

Today we’re excited to launch LlamaIndex v0.10.0. It is by far the biggest update to our Python package to date (see this gargantuan PR), and it takes a massive step towards making LlamaIndex a next-generation, production-ready data framework for your LLM applications.
LlamaIndex v0.10 contains some major updates:
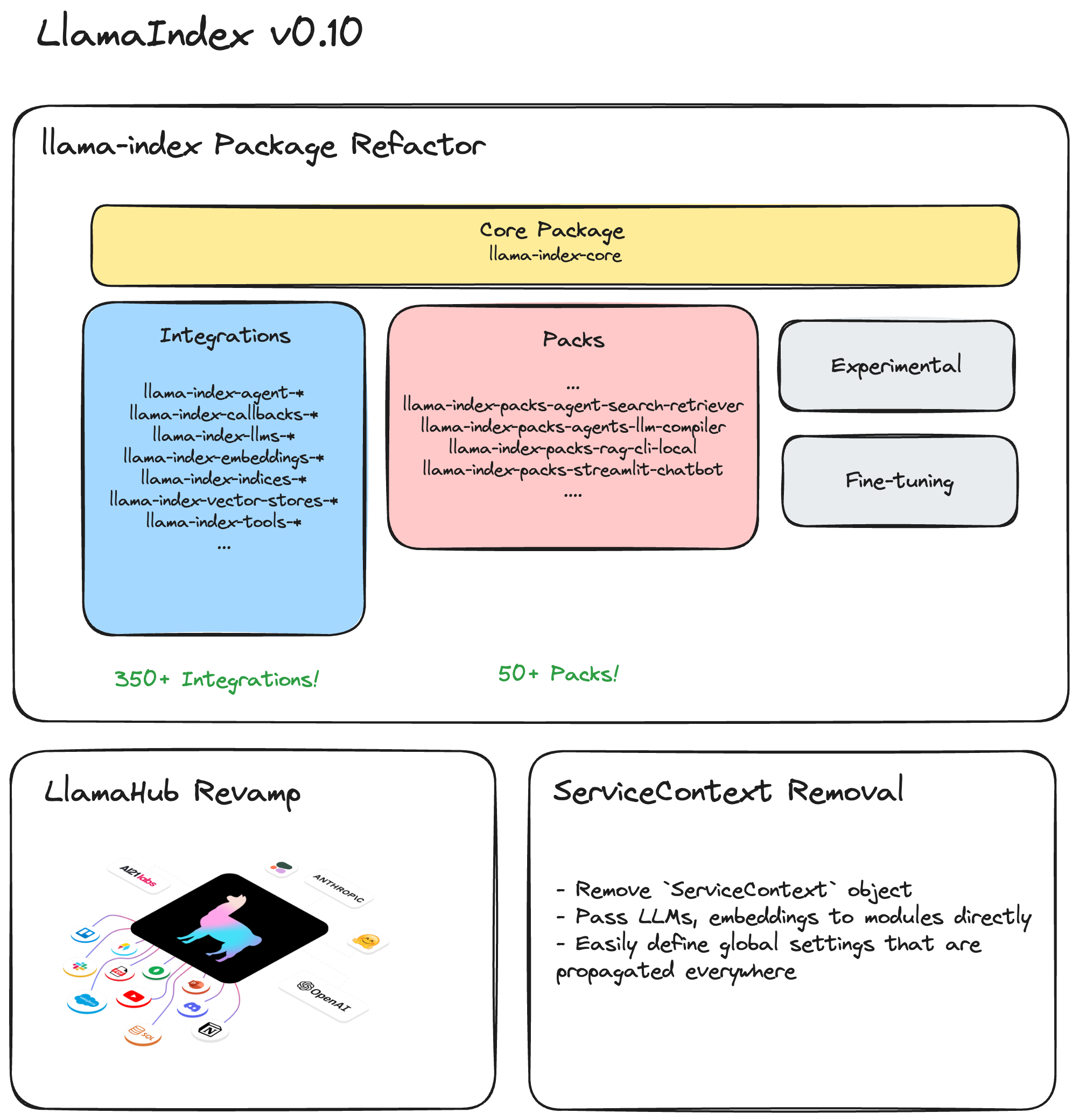
- We have created a
llama-index-corepackage, and split all integrations and templates into separate packages: Hundreds of integrations (LLMs, embeddings, vector stores, data loaders, callbacks, agent tools, and more) are now versioned and packaged as a separate PyPI packages, while preserving namespace imports: for example, you can still usefrom llama_index.llms.openai import OpenAIfor a LLM. - LlamaHub will be the central hub for all integrations: the former llama-hub repo itself is consolidated into the main llama_index repo. Instead of integrations being split between the core library and LlamaHub, every integration will be listed on LlamaHub. We are actively working on updating the site, stay tuned!
- ServiceContext is deprecated: Every LlamaIndex user is familiar with ServiceContext, which over time has become a clunky, unneeded abstraction for managing LLMs, embeddings, chunk sizes, callbacks, and more. As a result we are completely deprecating it; you can now either directly specify arguments or set a default.
Upgrading your codebase to LlamaIndex v0.10 may lead to some breakages, primarily around our integrations/packaging changes, but fortunately we’ve included some scripts to make it as easy as possible to migrate your codebase to use LlamaIndex v0.10.
Check out the below sections for more details, and go to the very last section for resource links to everything.
Splitting into `llama-index-core` and integration packages
The first and biggest change we’ve made is a massive packaging refactor.
LlamaIndex has evolved into a broad toolkit containing hundreds of integrations:
- 150+ data loaders
- 35+ agent tools
- 50+ LlamaPack templates
- 50+ LLMs
- 25+ embeddings
- 40+ vector stores
and more across the llama_index and llama-hub repos. The rapid growth of our ecosystem has been awesome to see, but it’s also come with growing pains:
- Many of the integrations lack proper tests
- Users are responsible for figuring out dependencies
- If an integration updates, users will have to update their entire
llama-indexPython package.
In response to this, we’ve done the following.
- Created
llama-index-core: This is a slimmed-down package that contains the core LlamaIndex abstractions and components, without any integrations. - Created separate packages for all integrations/templates: Every integration is now available as a separate package. This includes all integrations, including those on LlamaHub! See our Notion registry page for a full list of all packages.
The llama-index package still exists, and it imports llama-index-core and a minimal set of integrations. Since we use OpenAI by default, this includes OpenAI packages (llama-index-llms-openai, llama-index-embeddings-openai, and OpenAI programs/question generation/multimodal), as well as our beloved SimpleDirectoryReader (which is in llama-index-readers-file).
NOTE: if you don’t want to migrate to v0.10 yet and want to continue using the current LlamaIndex abstractions, we are maintaining llama-index-legacy (pinned to the latest release 0.9.48) for the foreseeable future.
Revamped Folder Structure
We’ve completely revamped the folder structure in the llama_index repo. The most important folders you should care about are:
llama-index-core: This folder contains all core LlamaIndex abstractions.llama-index-integrations: This folder contains third-party integrations for 19 LlamaIndex abstractions. This includes data loaders, LLMs, embedding models, vector stores, and more. See below for more details.llama-index-packs: This folder contains our 50+ LlamaPacks, which are templates designed to kickstart a user’s application.
Other folders:
llama-index-legacy: contains the legacy LlamaIndex code.llama-index-experimental: contains experimental features. Largely unused right now (outside parameter tuning).llama-index-finetuning: contains LlamaIndex fine-tuning abstractions. These are still relatively experimental.
The sub-directories in integrations and packs represent individual packages. The name of the folder corresponds to the package name. For instance, llama-index-integrations/llms/llama-index-llms-gemini corresponds to the llama-index-llms-gemini PyPI package.
Within each package folder, the source files are arranged in the same paths that you use to import them. For example, in the Gemini LLM package, you’ll see a folder called llama_index/llms/gemini containing the source files. This folder structure is what allows you to preserve the top-level llama_index namespace during importing. In the case of Gemini LLM, you would pip install llama-index-llms-gemini and then import using from llama_index.llms.gemini import Gemini.
Every one of these subfolders also has the resources needed to packagify it: pyproject.toml, poetry.lock, and a Makefile , along with a script to automatically create a package.
If you’re looking to contribute an integration or pack, don’t worry! We have a full contributing guide designed to make this as seamless as possible, make sure to check it out.
Integrations
All third-party integrations are now under llama-index-integrations. There are 19 folders in here. The main integration categories are:
llmsembeddingsmulti_modal_llmsreaderstoolsvector_stores
For completeness here are all the other categories: agent, callbacks, evaluation, extractors, graph_stores, indices, output_parsers, postprocessor, program, question_gen, response_synthesizers, retrievers, storage, tools.
The integrations in the most common categories can be found in our temporary Notion package registry page. All integrations can be found in our Github repo. The folder name of each integration package corresponds to the name of the package — so if you find an integration you like, you now know how to pip install it!
We are actively working to make all integrations viewable on LlamaHub. Our vision for LlamaHub is to be the hub for all third-party integrations.
If you’re interested in contributing a package, see our contributing section below!
Usage Example
Here is a simple example of installing and using an Anthropic LLM.
pip install llama-index-llms-anthropic
from llama_index.llms.anthropic import Anthropic
llm = Anthropic(api_key="<api_key>")Here is an example of using a data loader.
pip install llama-index-readers-notion
from llama_index.readers.notion import NotionPageReader
integration_token = os.getenv("NOTION_INTEGRATION_TOKEN")
page_ids = ["<page_id>"]
reader = NotionPageReader(integration_token=integration_token)
documents = reader.load_data(page_ids=page_ids)Here is an example of using a LlamaPack:
pip install llama-index-packs-sentence-window-retriever
from llama_index.packs.sentence_window_retriever import SentenceWindowRetrieverPack
# create the pack
# get documents from any data loader
sentence_window_retriever_pack = SentenceWindowRetrieverPack(
documents
)
response = sentence_window_retriever_pack.run("Tell me a bout a Music celebritiy.")Dealing with Breaking Changes
This update comes with breaking changes, mostly around imports. For all integrations, you can no longer do any of these:
# no more using `llama_index.llms` as a top-level package
from llama_index.llms import OpenAI
# no more using `llama_index.vector_stores` as a top-level package
from llama_index.vector_stores import PineconeVectorStore
# llama_hub imports are now no longer supported.
from llama_hub.slack.base import SlackReaderInstead you can do these:
from llama_index.llms.openai import OpenAI
from llama_index.vector_stores.pinecone import PineconeVectorStore
# NOTE: no longer import a separate llama_hub package
from llama_index.readers.slack import SlackReaderSee our migration guide (also described below) for more details.
LlamaHub as a Central Hub for Integrations
With these packaging updates, we’re expanding the concept of LlamaHub to become a central hub of all LlamaIndex integrations to fulfill its vision of becoming an integration site at the center of the LLM ecosystem. This expands beyond its existing domain of loaders, tools, packs, and datasets, to include LLMs, embeddings, vector stores, callbacks, and more.
This effort is still a WIP. If you go to llamahub.ai today, you’ll see that the site has not been updated yet, and it still contains the current set of integrations (data loaders, tools, LlamaPacks, datasets). Rest assured we’ll be updating the site in a few weeks; in the meantime check out our Notion package registry / repo for a list of all integrations/packages.
Sunsetting llama-hub repo
Since all integrations have been moved to the llama_index repo, we are sunsetting the llama-hub repo (but LlamaHub itself lives on!). We did the painstaking work of migrating and packaging all existing llama-hub integrations. For all future contributions please submit directly to the llama_index repo!
`download` syntax
A popular UX for fetching integrations through LlamaHub has been the download syntax: download_loader , download_llama_pack , and more.
This will still work, but have different behavior. Check out the details below:
download_llama_pack: Will download a pack underllama-index-packsto a local file on your disk. This allows you to directly use and modify the source code from the template.- Every other download function
download_loader,download_tool: This will directly run pip install on the relevant integration package.
Deprecating ServiceContext
Last but not least, we are deprecating our ServiceContext construct and as a result improving the developer experience of LlamaIndex.
Our ServiceContext object existed as a general configuration container containing an LLM, embedding model, callback, and more; it was created before we had proper LLM, embedding, prompt abstractions and was meant to be an intermediate user-facing layer to let users define these parameters.
Over time however, this object became increasingly difficult to use. Passing in an entire service_context container to any module (index, retriever, post-processor, etc.) made it hard to reason about which component was actually getting used. Since all modules use OpenAI by default, users were getting asked to unnecessarily specify their OpenAI key even in cases where they’d want to use a local model (because the embedding model default was still OpenAI). It was also laborious to import and type out.
Another related pain point was that if you had a custom model or especially a custom callback, you had to manually pass in the service_context to all modules. This was laborious and it was easy for users to forget, resulting in missed callbacks or inconsistent model usage.
Therefore we’ve made the following changes:
- ServiceContext is now deprecated: You should now directly pass in relevant parameters to modules, such as the embedding model for indexing and the LLM for querying/response synthesis.
- You can now define global settings: Define this once, and don’t worry about specifying any custom parameters at all in your downstream code. This is especially useful for callbacks.
All references to ServiceContext in our docs/notebooks have been removed and changed to use either direct modules or the global settings object. See our usage example below as well.
Usage Example
To build a VectorStoreIndex and then query it, you can now pass in the embedding model and LLM directly
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
from llama_index.core.callbacks import CallbackManager
embed_model = OpenAIEmbedding()
llm = OpenAI()
callback_manager = CallbackManager()
index = VectorStoreIndex.from_documents(
documents, embed_model=embed_model, callback_manager=callback_manager
)
query_engine = index.as_query_engine(llm=llm)Or you can define a global settings object
from llama_index.core.settings import Settings
Settings.llm = llm
Settings.embed_model = embed_model
Settings.callback_manager = callback_manager
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()Contributing to LlamaIndex v0.10
v0.10 makes the llama_index repo the central place for all community contributions, whether you are interested in contributing core refactors, or integrations/packs!
If you’re contributing an integration/pack, v0.10 makes it way easier for you to contribute something that can be independently versioned, tested, and packaged.
We have utility scripts to make the package creation process for an integration or pack effortless:
# create a new pack
cd ./llama-index-packs
llamaindex-cli new-package --kind "packs" --name "my new pack"
# create a new integration
cd ./llama-index-integrations/readers
llamaindex-cli new-pacakge --kind "readers" --name "new reader"Take a look at our updated contributing guide here for more details.
Migration to v0.10
If you want to use LlamaIndex v0.10, you will need to do two main things:
- Adjust imports to fit the new package structure for core modules/integrations
- Deprecate ServiceContext
Luckily, we’ve created a comprehensive migration guide that also contains a CLI tool to automatically upgrade your existing code and notebooks to v0.10!
Just do
llamaindex-cli upgrade <source-dir>Check out the full migration guide here.
Next Steps
We’ve painstakingly revamped all of our README, documentation and notebooks to reflect these v0.10 changes. Check out the below section for a compiled list of all resources.
Documentation
Temporary v0.10 Package Registry
Repo
Example Notebooks
These are mostly to show our updated import syntax.
- Sub-Question Query Engine (primarily uses core)
- Weaviate Vector Store Demo
- OpenAI Agent over RAG Pipelines
Bug reports
We’ll be actively monitoring our Github Issues and Discord. If you run into any issues don’t hesitate to hop into either of these channels!


