

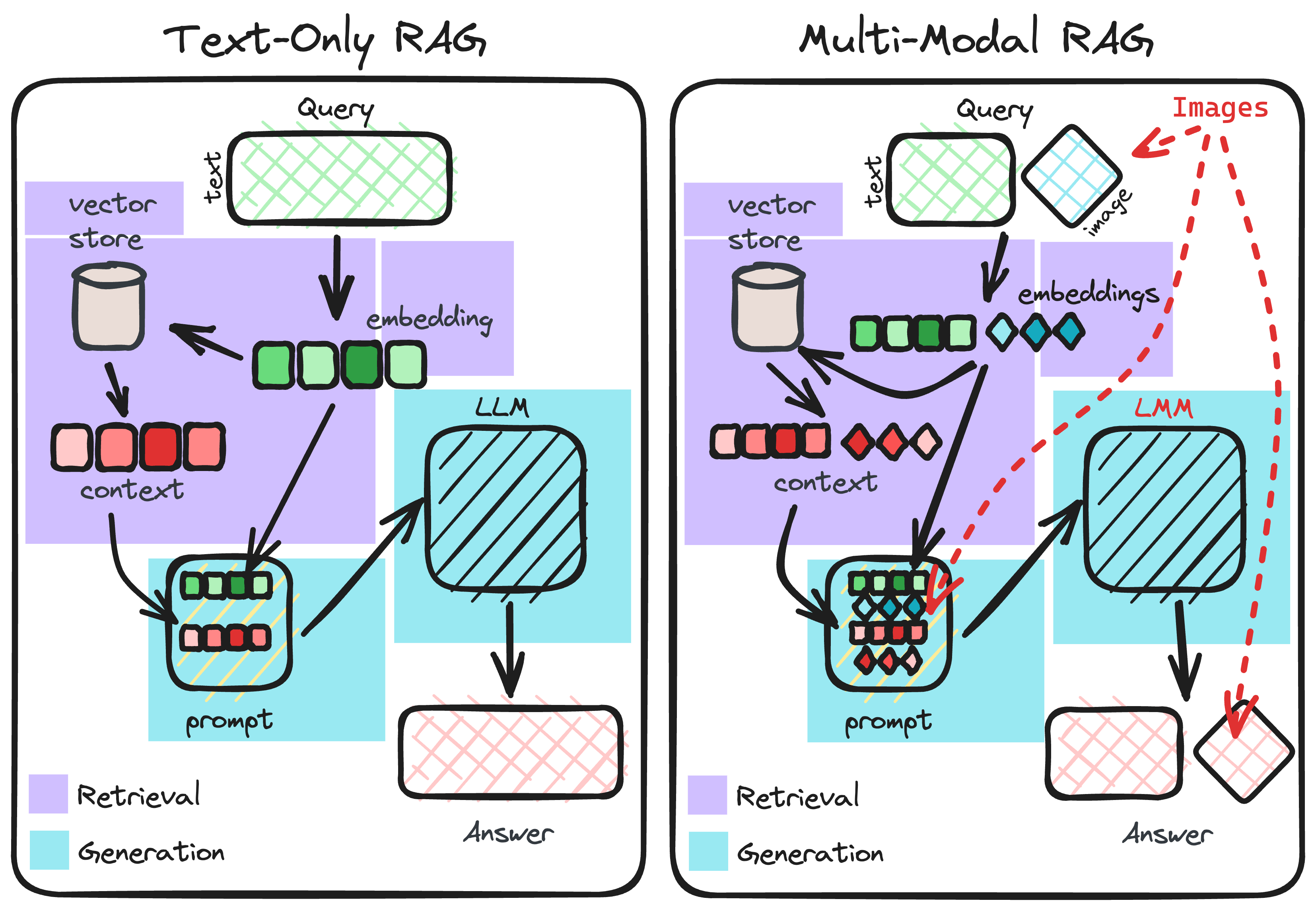
A few days ago, we published a blog on Multi-Modal RAG (Retrieval-Augmented Generation) and our latest (still in beta) abstractions to help enable and simplify building them. In this post, we now go over the important topic of how one can sensibly evaluate Multi-Modal RAG systems.
A natural starting point is to consider how evaluation was done in traditional, text-only RAG and then ask ourselves how this ought to be modified to suit the multi-modal scenario (e.g., in text-only RAG, we use an LLM, but in multi-modal RAG we require a Large Multi-Modal Model or LMM for short). This is exactly what we’ll do next and as you’ll see, the overarching evaluation framework stays the same as it was in the text-only RAG, requiring only a few additions and modifications in order to make it more multi-modal appropriate.
Primer: Multi-Modal RAG vs Text-Only RAG
Let’s consider the main differences between multi-modal and text-only RAG. Below are two tables that describe the RAG build considerations as well as query-time pipeline and compares and contrasts multi-modal and text-only cases against them.


Evaluation Of Text-Only RAG
For text-only RAG, the standard approach is to separately consider the evaluation of two stages: Retrieval and Generation.
Retriever Evaluation: are the retrieved documents relevant to the user query?
Some of the more popular metrics for retrieval evaluation include recall, hit rate, mean reciprocal rank, mean average precision, and normalized discounted cumulative gain. The first two of these metrics recall and hit rate, don’t consider the position (or ranking) of the relevant documents, whereas all the others do in their own respective ways.
Generator Evaluation: does the response use the retrieved documents to sufficiently answer the user query?
