Introduction
Large Language Models (LLMs) improve performance by accessing external data for background knowledge tasks related. However, existing approaches require costly modifications during LM’s pre-training or integrating the data store after the model has been trained. On the downside, both strategies lead to suboptimal performance.
To address this problem an AI Research team at Meta has proposed a method called RA-DIT: RETRIEVAL-AUGMENTED DUAL INSTRUCTION TUNING that allows any LLM to be upgraded to include retrieval features.
In this blog post, we will explore RA-DIT capabilities to have better performance on Retrieval Augmentation Generation (RAG) through building the dataset and fine-tuning the models.
The RA-DIT approach involves two distinct fine-tuning steps:
- Update a pre-trained LM to better use retrieved information.
- Update the retriever to return more relevant results
How it works
The RA-DIT approach separately fine-tunes the LLM and the retriever. The LLM is updated to maximize the probability of the correct answer given the retrieval-augmented instructions, while the retriever is updated to minimize how much the document is semantically similar (relevant) to the query.
Below we are going through each step from generating the fine-tuning dataset, fine-tuning the language model for better predictions, and refining the retrieval search process.
Fine-tuning Dataset
The fine-tuning dataset is tailored to enhance the language model’s ability to leverage knowledge and boost its contextual awareness during prediction generation. Generating Q/A pairs, summarizing data, and incorporating chain-of-thought reasoning can lead to improved results when integrated with the models.

Following our LamaIndex implementation, we retrieve the top_k nodes, generate Q/A pairs from the documents, and then augment the data. We use the Q/A pairs through the QueryResponseDataset module, which returns a (query, response) pair for the fine-tuning dataset. While the retrieval fine-tuning data set is created on Q/A pairs data.
Language Model Fine-tuning
