
Despite recent motivation to utilize NLP for wider range of real world applications, most NLP papers, tasks and pipelines assume raw, clean texts. However, many texts we encounter in the wild, including a vast majority of legal documents (e.g., contracts and legal codes), are not so clean, with many of them being visually structured documents (VSDs) such as PDFs. PDFs are versatile, preserving the visual integrity of documents, but they often pose a significant challenge when it comes to extracting and manipulating their contents.
In this discussion, our focus will primarily be on text-only layered PDFs, a category often regarded by many as a resolved issue.
Complexity of Parsing PDFs
- Layout Complexity: PDFs can contain complex layouts, such as multi-column text, tables, images, and intricate formatting. This layout diversity complicates the extraction of structured data.
- Font encoding issues: PDFs use a variety of font encoding systems, and some of these systems do not map directly to Unicode. This can make it difficult to extract the text accurately.
- Non-linear text storage: PDFs do not store text in the order it appears on the page. Instead, they store text in objects that can be placed anywhere on the page. This means that the order of the text in the underlying code may not match the order of the text as it appears visually.
- Inconsistent use of spaces: In some PDFs, spaces are not used consistently or are not used at all between words. This can make it difficult to even identify word boundaries.
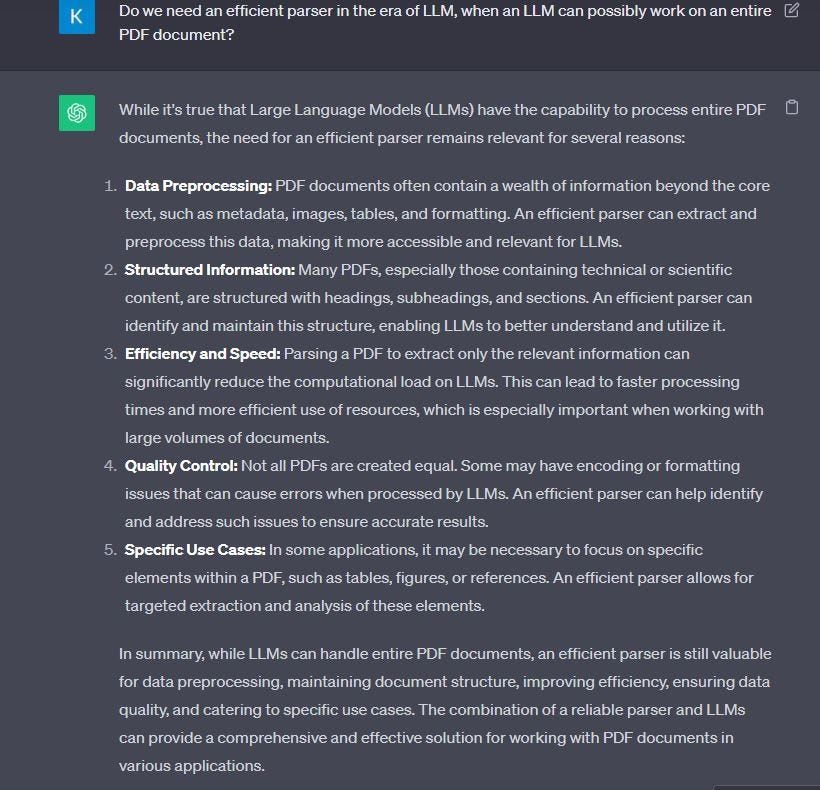
Do we need an efficient parser?
In the Age of LLMs, is an Efficient Parser Still Essential When LLMs Can Process Entire PDFs?
This question gains relevance if the answer to this next question is “Yes”.
Do we need Retrieval-Augmented Generation (RAG)?
While LLMs are powerful, they have certain limitations in terms of the amount of text they can process at once and the scope of information they can reference. Further recent research have suggested LLM performance is often highest when relevant information occurs at the beginning or end of the input context, and significantly degrades when models must access relevant information in the middle of long contexts. Techniques like RAG help overcome these limitations, enabling more effective and efficient processing of large documents and broader information retrieval.
Still Skeptical? Let’s ask an LLM for confirmation.
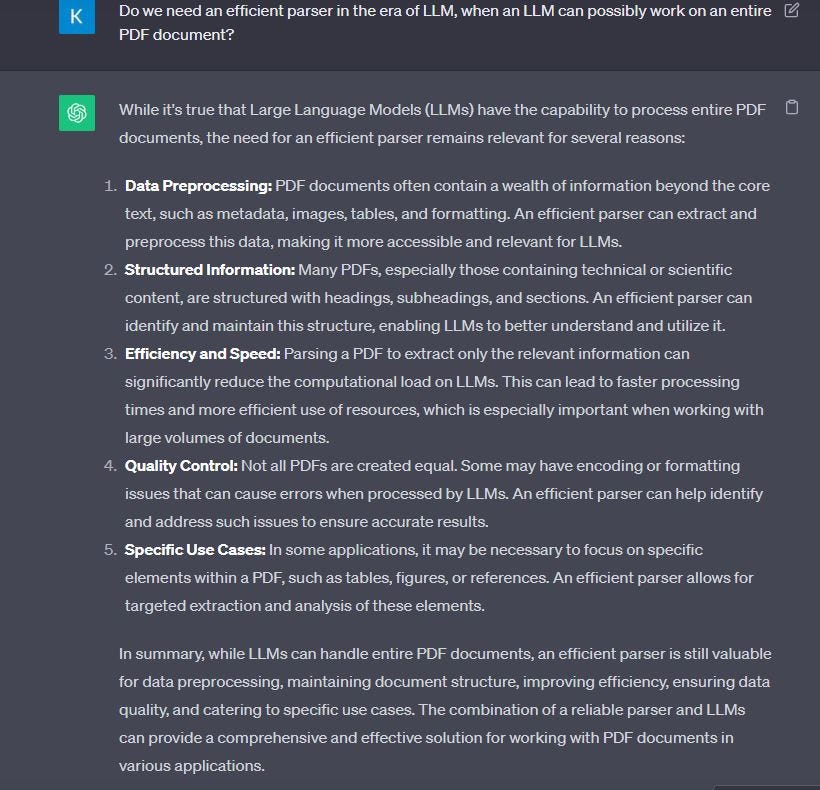
Now that we’ve established the importance of an efficient parser, it becomes instrumental in constructing an effective Retrieval-Augmented Generation (RAG) pipeline to address the limitations of an LLM. Let’s explore how we are achieving this today. It’s crucial to remember that the quality of the context fed to an LLM is the cornerstone of an effective RAG, as the saying goes, ‘Garbage In — Garbage Out.’
In the context of building LLM-related applications, chunking is the process of breaking down large pieces of text into smaller segments. It’s an essential technique that helps optimize the relevance of the content we get back from a database once we use the LLM to embed content. Some of the strategies involved are
- Fixed-size chunking. This is the most common and straightforward approach to chunking: we simply decide the number of tokens in our chunk and, optionally, whether there should be any overlap between them. Easy to implement & most commonly used, but never makes it to a production setting because the output is satisfactory in a Proof of Concept (POC) setup, but its accuracy degrades as we conduct further testing.
- “Content-aware” chunking. Set of methods for taking advantage of the nature of the content we’re chunking and applying more sophisticated chunking to it. Challenging to implement due to the reasons mentioned above, but if tackled correctly, it could be the most ideal building block for a production-grade Information Retrieval (IR) engine.
Where’s This Article Headed, Anyway?
Certainly, let’s put an end to the historical and background details, shall we?
Introducing LayoutPDFReader for “Context-aware” chunking. LayoutPDFReader can act as the most important tool in your RAG arsenal by parsing PDFs along with hierarchical layout information such as:
- Identifying sections and subsections, along with their respective hierarchy levels.
- Merging lines into coherent paragraphs.
- Establishing connections between sections and paragraphs.
- Recognizing tables and associating them with their corresponding sections.
- Handling lists and nested list structures with precision.
The first step in using the LayoutPDFReader is to provide a URL or file path to it (assuming it’s already been installed) and get back a document object.
from llmsherpa.readers import LayoutPDFReader
llmsherpa_api_url = "https://readers.llmsherpa.com/api/document/developer/parseDocument?renderFormat=all"
pdf_url = "https://arxiv.org/pdf/1910.13461.pdf" # also allowed is a file path e.g. /home/downloads/xyz.pdf
pdf_reader = LayoutPDFReader(llmsherpa_api_url)
doc = pdf_reader.read_pdf(pdf_url)
Vector search and RAG with Smart Chunking
LayoutPDFReader employs intelligent chunking to maintain the cohesion of related text:
- It groups all list items together, along with the preceding paragraph.
- Items within a table are chunked together.
- It incorporates contextual information from section headers and nested section headers.
As a quick example, the following code snippet generates a LlamaIndex query engine from the document chunks produced by LayoutPDFReader.
from llama_index.readers.schema.base import Document
from llama_index import VectorStoreIndex
index = VectorStoreIndex([])
for chunk in doc.chunks():
index.insert(Document(text=chunk.to_context_text(), extra_info={}))
query_engine = index.as_query_engine()
# Let's run one query
response = query_engine.query("list all the tasks that work with bart")
print(response)
We get the following response:
BART works well for text generation, comprehension tasks, abstractive dialogue, question answering, and summarization tasks.
Key Considerations:
- LLMSherpa leverages a cost-free and open API server. Your PDFs are not retained beyond temporary storage during the parsing process.
- LayoutPDFReader has undergone extensive testing with a diverse range of PDFs. However, achieving flawless parsing for every PDF remains a challenging task.
- Please note that OCR (Optical Character Recognition) functionality is presently unavailable. The tool exclusively supports PDFs equipped with a text layer.
- For inquiries regarding private hosting options, OCR support, or tailored assistance with particular PDF-related concerns, feel free to reach out to contact@nlmatics.com or to me directly.
If you have any questions, please leave them in the comments section, and I will try to respond ASAP.
Connect?
If you want to get in touch, feel free to shoot me a message on LinkedIn or via email.
References
https://github.com/nlmatics/llmsherpa
Capturing Logical Structure of Visually Structured Documents with Multimodal Transition Parser


