Today we’re incredibly excited to announce the launch of a big new capability within LlamaIndex: Data Agents.
Data Agents are LLM-powered knowledge workers that can intelligently perform various tasks over your data, in both a “read” and “write” function. They are capable of the following:
- Perform automated search and retrieval over different types of data — unstructured, semi-structured, and structured.
- Calling any external service API in a structured fashion. They can either process the response immediately, or index/cache this data for future use.
- Storing conversation history.
- Using all of the above to fulfill both simple and complex data tasks.
We’ve worked hard to provide abstractions, services, and guides on both the agents side and tools side in order to build data agents. Today’s launch consists of the following key components:
- General Agent/Tool Abstractions: a set of abstractions to build agent loops, and to have those loops interact with tools according to a structured API definition.
- LlamaHub Tool Repository: A brand-new section within LlamaHub that consists of 15+ Tools (e.g. Google Calendar, Notion, SQL, OpenAPI) that can be connected. Opening to community contributions!
See below for full details. We show you how to build a Gmail agent that’s able to automatically create/send emails in <10 lines of code!
Context
Our core mission at LlamaIndex is to unlock the full capabilities of LLMs over your external sources of data. It provides a set of tools to both define “state” (how to parse/structure your data), and “compute” (how to query your data). Up until now, our framework has primarily focused on search and retrieval use case. We have an incredible suite of tools and capabilities that not only allow you to create the basic RAG stack around a vector database + top-k retrieval, but also offer much greater functionality beyond that.
A lot of that technology used to lie in our query engines. Our goal was to increase the capability of query engines to answer a wide range of different queries. In order to do this, we had to improve the “reasoning” capabilities of these query engines. As a result some of our existing query capabilities contain “agent-like” components: we have query engines capable of chain-of-thought reasoning, query decomposition, and routing. In the process, users had the option of choosing from a spectrum of query engines that had more constrained reasoning capabilities to less constrained capabilities.
But there was a huge opportunity for LLMs to have an even richer set of interactions with data; they should be capable of general reasoning over any set of tools, whether from a database or an API. They should also be capable of both “read” and “write” capabilities — the ability to not only understand state but also modify it. As a result they should be able to do more than search and retrieval from a static knowledge source.
