

Today is a big day for the LlamaIndex ecosystem: we are announcing LlamaParse, a new generation of managed parsing, ingestion, and retrieval services, designed to bring production-grade context-augmentation to your LLM and RAG applications.
Using LlamaParse as an enterprise AI engineer, you can focus on writing the business logic and not on data wrangling. Process large volumes of production data, immediately leading to better response quality. LlamaParse launches with the following key components:
- LlamaParse: Proprietary parsing for complex documents with embedded objects such as tables and figures. LlamaParse directly integrates with LlamaIndex ingestion and retrieval to let you build retrieval over complex, semi-structured documents. You’ll be able to answer complex questions that simply weren’t possible previously.
- Managed Ingestion and Retrieval API: An API which allows you to easily load, process, and store data for your RAG app and consume it in any language. Backed by data sources in LlamaHub, including LlamaParse, and our data storage integrations.
LlamaParse is available in a public preview setting starting today. It can currently handle PDFs and usage is capped for public use; contact us for commercial terms. The managed ingestion and retrieval API is available as a private preview; we are offering access to a limited set of enterprise design partners. If you’re interested, get in touch. (We’ve also launched a new version of our website 🦙!)
RAG is Only as Good as your Data
A core promise of LLMs is the ability to automate knowledge search, synthesis, extraction, and planning over any source of unstructured data. Over the past year a new data stack has emerged to power these context-augmented LLM applications, popularly referred to as Retrieval-Augmented Generation (RAG). This stack includes loading data, processing it, embedding it, and loading into a vector database. This enables downstream orchestration of retrieval and prompting to provide context within an LLM app.