With our fine-tuning dataset in hand, we can refine our LLM to achieve two main benefits: Adapt the LLM to better utilization of relevant background knowledge and train the LLM to produce accurate predictions even with incorrectly retrieved chunks, empowering the model to rely on its own knowledge.
Retriever Fine-tuning
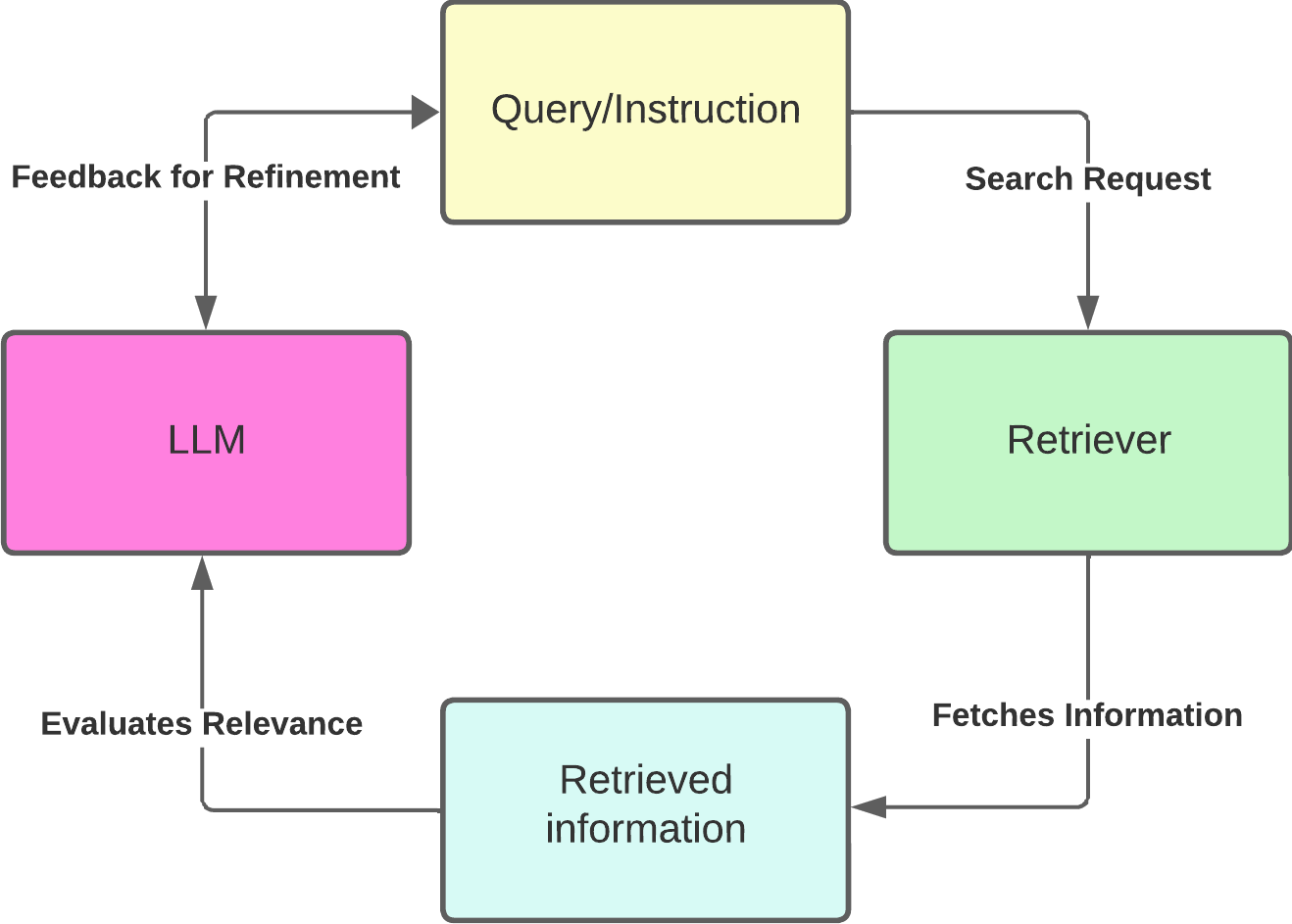
The retriever is fine-tuned using the LM-Supervised Retrieval (LSR) method. In this approach, the LLM assesses the information fetched by the retriever. If the LLM finds the information misaligned with the given query, it sends feedback to the retriever. Using this feedback, the retriever refines its search process, ensuring it fetches data that the LLM can effectively use. This collaboration enhances the overall quality of the answers provided.
Evaluation
To assess the suggested method, the authors employed specific datasets and metrics. Let’s delve into each of these to grasp the experimental results better.
Metrics
An “exact match” (EM) metric was used to measure how closely the model’s prediction matches the ground truth answer.
Dataset
The methodology was tested on two distinct tasks:
- Knowledge-intensive tasks.
- Commonsense reasoning.
Let’s explore the datasets utilized for both of these tasks.
Knowledge-intensive dataset
For knowledge-intensive tasks the selected datasets predominantly focus on the model’s capacity to access, understand, and relay deep and specific knowledge. They encompass questions rooted in facts, general trivia, and complex domain-specific queries;
The datasets used are MMLU, Natural Questions (NQ), TriviaQA, and a subset of tasks from the KILT benchmark.
Commonsense reasoning dataset
Commonsense reasoning datasets challenge the model’s ability to reason and infer based on general knowledge and everyday scenarios. They contain questions and scenarios that typically don’t rely on deep domain knowledge but rather on intuitive and general world understanding.
The datasets used are BoolQ, PIQA, SIQA, HellaSwag, WinoGrande, ARC-E, ARC-C, OBQA.
For a better understanding of how these datasets were utilized you can check the paper for better understanding.