Some existing services, toolkits, and research papers have already demonstrated the possibilities of LLM-powered “agents” that can interact with the external environment. Using these existing approaches as inspiration, we saw an opportunity to build a principled series of abstractions enabling anyone to build knowledge workers over their data.
Core Components of Data Agents
Building a data agent requires the following core components:
- A reasoning loop
- Tool abstractions
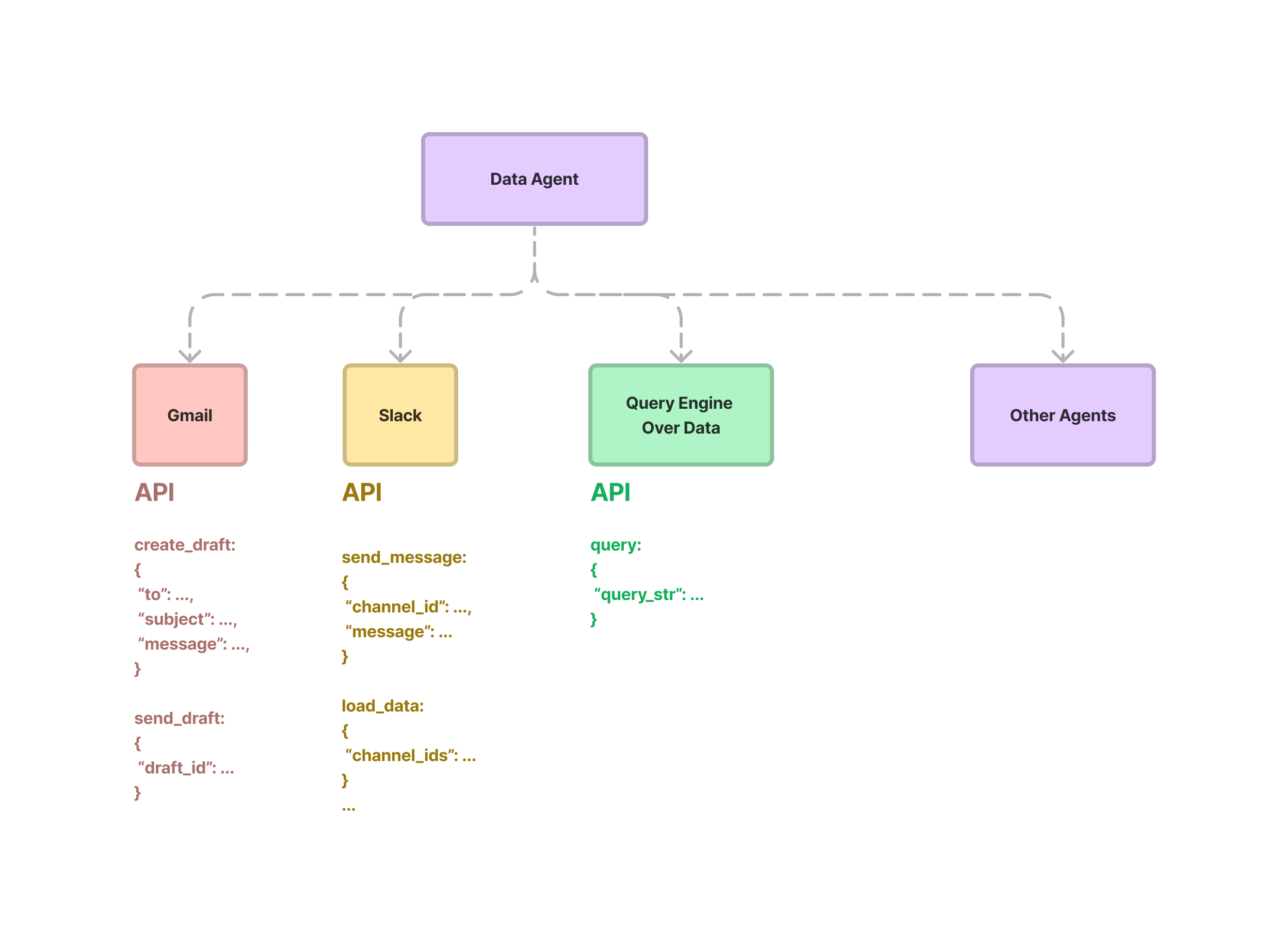
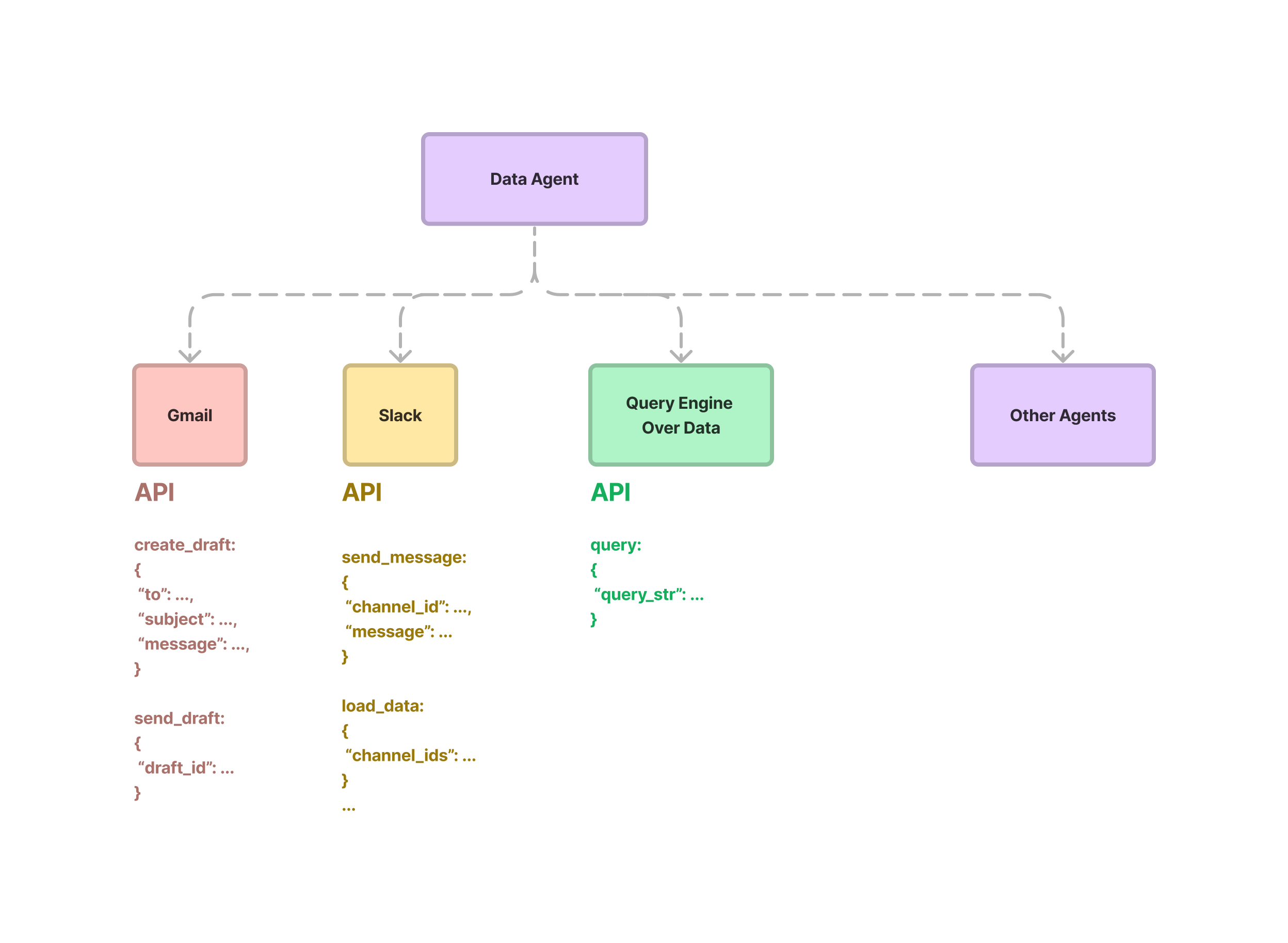
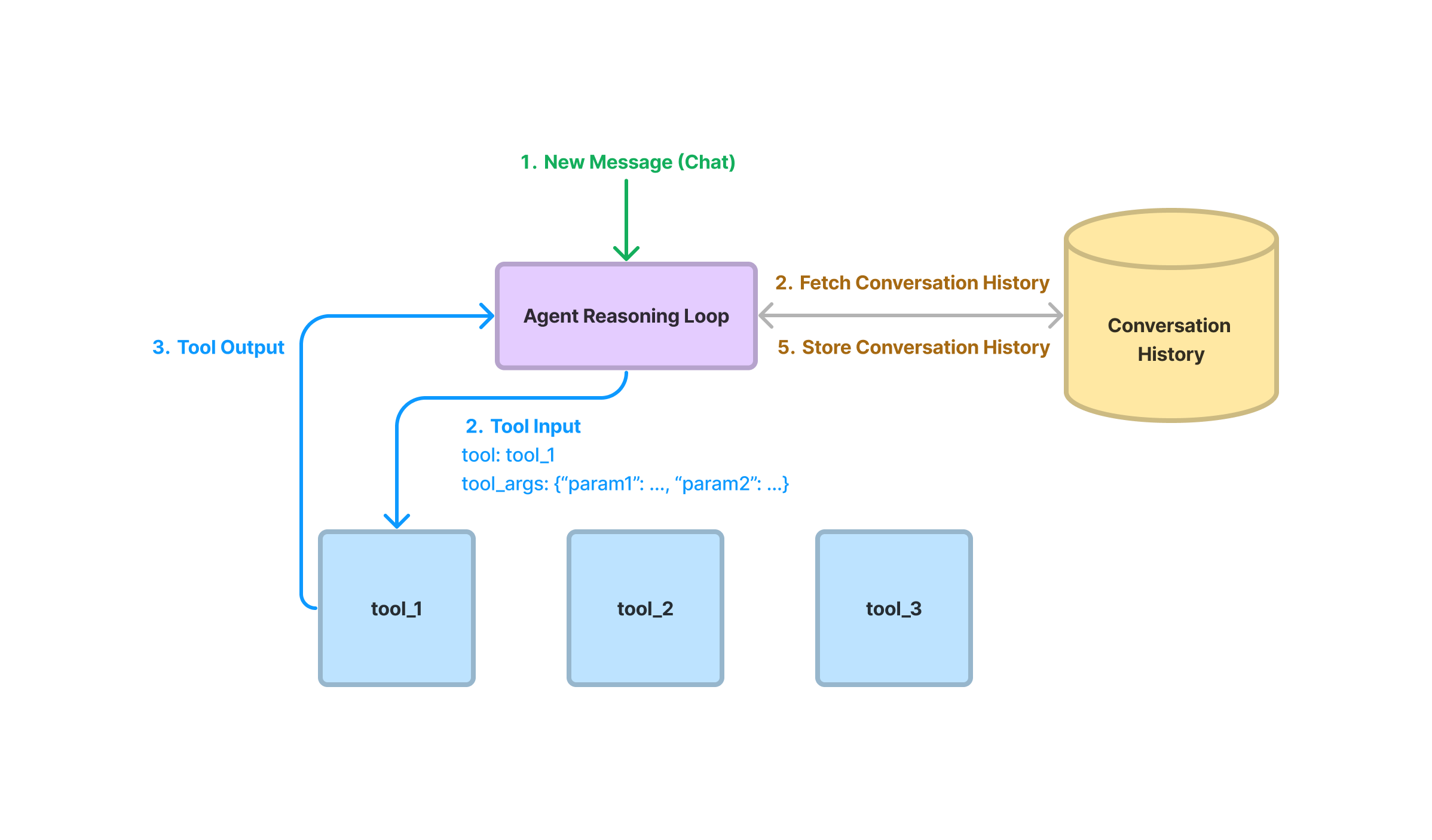
At a high-level, a data agent is provided with a set of APIs, or Tools, to interact with. These APIs can return information about the world, or perform an action that modifies state. Each Tool exposes a request/response interface. The request is a set of structured parameters, and the response can be any format (at least conceptually, in most cases the response here is a text string of some form).
Given an input task, the data agent uses a reasoning loop to decide which tools to use, in which sequence, and the parameters to call each tool. The “loop” can conceptually be very simple (a one-step tool selection process), or complex (a multi-step selection process, where a multitude of tools are picked at each step).
