

Introduction
Retrieval-augmented generation (RAG) has introduced an innovative approach that fuses the extensive retrieval capabilities of search systems with the LLM. When implementing a RAG system, one critical parameter that governs the system’s efficiency and performance is the chunk_size. How does one discern the optimal chunk size for seamless retrieval? This is where LlamaIndex Response Evaluation comes in handy. In this blog post, we'll guide you through the steps to determine the best chunk size using LlamaIndex’s Response Evaluation module. If you're unfamiliar with the Response Evaluation module, we recommend reviewing its documentation before proceeding.
Why Chunk Size Matters
Choosing the right chunk_size is a critical decision that can influence the efficiency and accuracy of a RAG system in several ways:
- Relevance and Granularity: A small
chunk_size, like 128, yields more granular chunks. This granularity, however, presents a risk: vital information might not be among the top retrieved chunks, especially if thesimilarity_top_ksetting is as restrictive as 2. Conversely, a chunk size of 512 is likely to encompass all necessary information within the top chunks, ensuring that answers to queries are readily available. To navigate this, we employ the Faithfulness and Relevancy metrics. These measure the absence of ‘hallucinations’ and the ‘relevancy’ of responses based on the query and the retrieved contexts respectively. - Response Generation Time: As the
chunk_sizeincreases, so does the volume of information directed into the LLM to generate an answer. While this can ensure a more comprehensive context, it might also slow down the system. Ensuring that the added depth doesn't compromise the system's responsiveness is crucial.
In essence, determining the optimal chunk_size is about striking a balance: capturing all essential information without sacrificing speed. It's vital to undergo thorough testing with various sizes to find a configuration that suits the specific use case and dataset.
For a practical evaluation in choosing the right chunk_size, you can access and run the following setup on this Google Colab Notebook.
Setup
Before embarking on the experiment, we need to ensure all requisite modules are imported:
import nest_asyncio
nest_asyncio.apply()
from llama_index import (
SimpleDirectoryReader,
VectorStoreIndex,
ServiceContext,
)
from llama_index.evaluation import (
DatasetGenerator,
FaithfulnessEvaluator,
RelevancyEvaluator
)
from llama_index.llms import OpenAI
import openai
import time
openai.api_key = 'OPENAI-API-KEY'Download Data
We’ll be using the Uber 10K SEC Filings for 2021 for this experiment.
!mkdir -p 'data/10k/'
!wget 'https://raw.githubusercontent.com/jerryjliu/llama_index/main/docs/examples/data/10k/uber_2021.pdf' -O 'data/10k/uber_2021.pdf'Load Data
Let’s load our document.
documents = SimpleDirectoryReader("./data/10k/").load_data()Question Generation
To select the right chunk_size, we'll compute metrics like Average Response time, Faithfulness, and Relevancy for various chunk_sizes. The DatasetGenerator will help us generate questions from the documents.
data_generator = DatasetGenerator.from_documents(documents)
eval_questions = data_generator.generate_questions_from_nodes()Setting Up Evaluators
We are setting up the GPT-4 model to serve as the backbone for evaluating the responses generated during the experiment. Two evaluators, FaithfulnessEvaluator and RelevancyEvaluator, are initialised with the service_context .
- Faithfulness Evaluator — It is useful for measuring if the response was hallucinated and measures if the response from a query engine matches any source nodes.
- Relevancy Evaluator — It is useful for measuring if the query was actually answered by the response and measures if the response + source nodes match the query.
# We will use GPT-4 for evaluating the responses
gpt4 = OpenAI(temperature=0, model="gpt-4")
# Define service context for GPT-4 for evaluation
service_context_gpt4 = ServiceContext.from_defaults(llm=gpt4)
# Define Faithfulness and Relevancy Evaluators which are based on GPT-4
faithfulness_gpt4 = FaithfulnessEvaluator(service_context=service_context_gpt4)
relevancy_gpt4 = RelevancyEvaluator(service_context=service_context_gpt4)Response Evaluation For A Chunk Size
We evaluate each chunk_size based on 3 metrics.
- Average Response Time.
- Average Faithfulness.
- Average Relevancy.
Here’s a function, evaluate_response_time_and_accuracy, that does just that which has:
- VectorIndex Creation.
- Building the Query Engine.
- Metrics Calculation.
# Define function to calculate average response time, average faithfulness and average relevancy metrics for given chunk size
# We use GPT-3.5-Turbo to generate response and GPT-4 to evaluate it.
def evaluate_response_time_and_accuracy(chunk_size, eval_questions):
"""
Evaluate the average response time, faithfulness, and relevancy of responses generated by GPT-3.5-turbo for a given chunk size.
Parameters:
chunk_size (int): The size of data chunks being processed.
Returns:
tuple: A tuple containing the average response time, faithfulness, and relevancy metrics.