Results
In a comparative analysis of model performance on knowledge-intensive (Table 2 below) and commonsense reasoning tasks (Table 3 below), three models were considered:
- LLAMA 65B
- LLAMA 65B REPLUG (only retrieval augmentation)
- RA-DIT 65B
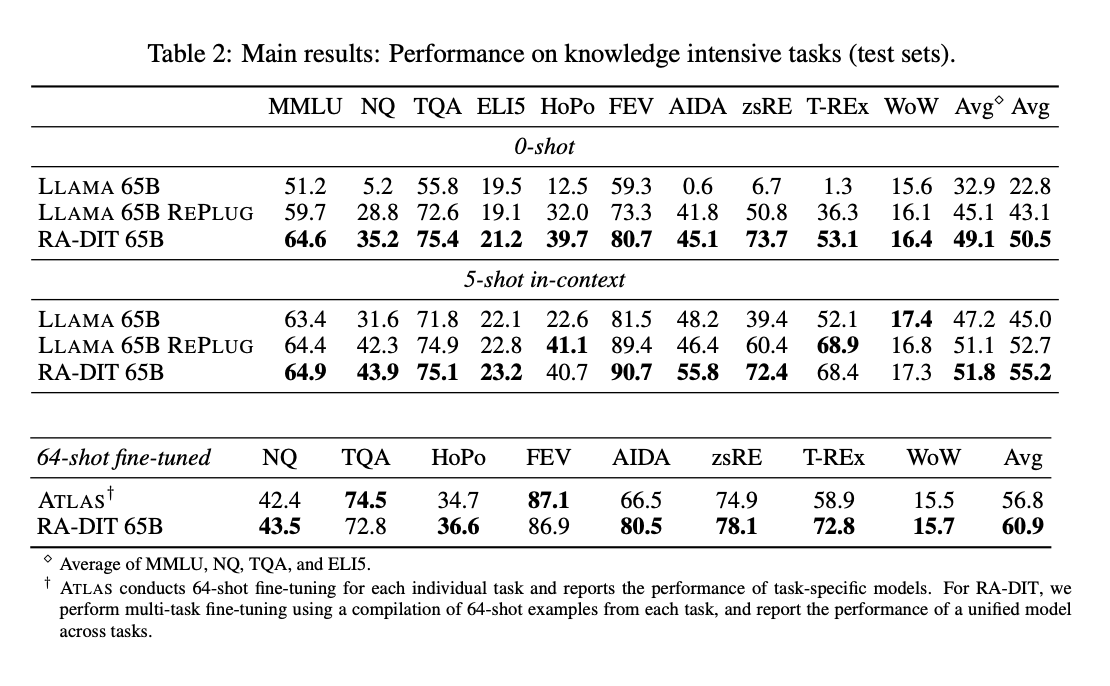
Knowledge Intensive Tasks
Evaluations are conducted in 0-shot, 5-shot, and 64-shot fine-tuning settings.
0-shot Analysis:
- RA-DIT 65B demonstrated superior performance with an average EM score of 50.5 across all tasks.
- It outperformed LLAMA 65B REPlug (43.1 average) and significantly surpassed LLAMA 65B (32.9 average).
5-shot Analysis:
- RA-DIT 65B maintained its lead with an average EM score of 55.2.
- LLAMA 65B REPlug followed closely with 52.7, while LLAMA 65B achieved an average of 45.0.
In a separate evaluation for 64-shot fine-tuning, two models were analyzed: ATLAS and RA-DIT 65B.
64-shot Fine-tuning:
- RA-DIT 65B achieved an average performance of 60.9 across all tasks, slightly surpassing ATLAS, which obtained an average score of 56.8
Commonsense reasoning
RA-DIT 65B was benchmarked in order to evaluate the impact of retrieval-augmented instruction tuning on the LLMs parametric knowledge and reasoning capabilities.
In this experiment without retrieval augmentation, RA-DIT showed improvements over base LLAMA 65B models on 7 of 8 evaluation datasets, indicating that the parametric knowledge and reasoning capabilities of the LLM component are in general preserved.

In summary, RA-DIT 65B consistently delivered great results, surpassing its competitors in multiple scenarios, underscoring its proficiency and aptitude in knowledge-intensive tasks while showing that the parametric knowledge and reasoning capabilities of the LLM are still preserved.
Conclusion
The RA-DIT approach provides a structured method to enhance how Large Language Models utilize external data. Through the dual fine-tuning of both the model and the retriever, we target better accuracy and context-awareness in responses.
The incorporation of the LSR technique fosters a more efficient data retrieval process, ensuring that the generated answers are both relevant and informed, the final results show that RA-DIT surpasses un-tuned RALM approaches like REPLUG showing competitive results.
You can explore more about the LLamaIndex implementation at: https://docs.llamaindex.ai/en/stable/examples/finetuning/knowledge/finetune_retrieval_aug.html#fine-tuning-with-retrieval-augmentation
References
RA-DIT paper: https://arxiv.org/abs/2310.01352