These components are described in more detail below.
Agent Abstraction + Reasoning Loop
We have support for the following agents:
- OpenAI Function agent (built on top of the OpenAI Function API)
- a ReAct agent (which works across any chat/text completion endpoint).
You can use them as the following:
from llama_index.agent import OpenAIAgent, ReActAgent
from llama_index.llms import OpenAI
# import and define tools
...
# initialize llm
llm = OpenAI(model="gpt-3.5-turbo-0613")
# initialize openai agent
agent = OpenAIAgent.from_tools(tools, llm=llm, verbose=True)
# initialize ReAct agent
agent = ReActAgent.from_tools(tools, llm=llm, verbose=True)
# use agent
response = agent.chat("What is (121 * 3) + 42?")Each agent takes in a set of Tools. The details behind our tool abstractions are provided below. Each agent also supports two main methods for taking in an input task — chat and query. Note that these are the core methods used in our ChatEngine and QueryEngine respectively. In fact that our base agent class (BaseAgent) simply inherits from BaseChatEngine and BaseQueryEngine. chat allows the agent to utilize previously stored conversation history, whereas query is a stateless call - history/state is not preserved over time.
The reasoning loop depends on the type of agent. The OpenAI agent calls the OpenAI function API in a while loop, since the tool decision logic is baked into the function API. Given an input prompt and previous chat history (which includes previous function calls), the function API will decide whether to make another function call (pick a Tool), or return an assistant message. If the API returns a function call, then we are responsible for executing the function and passing in a function message in the chat history. If the API returns an assistant message, then the loop is complete (we assume the task is solved).
The ReAct agent uses general text completion endpoints, so it can be used with any LLM. A text completion endpoint has a simple input str → output str format, which means that the reasoning logic must be encoded in the prompt. The ReAct agent uses an input prompt inspired by the ReAct paper (and adapted into other versions), in order to decide which tool to pick. It looks something like this:
...
You have access to the following tools:
{tool_desc}
To answer the question, please use the following format.
```
Thought: I need to use a tool to help me answer the question.
Action: tool name (one of {tool_names})
Action Input: the input to the tool, in a JSON format representing the kwargs (e.g. {{"text": "hello world", "num_beams": 5}})
```
Please use a valid JSON format for the action input. Do NOT do this {{'text': 'hello world', 'num_beams': 5}}.
If this format is used, you will receive a response in the following format:
```
Observation: tool response
```
...We implement ReAct natively over chat prompts; the reasoning loop is implemented as an alternating series of assistant and user messages. The Thought/Action/Action Input section is represented as an assistant message, and the Observation section is implemented as a user message.
Note: the ReAct prompt expects not only the name of the tool to pick, but also the parameters to fill in the tool in a JSON format. This makes the output not dissimilar from the output of the OpenAI Function API — the main difference is that in the case of the function API, the tool-picking logic is baked into the API itself (through a finetuned model), whereas here it is elicited through explicit prompting.
Tool Abstractions
Having proper tool abstractions is at the core of building data agents. Defining a set of Tools is similar to defining any API interface, with the exception that these Tools are meant for agent rather than human use. We allow users to define both a single Tool as well as a “ToolSpec” containing a series of functions under the hood.
We describe the base tool abstraction, as well as how you can easily define tools over existing query engines, other tools.
Base Tool Abstraction
The base tool defines a very generic interface. The __call__ function can take in any series of arguments, and return a generic ToolOutput container that can capture any response. A tool also has metadata containing its name, description, and function schema.
@dataclass
class ToolMetadata:
description: str
name: Optional[str] = None
fn_schema: Optional[Type[BaseModel]] = DefaultToolFnSchema
class BaseTool:
@property
@abstractmethod
def metadata(self) -> ToolMetadata:
pass
@abstractmethod
def __call__(self, input: Any) -> ToolOutput:
passFunction Tool
A function tool allows users to easily convert any function into a Tool. It takes in a user-defined function (that can take in any inputs/outputs), and wraps it into a tool interface. It can also “auto-infer” the function schema if it isn’t specified beforehand.
Our ToolSpec classes make use of this FunctionTool abstraction to convert functions defined in the tool spec into a set of agent tools (see below).
Here’s a trivial example of defining a FunctionTool.
from llama_index.tools.function_tool import FunctionTool
def multiply(a: int, b: int) -> int:
"""Multiple two integers and returns the result integer"""
return a * b
multiply_tool = FunctionTool.from_defaults(fn=multiply)QueryEngineTool
Of course, we also provide Tool abstractions to wrap our existing query engines. This provides a seamless transition from working on query engines to working on agents. Our query engines can be thought of “constrained” agents meant for the read/write setting and centered around retrieval purposes. These query engines can be used in an overall agent setting.
from llama_index.tools import QueryEngineTool
query_engine_tools = [
QueryEngineTool(
query_engine=query_engine,
metadata=ToolMetadata(
name='<tool_name>',
description="Queries over X data source."