This stack is different from any ETL stack before it, because unlike traditional software, every decision in the data stack directly affects the accuracy of the full LLM-powered system. Every decision like chunk size and embedding model affects LLM outputs, and since LLMs are black boxes, you can’t unit test your way to correct behavior.
We’ve spent the past year hard at work at the forefront of providing tooling and educating users on how to build high-performing, advanced RAG for various use cases. We crossed the 2M monthly download mark, and are used by large enterprises to startups, including Adyen, T-Systems, Jasper.ai, Weights and Biases, DataStax, and many more.
But while getting started with our famous 5-line starter example is easy, building production-grade RAG remains a complex and subtle problem. In our hundreds of user conversations, we learned the biggest pain points:
- Results aren’t accurate enough: The application was not able to produce satisfactory results for a long-tail of input tasks/queries.
- The number of parameters to tune is overwhelming: It’s not clear which parameters across the data parsing, ingestion, retrieval.
- PDFs are specifically a problem: I have complex docs with lots of messy formatting. How do I represent this in the right way so the LLM can understand it?
- Data syncing is a challenge: Production data often updates regularly, and continuously syncing new data brings a new set of challenges.
These are the problems we set out to solve with LlamaParse.
Data Pipelines to Bring you to Production
We built LlamaParse and LlamaParse as the data pipelines to get your RAG application to production more quickly.
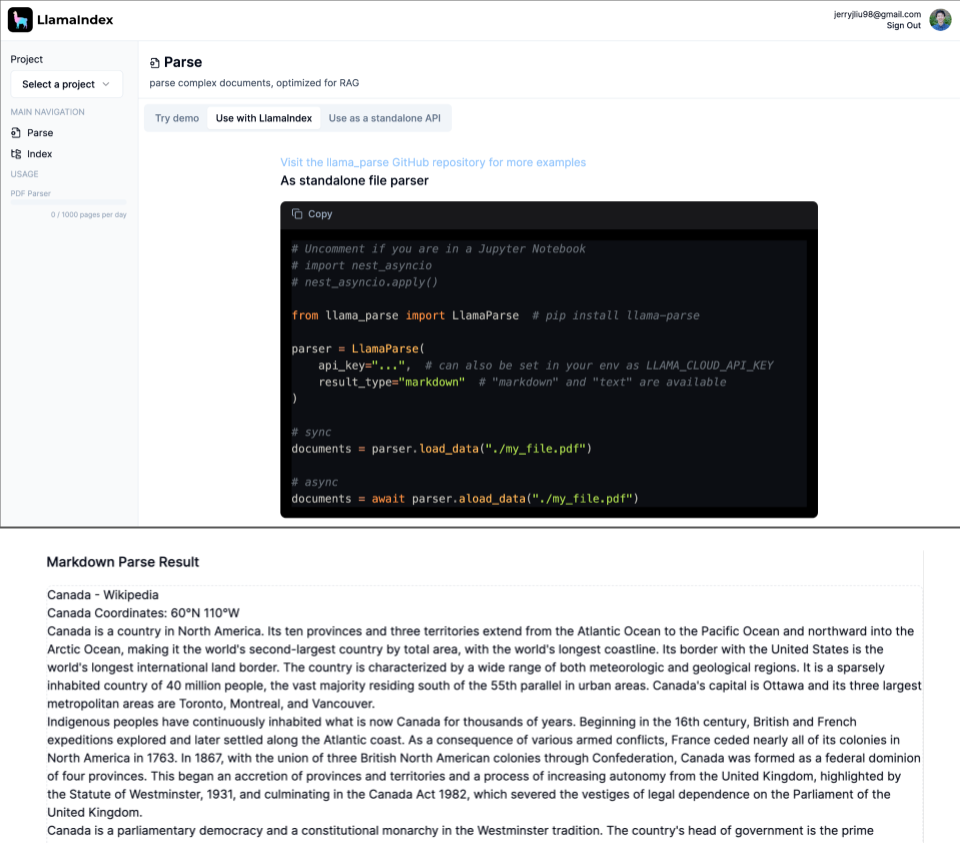
LlamaParse
LlamaParse is a state-of-the-art parser designed to specifically unlock RAG over complex PDFs with embedded tables and charts. This simply wasn’t possible before with other approaches, and we’re incredibly excited about this technology.
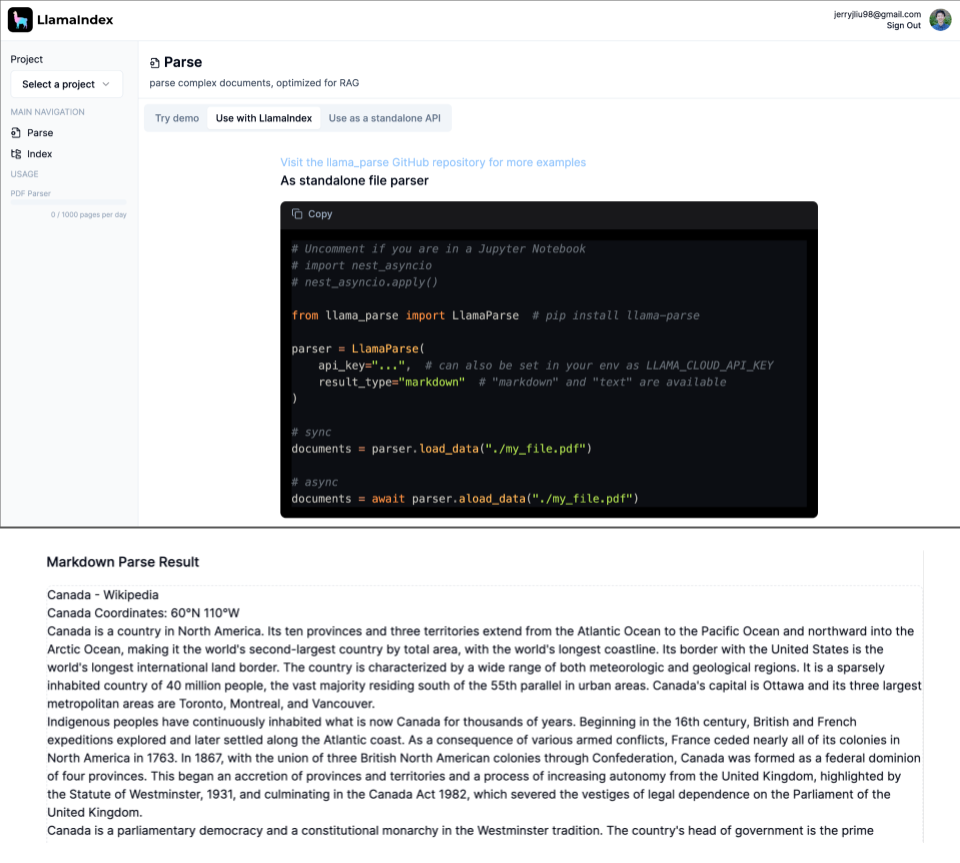
For the past few months we’ve been obsessed with this problem. This is a surprisingly prevalent use case across a variety of data types and verticals, from ArXiv papers to 10K filings to medical reports.