In abstractive question-answering systems, like the kinds we’re talking about in this blog, measuring the generated response is made more tricky due to the fact that there isn’t just one way to sufficiently answer a query in written language — there’s plenty!
So, in this case, our measurement relies on subjective judgement, which can be performed by humans, though this is costly and unscalable. An alternative approach, is to use an LLM judge to measure things like relevancy and faithfulness.
- Relevancy: considers textual context and evaluates how much the generated response matches the query.
- Faithfulness: evaluates how much the generated response matches the retrieved textual context.
For both of these, the retrieved context as well as the query and generated response are passed to the LLM judge. (This pattern of using an LLM to judge the responses has been termed by some researchers of the space as LLM-As-A-Judge (Zheng et al., 2023).)
Currently, the llama-index (v0.9.2) library supports hit-rate and mean reciprocal rank for retrieval evaluation, as well as relevancy, faithfulness and a few others for generator evaluation. (Check out our Evaluation guides in our docs!).
Evaluation Of Multi-Modal RAG
For the multi-modal case, the evaluation can (and should) still be carried out with respect to the different stages of retrieval and generation.
Separating Out Retrieval Evaluation For Text and Image Modalities
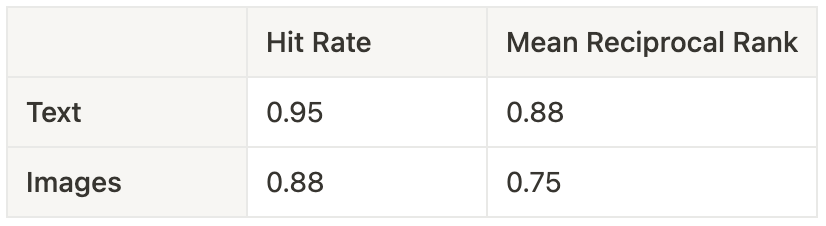
Now that retrieved documents can come in two forms, it would seem most sensible to consider computing the usual retrieval evaluation metrics separately for images and text. In this way, you have more knowledge as to which aspect of the multi-modal retriever is working well and what isn’t. One can then apply a desired weighting scheme to establish a single aggregated retrieval score per metric.
Hit Rate Mean Reciprocal Rank Text 0.95 0.88 Images 0.88 0.75
Using Multi-Modal LLMs For Generator Evaluations (LMM-As-A-Judge)
Multi-modal models (i.e., LMMs) like OpenAI’s GPT-4V or open-source alternatives like LLaVA are able to take in both input and image context to produce an answer the user query. As in text-only RAG, we are also concerned about the “relevancy” and “faithfulness” of these generated answers. But in order to be able to compute such metrics in the multi-modal case, we would need a judge model that is also able to take in the context images and text data. Thus, in the multi-modal case, we adopt the LMM-As-A-Judge pattern in order to compute relevancy and faithfulness as well as other related metrics!
- Relevancy (multi-modal): considers textual and visual context and evaluates how much the generated response matches the query.
- Faithfulness (multi-modal): evaluates how much the generated response matches the retrieved textual and visual context.
If you want to test these out, then you’re in luck as we’ve recently released our beta Multi-Modal Evaluator abstractions! See the code snippet below for how one can use these abstractions to perform their respective evaluations on a generated response to a given query.
from llama_index.evaluation.multi_modal import (
MultiModalRelevancyEvaluator,
MultiModalFaithfulnessEvaluator
)
from llama_index.multi_modal_llm import OpenAIMultiModal
relevancy_judge = MultiModalRelevancyEvaluator(
multi_modal_llm=OpenAIMultiModal(
model="gpt-4-vision-preview",
max_new_tokens=300,
)
)
faithfulness_judge = MultiModalRelevancyEvaluator(
multi_modal_llm=OpenAIMultiModal(
model="gpt-4-vision-preview",
max_new_tokens=300,
)
)
# Generated response to a query and its retrieved context information
query = ...
response = ...
contexts = ... # retrieved text contexts
image_paths = ... # retrieved image contexts
# Evaluations
relevancy_eval = relevancy_judge.evaluate(
query=query,
response=response,
contexts=contexts,
image_paths=image_paths
)
faithfulness_eval = faithfulness_judge.evaluate(
query=query,
response=response,
contexts=contexts,
image_paths=image_paths
)A Few Important Remarks
First, it is worth mentioning that using LLMs or LMMs to judge generated responses has its drawbacks. These judges are generative models themselves and can suffer from hallucinations and other inconsistencies. Though studies have shown that strong LLMs can align to human judgments at a relatively high rate (Zheng et al., 2023), using them in production systems should be handled with higher standards of care. At time of writing, there has no been study to show that strong LMMs can also align well to human judgements.
Secondly, the evaluation of a generator touches mostly on the evaluation of its knowledge and reasoning capabilities. There are other important dimensions on which to evaluate LLMs and LMMs, including Alignment and Safety — see Evaluating LMMs: A Comprehensive Survey for more information.
Go forth and evaluate
In this post, we covered how evaluation can be performed on multi-modal RAG systems. We believe that separating out the retrieval evaluations per modalities for increased visibility as well as the LMM-As-A-Judge represent a sensible extension of the evaluation framework for text-only RAG. We encourage you to check out our practical notebook guides as well as docs for more information on how you can not only build Multi-Modal RAGs but also adequately evaluate them!