)
),
...
]Tool Specs
A tool spec is a Python class that represents a full API specification that an agent can interact with, and a tool spec can be converted into a list of tools that an agent can be initialized with.
This class allows users to define entire services, not just single tools that perform individual tasks. Each tool spec may contain read/write endpoints that allow an agent to interact with a service in meaningful ways. For instance, a Slack tool spec could allow the user to both read existing messages and channels (load_data, fetch_channels) as well as write messages (send_message). It would be roughly defined as the following:
class SlackToolSpec(BaseToolSpec):
"""Slack tool spec."""
spec_functions = ["load_data", "send_message", "fetch_channels"]
def load_data(
self,
channel_ids: List[str],
reverse_chronological: bool = True,
) -> List[Document]:
"""Load data from the input directory."""
...
def send_message(
self,
channel_id: str,
message: str,
) -> None:
"""Send a message to a channel given the channel ID."""
...
def fetch_channels(
self,
) -> List[str]:
"""Fetch a list of relevant channels."""
...If a tool spec is initialized, it can be converted into a list of tools that can be fed into an agent with to_tool_list. For instance,
tool_spec = SlackToolSpec()
# initialize openai agent
agent = OpenAIAgent.from_tools(tool_spec.to_tool_list(), llm=llm, verbose=True)Defining a tool spec is not that different than defining a Python class. Each function becomes converted into a tool, and by default the docstring for each function gets used as the tool description (though you can customize names/description in to_tool_list(func_to_metadata_mapping=...).
We also made the intentional choice that the input arguments and return types can be anything. The primary reason is to preserve the generality of the tool interface for subsequent iterations of agents. Even if current iterations of agents expect tool outputs to be in string format, that may change in the future, and we didn’t want to arbitrarily restrict the types of tool interface.
LlamaHub Tool Repository
A huge component of our launch is a brand-new addition to LlamaHub: a Tool Repository. The Tool Repository consists of 15+ Tool Specs that an agent can use. These tool specs represent an initial curated list of services that an agent can interact with and enrich its capability to perform different actions.
Among others, they include the following specs:
- Gmail Spec
- Zapier Spec
- Google Calendar Spec
- OpenAPI Spec
- SQL + Vector Database Spec
We also provide a list of utility tools that help to abstract away pain points when designing agents to interact with different API services that return large amounts of data.
For instance, our Gmail Tool Spec allows an agent to search existing emails, create drafts, update drafts, and send emails. Our Zapier Spec allows an agent to perform any natural language query to Zapier through their Natural Language Actions interface.
Best of all, you don’t need to spend a lot of time figuring out how to use these tools — we have 10+ notebooks showing how you can build agents for each service, or even build agents that use a combination of services (e.g. Gmail, Google Calendar, and Search).
Example Walkthrough
Let’s take a look at a few examples! We initialize an OpenAIAgent with the Gmail Spec. As mentioned above, the spec consists of tools to search emails, create/update drafts, and send emails.
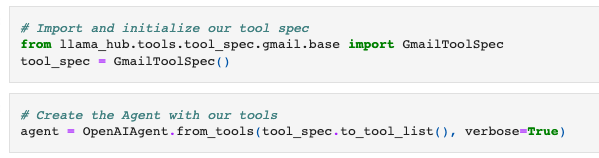
Now let’s give the agent a sequence of commands so that it can create an email draft, make a few edits to it, and then send it off.
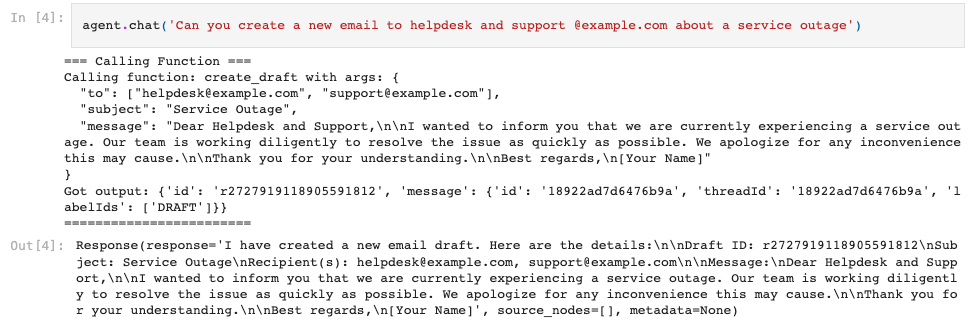
First, let’s create an initial email draft. Note that the agent chooses the create_draft tool, which takes in the “to”, “subject”, and “message” parameters. The agent is able to infer the parameters simultaneously while picking the tool.