Naive chunking and retrieval algorithms do terribly. We were the first to propose a novel recursive retrieval RAG technique for being able to hierarchically index and query over tables and text in a document. The only challenge that remained was how to properly parse out tables and text in the first place.
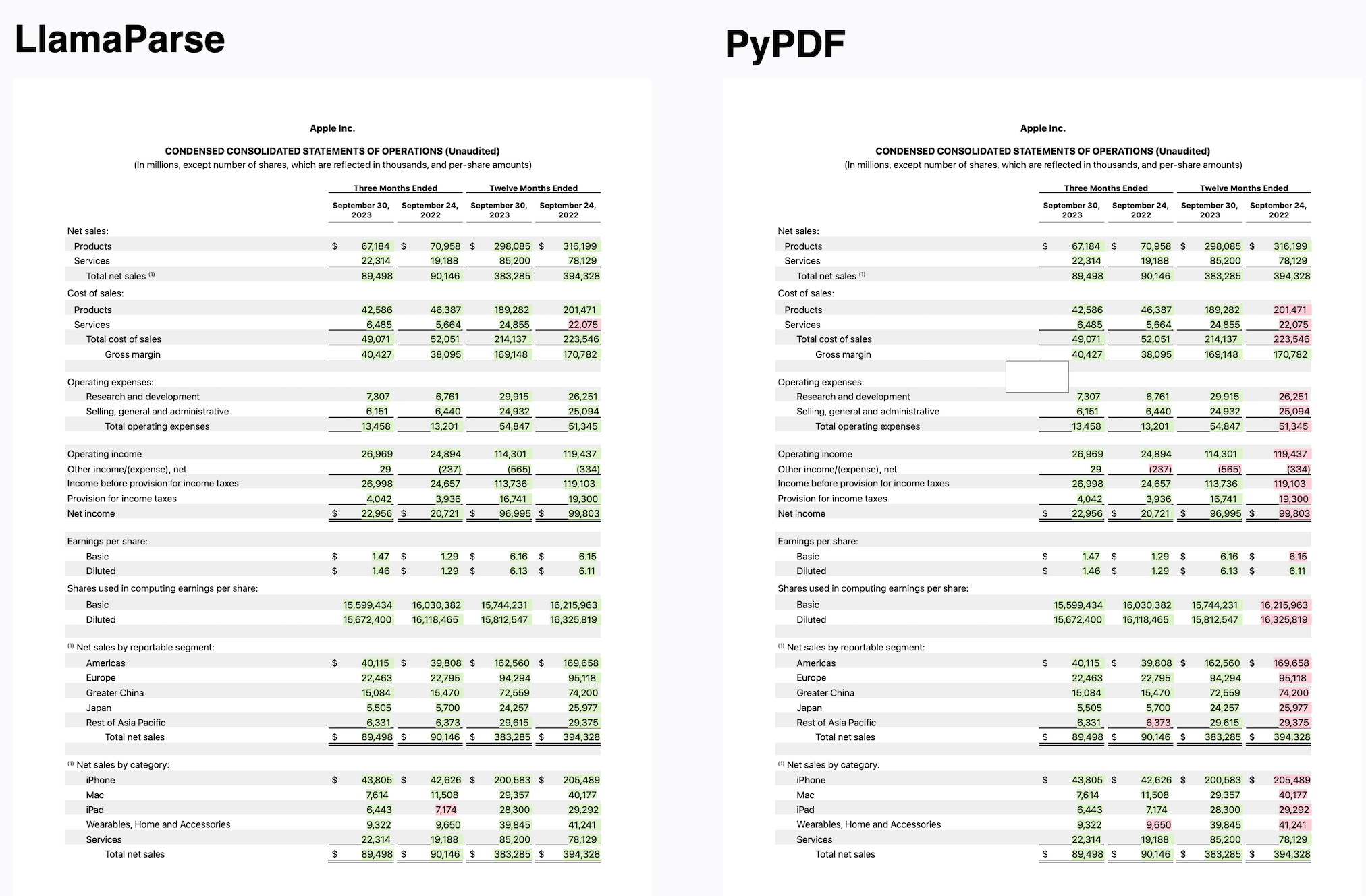
This is where LlamaParse comes in. We’ve developed a proprietary parsing service that is incredibly good at parsing PDFs with complex tables into a well-structured markdown format. This representation directly plugs into the advanced Markdown parsing and recursive retrieval algorithms available in the open-source library. The end result is that you are able to build RAG over complex documents that can answer questions over both tabular and unstructured data. Check out the results below for a comparison:


This service is available in a public preview mode: available to everyone, but with a usage limit (1k pages per day). It operates as a standalone service that also plugs into our managed ingestion and retrieval API (see below). Check out our LlamaParse onboarding here for more details.
from llama_parse import LlamaParse
parser = LlamaParse(
api_key="llx-...", # can also be set in your env as LLAMA_CLOUD_API_KEY
result_type="markdown", # "markdown" and "text" are available
verbose=True
)For unlimited commercial use of LlamaParse, get in touch with us.