"""
total_response_time = 0
total_faithfulness = 0
total_relevancy = 0
# create vector index
llm = OpenAI(model="gpt-3.5-turbo")
service_context = ServiceContext.from_defaults(llm=llm, chunk_size=chunk_size)
vector_index = VectorStoreIndex.from_documents(
eval_documents, service_context=service_context
)
# build query engine
query_engine = vector_index.as_query_engine()
num_questions = len(eval_questions)
# Iterate over each question in eval_questions to compute metrics.
# While BatchEvalRunner can be used for faster evaluations (see: https://docs.llamaindex.ai/en/latest/examples/evaluation/batch_eval.html),
# we're using a loop here to specifically measure response time for different chunk sizes.
for question in eval_questions:
start_time = time.time()
response_vector = query_engine.query(question)
elapsed_time = time.time() - start_time
faithfulness_result = faithfulness_gpt4.evaluate_response(
response=response_vector
).passing
relevancy_result = relevancy_gpt4.evaluate_response(
query=question, response=response_vector
).passing
total_response_time += elapsed_time
total_faithfulness += faithfulness_result
total_relevancy += relevancy_result
average_response_time = total_response_time / num_questions
average_faithfulness = total_faithfulness / num_questions
average_relevancy = total_relevancy / num_questions
return average_response_time, average_faithfulness, average_relevancyTesting Across Different Chunk Sizes
We’ll evaluate a range of chunk sizes to identify which offers the most promising metrics.
chunk_sizes = [128, 256, 512, 1024, 2048]
for chunk_size in chunk_sizes:
avg_response_time, avg_faithfulness, avg_relevancy = evaluate_response_time_and_accuracy(chunk_size, eval_questions)
print(f"Chunk size {chunk_size} - Average Response time: {avg_response_time:.2f}s, Average Faithfulness: {avg_faithfulness:.2f}, Average Relevancy: {avg_relevancy:.2f}")Bringing It All Together
Let’s compile the processes:
import nest_asyncio
nest_asyncio.apply()
from llama_index import (
SimpleDirectoryReader,
VectorStoreIndex,
ServiceContext,
)
from llama_index.evaluation import (
DatasetGenerator,
FaithfulnessEvaluator,
RelevancyEvaluator
)
from llama_index.llms import OpenAI
import openai
import time
openai.api_key = 'OPENAI-API-KEY'
# Download Data
!mkdir -p 'data/10k/'
!wget 'https://raw.githubusercontent.com/jerryjliu/llama_index/main/docs/examples/data/10k/uber_2021.pdf' -O 'data/10k/uber_2021.pdf'
# Load Data
reader = SimpleDirectoryReader("./data/10k/")
documents = reader.load_data()
# To evaluate for each chunk size, we will first generate a set of 40 questions from first 20 pages.
eval_documents = documents[:20]
data_generator = DatasetGenerator.from_documents()
eval_questions = data_generator.generate_questions_from_nodes(num = 20)
# We will use GPT-4 for evaluating the responses
gpt4 = OpenAI(temperature=0, model="gpt-4")
# Define service context for GPT-4 for evaluation
service_context_gpt4 = ServiceContext.from_defaults(llm=gpt4)
# Define Faithfulness and Relevancy Evaluators which are based on GPT-4
faithfulness_gpt4 = FaithfulnessEvaluator(service_context=service_context_gpt4)
relevancy_gpt4 = RelevancyEvaluator(service_context=service_context_gpt4)
# Define function to calculate average response time, average faithfulness and average relevancy metrics for given chunk size
def evaluate_response_time_and_accuracy(chunk_size):
total_response_time = 0
total_faithfulness = 0
total_relevancy = 0
# create vector index
llm = OpenAI(model="gpt-3.5-turbo")
service_context = ServiceContext.from_defaults(llm=llm, chunk_size=chunk_size)
vector_index = VectorStoreIndex.from_documents(
eval_documents, service_context=service_context
)
query_engine = vector_index.as_query_engine()
num_questions = len(eval_questions)
for question in eval_questions:
start_time = time.time()
response_vector = query_engine.query(question)
elapsed_time = time.time() - start_time
faithfulness_result = faithfulness_gpt4.evaluate_response(
response=response_vector
).passing
relevancy_result = relevancy_gpt4.evaluate_response(
query=question, response=response_vector
).passing
total_response_time += elapsed_time
total_faithfulness += faithfulness_result
total_relevancy += relevancy_result
average_response_time = total_response_time / num_questions
average_faithfulness = total_faithfulness / num_questions
average_relevancy = total_relevancy / num_questions
return average_response_time, average_faithfulness, average_relevancy
# Iterate over different chunk sizes to evaluate the metrics to help fix the chunk size.
for chunk_size in [128, 256, 512, 1024, 2048]
avg_time, avg_faithfulness, avg_relevancy = evaluate_response_time_and_accuracy(chunk_size)
print(f"Chunk size {chunk_size} - Average Response time: {avg_time:.2f}s, Average Faithfulness: {avg_faithfulness:.2f}, Average Relevancy: {avg_relevancy:.2f}")Result
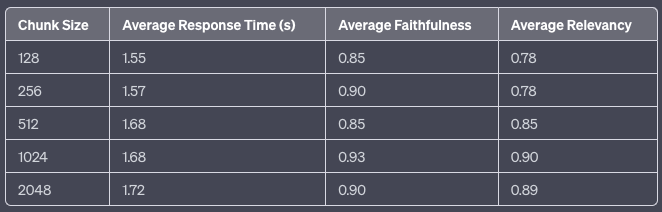
The above table illustrates that as the chunk size increases, there is a minor uptick in the Average Response Time. Interestingly, the Average Faithfulness seems to reach its zenith at chunk_sizeof 1024, whereas Average Relevancy shows a consistent improvement with larger chunk sizes, also peaking at 1024. This suggests that a chunk size of 1024 might strike an optimal balance between response time and the quality of the responses, measured in terms of faithfulness and relevancy.
Conclusion
Identifying the best chunk size for a RAG system is as much about intuition as it is empirical evidence. With LlamaIndex’s Response Evaluation module, you can experiment with various sizes and base your decisions on concrete data. When building a RAG system, always remember that chunk_size is a pivotal parameter. Invest the time to meticulously evaluate and adjust your chunk size for unmatched results.