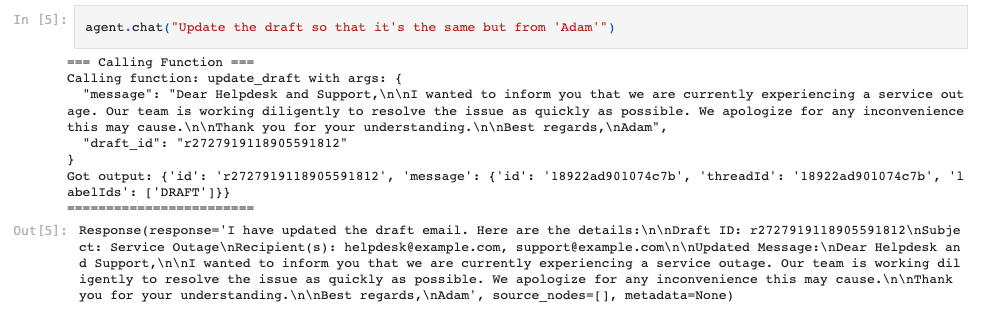
Next, let’s update the draft with a slight modification:
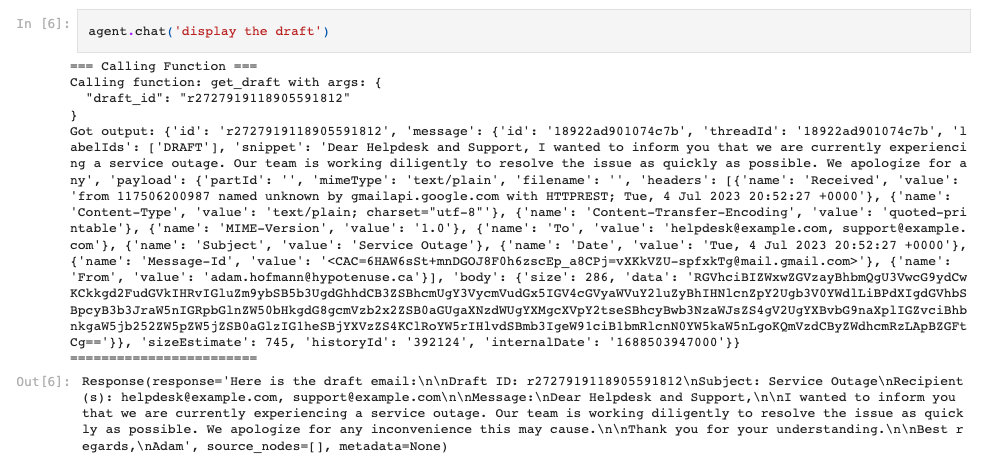
Next, let’s show the current state of the draft.
Finally, let’s send the email!

This is a good start, but this is just the beginning. We are actively working on contributing more tools to this repository, and we’re also opening this up to community contributions. If you’re interested in contributing a Tool to LlamaHub, please feel free to open a PR in this repo.
Utility Tools
Oftentimes, directly querying an API can return a massive volume of data, which on its own may overflow the context window of the LLM (or at the very least unnecessarily increase the number of tokens that you are using).
To tackle this, we’ve provided an initial set of “utility tools” in the core LlamaIndex repo — utility tools are not conceptually tied to a given service (e.g. Gmail, Notion), but rather can augment the capabilities of existing Tools. In this particular case, utility tools help to abstract away common patterns of needing to cache/index and query data that’s returned from any API request.
Let’s walk through our two main utility tools below.
OnDemandLoaderTool
This tool turns any existing LlamaIndex data loader ( BaseReader class) into a tool that an agent can use. The tool can be called with all the parameters needed to trigger load_data from the data loader, along with a natural language query string. During execution, we first load data from the data loader, index it (for instance with a vector store), and then query it “on-demand”. All three of these steps happen in a single tool call.
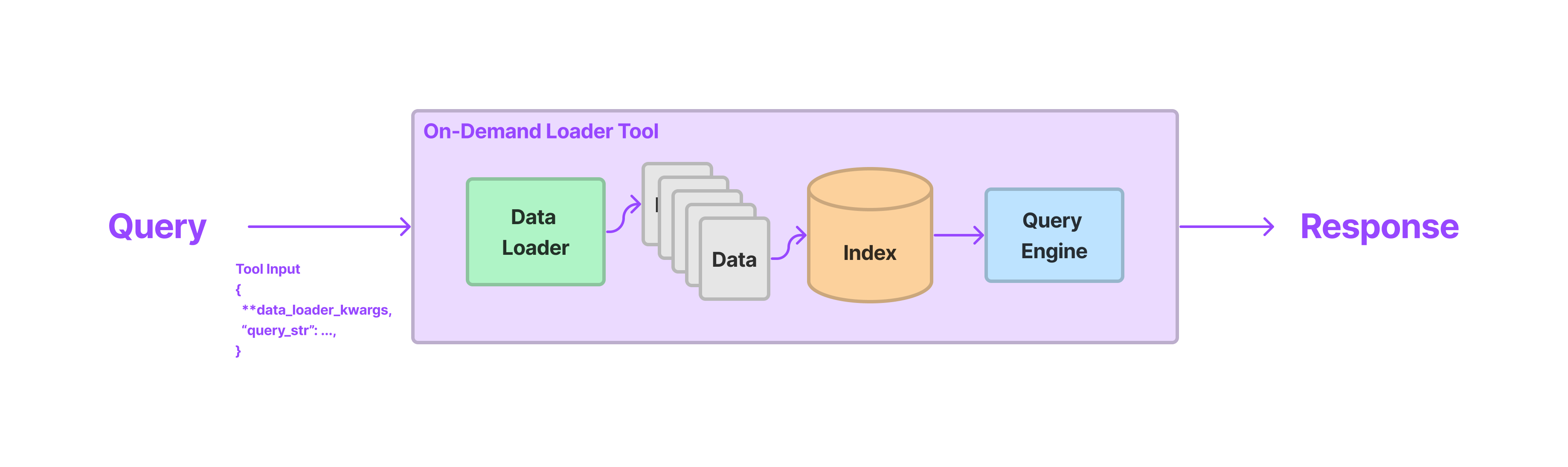
Oftentimes this can be preferable to figuring out how to load and index API data yourself. While this may allow for data reusability, oftentimes users just need an ad-hoc index to abstract away prompt window limitations for any API call.
A usage example is given below:
from llama_hub.wikipedia.base import WikipediaReader
from llama_index.tools.on_demand_loader_tool import OnDemandLoaderTool
tool = OnDemandLoaderTool.from_defaults(
reader,
name="Wikipedia Tool",
description="A tool for loading data and querying articles from Wikipedia"
)LoadAndSearchToolSpec
The LoadAndSearchToolSpec takes in any existing Tool as input. As a tool spec, it implements to_tool_list , and when that function is called, two tools are returned: a load tool and then a search tool.
The load Tool execution would call the underlying Tool, and the index the output (by default with a vector index). The search Tool execution would take in a query string as input and call the underlying index.
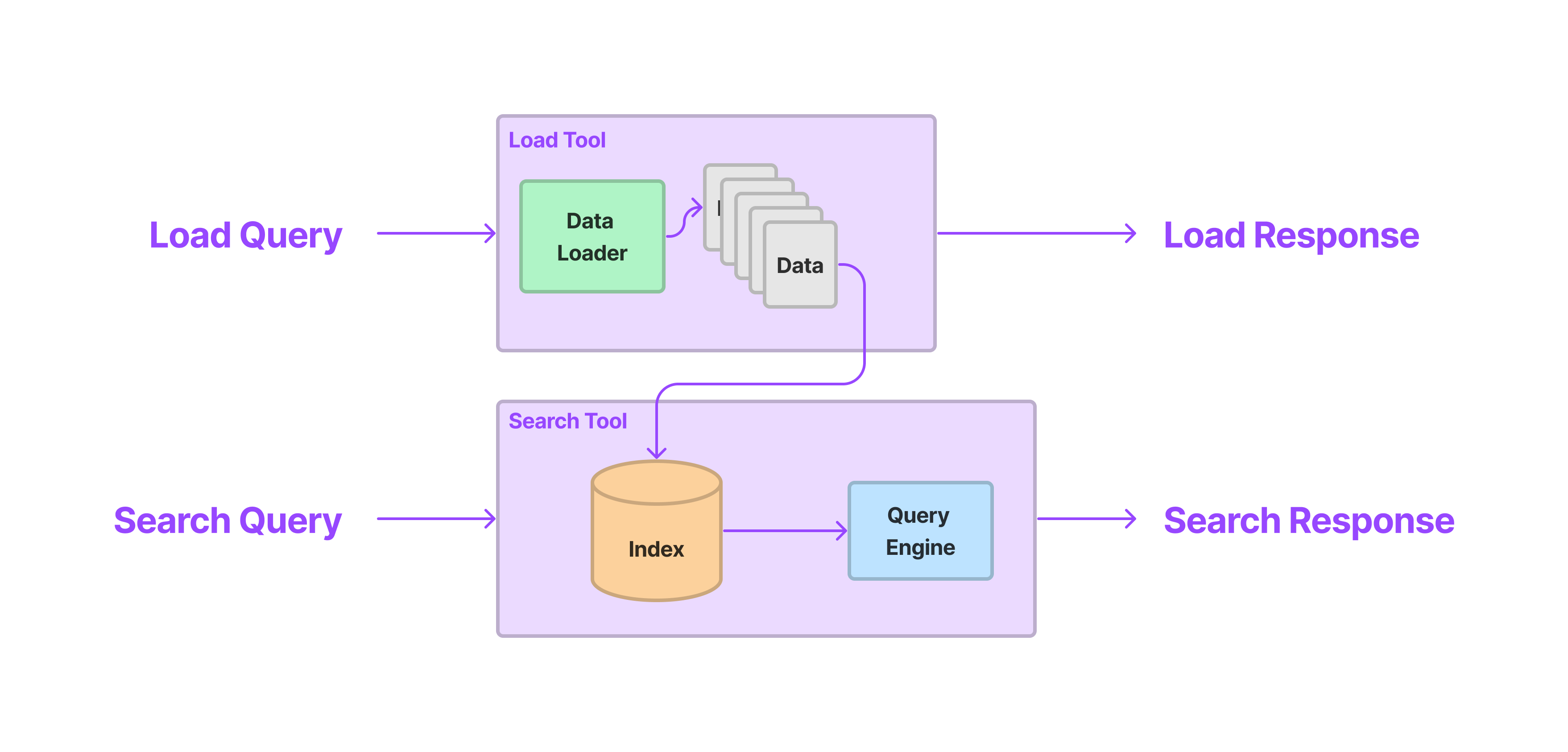
This is helpful for any API endpoint that will by default return large volumes of data — for instance our WikipediaToolSpec will by default return entire Wikipedia pages, which will easily overflow most LLM context windows.