Next Steps
Our early users have already given us important feedback on what they’d like to see next. Currently we primarily support PDFs with tables, but we are also building out better support for figures, and and an expanded set of the most popular document types: .docx, .pptx, .html.
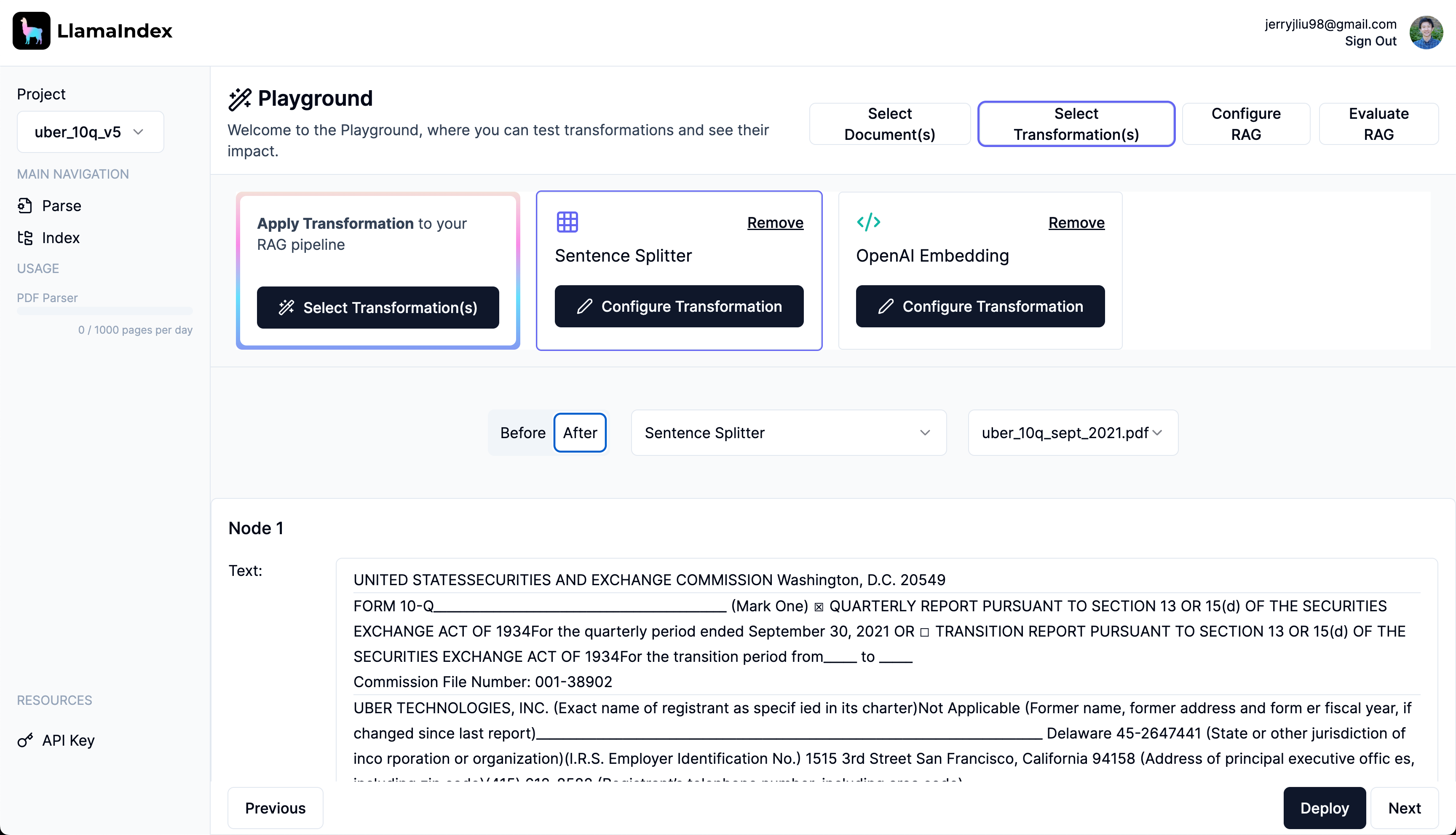
Managed Ingestion and Retrieval
Our other main offering in LlamaParse is a managed ingestion and retrieval API which allows you to easily declare performant data pipelines for any context-augmented LLM application.
