_engine = index.as_query_engine(
multi_modal_llm=openai_mm_llm,
text_qa_template=qa_tmpl
)
query_str = "Tell me more about the Porsche"
response = query_engine.query(query_str)The generated result + sources are shown below:


