


(co-authored by Ofer Mendelevitch, head of Developer Relations at Vectara, and Logan Markewich, founding engineer at LlamaIndex)
Introduction
Vectara is a trusted GenAI platform. Exposing a set of easy to use APIs, Vectara’s platform reduces the complexity involved in developing Grounded Generation (aka retrieval-augmented-generation) applications, and managing the LLM infrastructure that’s required to deploy them at scale in production.
Today we’re happy to announce Vectara’s integration with LlamaIndex via a new type of Index: the Managed Index. In this blog post, we’ll dig deeper into how a ManagedIndex works, and show examples of using Vectara as a Managed Index.
What is Vectara?
Vectara is an end-to-end platform that offers powerful generative AI capabilities for developers, including:
Data processing. Vectara supports various file types for ingestion including markdown, PDF, PPT, DOC, HTML and many others. At ingestion time, the text is automatically extracted from the files, and chunked into sentences. Then a vector embedding is computed for each chunk, so you don’t need to call any additional service for that.
Vector and text storage. Vectara hosts and manages the vector store (where the document embeddings are stored) as well as the associated text. Developers don’t need to go through a long and expensive process of evaluation and choice of vector databases. Nor do they have to worry about setting up that Vector database, managing it in their production environment, re-indexing, and many other DevOps considerations that become important when you scale your application beyond a simple prototype.
Query flow. When issuing a query, calculating the embedding vector for that query and retrieving the resulting text segments (based on similarity match) is fully managed by Vectara. Vectara also provides a robust implementation of hybrid search and re-ranking out of the box, which together with a state of the art embedding model ensures the most relevant text segments are returned in the retrieval step.
Security and Privacy. Vectara’s API is fully encrypted in transit and at rest, and supports customer-managed-keys (CMK). We never train on your data, so you can be sure your data is safe from privacy leaks.
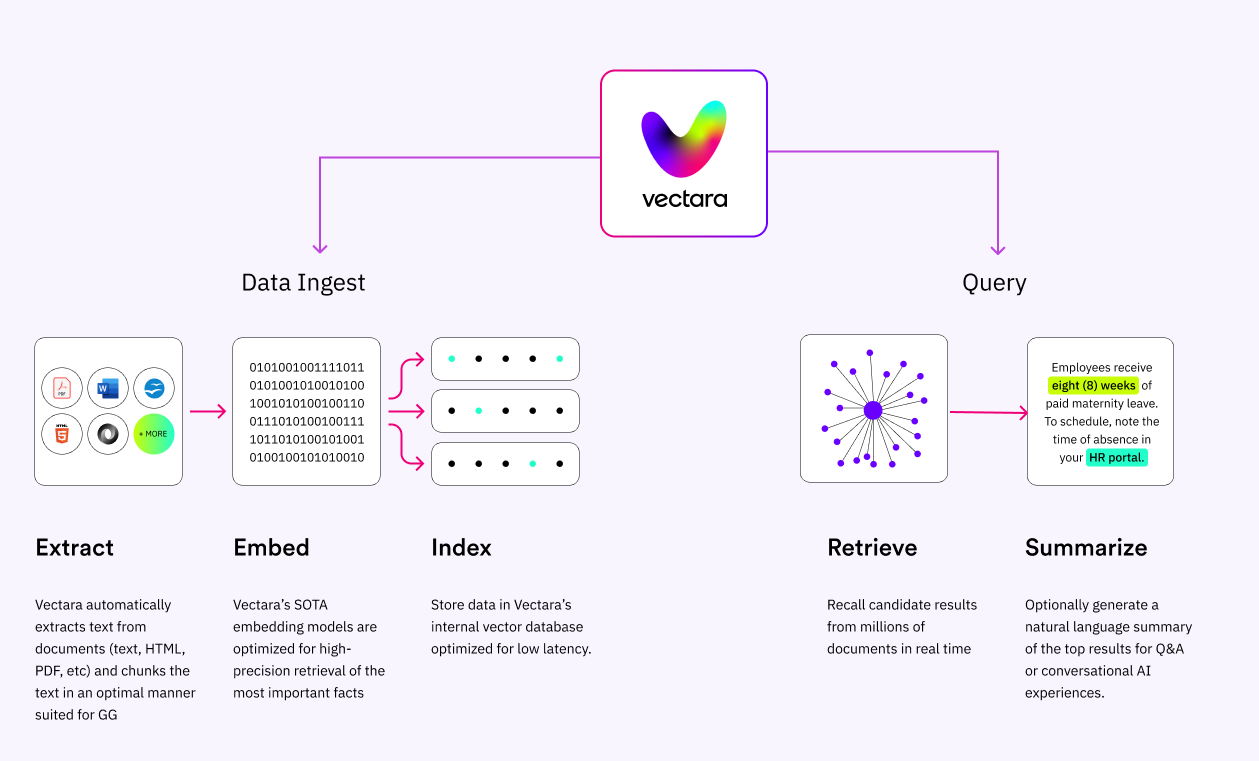
Figure 1: Vectara’s API platform for “Grounded Generation”
The nice thing is that all this complexity is fully managed by Vectara, taking a lot of the heavy lifting off of the developer’s shoulders, so that they don’t have to specialize in the constantly evolving skills of large language models, embedding models, vector stores and MLOps.
From VectorStoreIndex to ManagedIndex
LlamaIndex is a data framework for building LLM applications. It provides a set of composable modules for users to define a data pipeline for their application. This consists of data loaders, text splitters, metadata extractors, and vector store integrations.
A popular abstraction that users use is the VectorStoreIndex, providing integrations with different vector databases.
However, a challenge here is that users still need to carefully define how to load data, parse it, as well as choose an embedding model and a vector DB to use. Since Vectara abstracts away this complexity, the Vectara and LlamaIndex teams jointly came up with a new abstraction: The ManagedIndex.
As shown in figure 2, when ingesting data into a VectorStoreIndex, data is processed locally taking advantage of multiple components like Data Connectors and Node parsers.
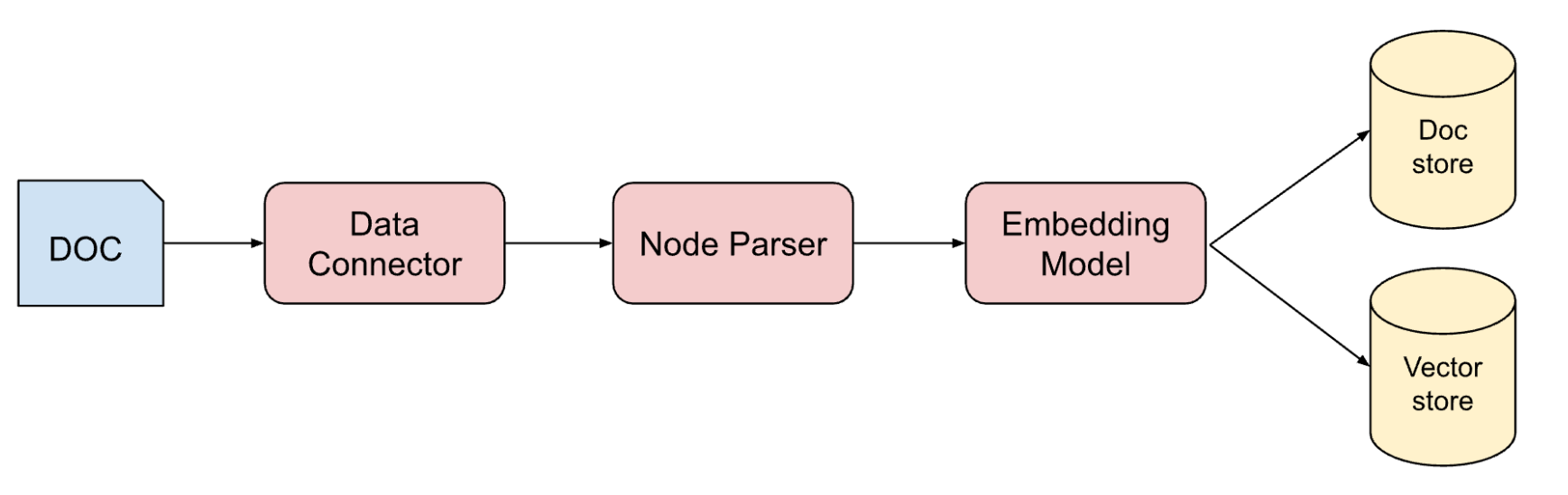
Figure 2: typical flow of document processing in LlamaIndex for a VectorStoreIndex
With Vectara (figure 3), this whole flow is replaced by a single “indexing” API call , and all this processing is instead performed in the backend by the Vectara platform.
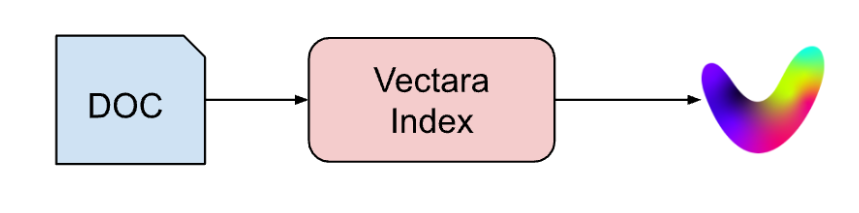
Figure 3: pre-processing with the VectaraIndex simplifies the complex ingest flow to a single step.
How does the VectaraIndex work?
Let’s take a look at a simple question-answering example using VectaraIndex, in this case asking questions from one of Paul Graham’s Essays.
Step 1: Setup your Vectara account and Index
To get started, follow our quickstart guide: signup for a free Vectara account, create a corpus (index), and generate your API key.
Then setup your Vectara customer_id, corpus_id and api_key as environment variables, so that the VectaraIndex can access those easily, for example:
VECTARA_CUSTOMER_ID=<YOUR_CUSTOMER_ID>
VECTARA_CORPUS_ID=<YOUR_CORPUS_ID>
VECTARA_API_KEY="zwt_RbZfGT…"Step 2: Create a VectaraIndex instance with LlamaIndex
Building the Vectara Index is extremely simple:
from llama_index import SimpleDirectoryReader
from llama_index.indices import VectaraIndex
From pprint Import pprint
documents = SimpleDirectoryReader("paul_graham").load_data()
index = VectaraIndex.from_documents(documents)Here we load Paul Graham’s Essay using LlamaIndex’s SimpleDirectoryReader into a single document. The from_documents() constructor is then used to generate the VectaraIndex instance.
Unlike the common flow that uses LlamaIndex tools like data connectors, parsers and embedding models to process the input data, with VectaraIndex the documents are sent directly to Vectara via the Indexing API. Vectara’s platform then processes, chunks, encodes and stores the text and embeddings into a Vectara corpus, making it available instantly for querying.
Step 3: Query
After the data is fully ingested, you can take advantage of the rich set of query constructs built into LlamaIndex. For example let’s use the index to retrieve the top-k most relevant nodes:
retriever = index.as_retriever(similarity_top_k=7)
# docs should contain the 7 most relevant documents for the query
docs = retriever.retrieve(“What is the IBM 1401?”)
pprint(docs[0].node.text)(‘My stories were awful. They had hardly any plot, just characters with strong feelings, which I imagined made them deep. The first programs I tried writing were on the IBM 1401 that our school district used for what was then called “data processing.” This was in 9th grade, so I was 13 or 14. The school district’s 1401 happened to be in the basement of our junior high school, and my friend Rich Draves and I got permission to use it.’)
Here we printed out the top matching Node given the query “what is the IBM 1401?” This in turn results in a call to Vectara’s Search API that returns the top-k matching document segments.
Those are transformed into NodeWithScore objects and thus can be used as usual with the rest of the LlamaIndex querying tools. For example we can use LlamaIndex’s query_engine() to convert the retrieved matching document segments (nodes) into a comprehensive response to our question:
# Get an answer to the query based on the content of the essay
response = index.as_query_engine().query("What can the 1401 do?")
print(response)The 1401 was used for “data processing” and could load programs into memory and run them. It had a card reader, printer, CPU, disk drives, and used an early version of Fortran as the programming language. The only form of input to programs was data stored on punched cards.
Why Use VectaraIndex with LlamaIndex?
By adding the concept of a “Managed Index” and the VectaraIndex to LlamaIndex, users can continue to take advantage of the tools and capabilities offered by the LlamaIndex library while integrating with a generative AI platform like Vectara.
Retrievers and Query Engines are just the tip of the iceberg. Using a managed index with Vectara, developers have full access to advanced utilities like routers, advanced query engines, data agents, chat engines, and more! Being able to retrieve context using Vectara empowers developers to build these complex applications using LlamaIndex components.
For example, in the following code we use the chat engine in LlamaIndex to quickly create a chat interaction using our VectaraIndex:
chat = index.as_chat_engine(chat_mode='context')
res = chat.chat("When did the author learn Lisp?")
print(res.response)“The author learned Lisp in college.”
A follow up question retains the chat history for context, as you might expect:
chat.chat("and was it helpful for projects?").response“Yes, learning Lisp was helpful for the author’s projects. They used Lisp in both Viaweb and Y Combinator, indicating its usefulness in their work.”
chat.chat("what was a distinctive characteristic of that programming language?").response“A distinctive characteristic of Lisp is that its core is a language defined by writing an interpreter in itself. It was originally designed as a formal model of computation and an alternative to the Turing machine. This self-referential nature of Lisp sets it apart from other programming languages.”
For more information on how to use chat-engines, check out the documentation, and for more information on other query capabilities with LlamaIndex, check out the full documentation here.
Summary
LlamaIndex makes it super easy to populate VectaraIndex with content from any document or data source, while utilizing the Vectara service for managing the document processing, chunking, embedding and making all of this data available for advanced retrieval in query time using the LlamaIndex library.
VectaraIndex is based on the new LlamaIndex Managed Index abstraction, which better supports GenAI platforms like Vectara, and enables additional vendors who also provide end-to-end platforms to join in.
To get started with Vectara and LlamaIndex you can follow the Vectara quickstart guide to setup your account, and the examples above with your own data.