Get clean data for your LLM application, so you can spend less time wrangling data and more time writing core application logic. LlamaParse empowers enterprise developers with the following benefits:
- Engineering Time Savings: Instead of having to write custom connectors and parsing logic in Python, our APIs allow you to directly connect to different data sources.
- Performance: we provide good out-of-the-box performance for different data types, while offering an intuitive path for experimentation, evaluation, and improvement.
- Ease Systems Complexity: Handle a large number of data sources with incremental updates.
Let’s do a brief tour through the core components!
- Ingestion: Declare a managed pipeline to process and transform/chunk/embed data backed by our 150+ data sources in LlamaHub and our 40+ storage integrations as destinations. Automatically handle syncing and load balancing. Define through the UI or our open-source library.
- Retrieval: Get access to state-of-the-art, advanced retrieval backed by our open-source library and your data storage. Wrap it in an easy-to-use REST API that you can consume from any language.
- Playground: Interactive UI to test and refine your ingestion/retrieval strategies pre-deployment, with evaluations in the loop.
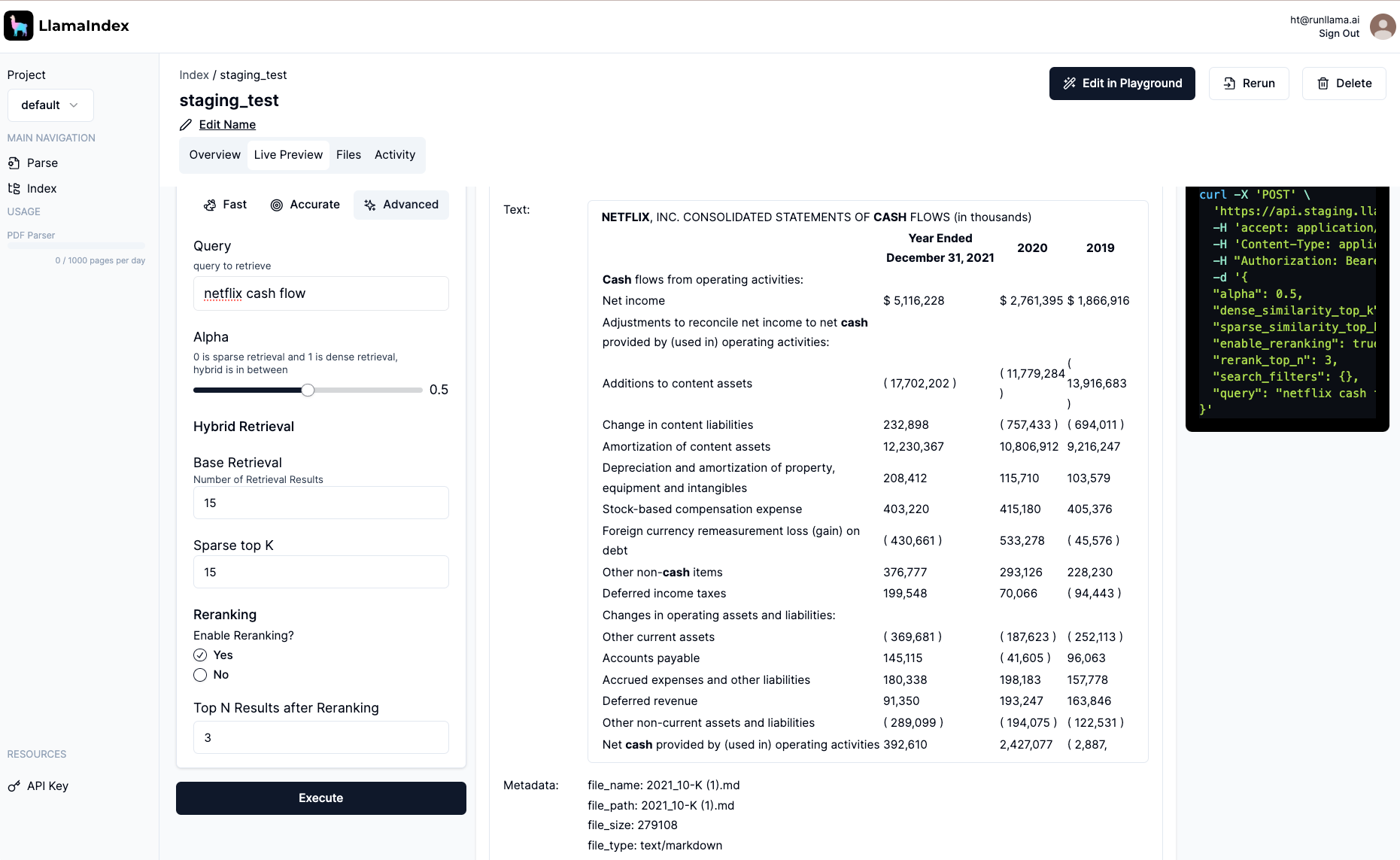
We are opening up a private beta to a limited set of enterprise partners for the managed ingestion and retrieval API. If you’re interested in centralizing your data pipelines and spending more time working on your actual RAG use cases, come talk to us.
Launch Partners and Collaborators
We opened up access to LlamaParse at our hackathon we co-hosted with Futureproof Labs and Datastax at the beginning of February. We saw some incredible applications of LlamaParse in action, including parsing building codes for Accessory Dwelling Unit (ADU) planning, parsing real-estate disclosures for home buying, and dozens more.
Eric Ciarla, co-founder at Mendable AI, incorporated LlamaParse into Mendable’s data stack: “We integrated LlamaParse into our open source data connector repo which powers our production ingestion suite. It was easy to integrate and more powerful than any of the alternatives we tried.”
We’re also excited to be joined by initial launch partners and collaborators in the LLM and AI ecosystem, from storage to compute.
DataStax
Datastax has incorporated LlamaParse into their RAGStack to bring a privacy-preserving out-of-the-box RAG solution for enterprises: "Last week one of our customers Imprompt has launched a pioneering 'Chat-to-Everything' platform leveraging RAGStack powered by LlamaIndex to enhance their enterprise offerings while prioritizing privacy." said Davor Bonaci, CTO and executive vice president, DataStax. "We're thrilled to partner with LlamaIndex to bring a streamlined solution to market. By incorporating LlamaIndex into RAGStack, we are providing enterprise developers with a comprehensive Gen AI stack that simplifies the complexities of RAG implementation, while offering long-term support and compatibility assurance.”
MongoDB
“MongoDB’s partnership with LlamaIndex allows for the ingestion of data into the MongoDB Atlas Vector database, and the retrieval of the index from Atlas via LlamaParse and LlamaParse, enabling the development of RAG systems and other AI applications,” said Greg Maxson, Global Lead, AI Ecosystems at MongoDB. “Now, developers can abstract complexities associated with data ingestion, simplify RAG pipeline implementations, and more cost effectively develop large language model applications, ultimately accelerating generative AI app development and more quickly bringing apps to market.”
Qdrant
André Zayarni, CEO of Qdrant, says “The Qdrant team is excited to partner with LlamaIndex to combine the power of optimal data preprocessing, vectorization, and ingestion with Qdrant for a powerful fullstack RAG solution.”
NVIDIA
We are also excited to collaborate with NVIDIA to integrate LlamaIndex with the NVIDIA AI Enterprise software platform for production AI: “LlamaParse will help enterprises get generative AI applications from development into production with connectors that link proprietary data to the power of large language models,” said Justin Boitano, vice president, Enterprise and Edge Computing, NVIDIA. “Pairing LlamaParse with NVIDIA AI Enterprise can accelerate the end-to-end LLM pipeline — including data processing, embedding creation, indexing, and model inference on accelerated computing across clouds, data centers and out to the edge.”
FAQ
Is this competitive with vector databases?
No. LlamaParse is focused primarily on data parsing and ingestion, which is a complementary layer to any vector storage provider. The retrieval layer is orchestration on top of an existing storage system. LlamaIndex open-source integrates with 40+ of the most popular vector databases, and we are working hard to do the following:
- Integrate LlamaParse with storage providers of existing design partners
- Make LlamaParse available in a more “self-serve” manner.
Next Steps
As mentioned in the above sections, LlamaParse is available for public preview starting today with a usage cap. LlamaParse is in a private preview mode; we are offering access to a limited set of enterprise design partners. If you’re interested come talk to us!
LlamaParse: Repo, Cookbook, Contact Us
LlamaParse: Contact Us