Example usage is shown below:
from llama_hub.tools.wikipedia.base import WikipediaToolSpec
from llama_index.tools.tool_spec.load_and_search.base import LoadAndSearchToolSpec
wiki_spec = WikipediaToolSpec()
# Get the search wikipedia tool
tool = wiki_spec.to_tool_list()[1]
# Create the Agent with load/search tools
agent = OpenAIAgent.from_tools(
LoadAndSearchToolSpec.from_defaults(
tool
).to_tool_list(), verbose=True
)This is the output when we run an input prompt
agent.chat('what is the capital of poland')Output:
=== Calling Function ===
Calling function: search_data with args: {
"query": "capital of Poland"
}
Got output: Content loaded! You can now search the information using read_search_data
========================
=== Calling Function ===
Calling function: read_search_data with args: {
"query": "What is the capital of Poland?"
}
Got output:
The capital of Poland is Warsaw.
========================
AgentChatResponse(response='The capital of Poland is Warsaw.', sources=[])Note that the agent figures out that it first needs to first call the “load” tool (denoted by the original name of the tool, “search_data”). This load tool will load the Wikipedia page and index under the hood. The output just mentions that the “content is loaded, and tells the agent that the next step is to use read_search_data. The agent then reasons that it needs to call the read_search_data tool, which will query the index for the right answer.
FAQ
Should I use Data Agents for search and retrieval, or continue to use Query Engines?
Short answer: both are possible. Query engines give you the ability to define your own workflows over your data, in both a constrained reasoning fashion as well as unconstrained fashion. For instance, you may want to define a specific workflow over text-to-SQL with our NLStructStoreQueryEngine (constrained), or a router module to decide between semantic search or summarization (less constrained), or use our SubQuestionQueryEngine to decompose a question among sub-documents (even less constrained).
By default, agent loops are unconstrained, and can theoretically reason over any set of tools that you give them. This means that you can get out-of-the-box advanced search/retrieval capabilities — for instance, in our OpenAI cookbook we show that you can get joint text-to-SQL capabilities by simply providing a SQL query engine and Vector Store Query engine as tools. But on the other hand, agents built in this fashion can be quite unreliable (see our blog post for more insights). If you are using agents for search/retrieval, be mindful of the 1) LLM you pick, and the 2) set of tools you pick too.
How are LlamaIndex data agents different than existing agent frameworks (LangChain, Hugging Face, etc.)?
Most of these core concepts are not new. Our overall design has taken inspiration from popular tools and frameworks for building agents. But in our “data agents” design, we’ve tried our best to answer the following key questions well:
- How do we effectively index/query and retrieve data beforehand?
- How do we effectively index/query and retrieve data on the fly?
- How do we design API interfaces for read/writes that are simultaneously rich (can take in structured inputs), but also easy for agents to understand?
- How do we properly get sources in citations?
Our goal with data agents is to create automated knowledge workers that can reason over and interact with data. Our core toolkit provides the foundations for properly indexing, retrieving, and querying data — these can be easily integrated as tools. We provide some additional tool abstractions to handle the cases where you want to “cache” API outputs on the fly (see above). Finally, we provide principled tool abstractions and design principles so that agents can interface with external services in a structured manner.
Can I use Tools with LangChain agents? You can easily use any of our tools with LangChain agents as well.
tools = tool_spec.to_tool_list()
langchain_tools = [t.to_langchain_tool() for t in tools]See our tools usage guide for more details!
Conclusion
In summary, today we launched two key items: Data Agent components (incl. agent reasoning loop and tool abstractions) and the LlamaHub Tool repository.
Resources
We’ve written a comprehensive section in the docs — take a look here: https://gpt-index.readthedocs.io/en/latest/core_modules/agent_modules/agents/root.html
Take a look at our LlamaHub Tools section: https://llamahub.ai/
Notebook Tutorials for LlamaHub Tools: https://github.com/emptycrown/llama-hub/tree/main/llama_hub/tools/notebooks
If you have questions, please hop on our Discord: https://discord.gg/dGcwcsnxhU