
Introduction
E-commerce platforms, such as Amazon and Walmart, are teeming with products that attract a multitude of reviews every single day. These reviews are crucial touchpoints that reflect consumer sentiments about products. But how can businesses sift through vast databases to derive meaningful insights from these reviews?
The answer lies in combining SQL with RAG (Retrieval Augmented Generation) through LlamaIndex.
Let’s deep dive into this!
Sample Dataset of Product Reviews
For the purpose of this demonstration, we’ve generated a sample dataset using GPT-4 that comprises reviews for three products: iPhone13, SamsungTV, and an Ergonomic Chair. Here’s a sneak peek:
- iPhone13: “Amazing battery life and camera quality. Best iPhone yet.”
- SamsungTV: “Impressive picture clarity and vibrant colors. A top-notch TV.”
- Ergonomic Chair: “Feels really comfortable even after long hours.”
Here is a sample dataset.
rows = [
# iPhone13 Reviews
{"category": "Phone", "product_name": "Iphone13", "review": "The iPhone13 is a stellar leap forward. From its sleek design to the crystal-clear display, it screams luxury and functionality. Coupled with the enhanced battery life and an A15 chip, it's clear Apple has once again raised the bar in the smartphone industry."},
{"category": "Phone", "product_name": "Iphone13", "review": "This model brings the brilliance of the ProMotion display, changing the dynamics of screen interaction. The rich colors, smooth transitions, and lag-free experience make daily tasks and gaming absolutely delightful."},
{"category": "Phone", "product_name": "Iphone13", "review": "The 5G capabilities are the true game-changer. Streaming, downloading, or even regular browsing feels like a breeze. It's remarkable how seamless the integration feels, and it's obvious that Apple has invested a lot in refining the experience."},
# SamsungTV Reviews
{"category": "TV", "product_name": "SamsungTV", "review": "Samsung's display technology has always been at the forefront, but with this TV, they've outdone themselves. Every visual is crisp, the colors are vibrant, and the depth of the blacks is simply mesmerizing. The smart features only add to the luxurious viewing experience."},
{"category": "TV", "product_name": "SamsungTV", "review": "This isn't just a TV; it's a centerpiece for the living room. The ultra-slim bezels and the sleek design make it a visual treat even when it's turned off. And when it's on, the 4K resolution delivers a cinematic experience right at home."},
{"category": "TV", "product_name": "SamsungTV", "review": "The sound quality, often an oversight in many TVs, matches the visual prowess. It creates an enveloping atmosphere that's hard to get without an external sound system. Combined with its user-friendly interface, it's the TV I've always dreamt of."},
# Ergonomic Chair Reviews
{"category": "Furniture", "product_name": "Ergonomic Chair", "review": "Shifting to this ergonomic chair was a decision I wish I'd made earlier. Not only does it look sophisticated in its design, but the level of comfort is unparalleled. Long hours at the desk now feel less daunting, and my back is definitely grateful."},
{"category": "Furniture", "product_name": "Ergonomic Chair", "review": "The meticulous craftsmanship of this chair is evident. Every component, from the armrests to the wheels, feels premium. The adjustability features mean I can tailor it to my needs, ensuring optimal posture and comfort throughout the day."},
{"category": "Furniture", "product_name": "Ergonomic Chair", "review": "I was initially drawn to its aesthetic appeal, but the functional benefits have been profound. The breathable material ensures no discomfort even after prolonged use, and the robust build gives me confidence that it's a chair built to last."},
]Setting up an In-Memory Database
To process our data, we’re using an in-memory SQLite database. SQLAlchemy provides an efficient way to model, create, and interact with this database. Here’s how our product_reviews table structure looks:
id(Integer, Primary Key)category(String)product_name(String)review(String, Not Null)
Once we’ve defined our table structure, we populate it with our sample dataset.
engine = create_engine("sqlite:///:memory:")
metadata_obj = MetaData()
# create product reviews SQL table
table_name = "product_reviews"
city_stats_table = Table(
table_name,
metadata_obj,
Column("id", Integer(), primary_key=True),
Column("category", String(16), primary_key=True),
Column("product_name", Integer),
Column("review", String(16), nullable=False)
)
metadata_obj.create_all(engine)
sql_database = SQLDatabase(engine, include_tables=["product_reviews"])
for row in rows:
stmt = insert(city_stats_table).values(**row)
with engine.connect() as connection:
cursor = connection.execute(stmt)
connection.commit()Analysing Product Reviews — Text2SQL + RAG
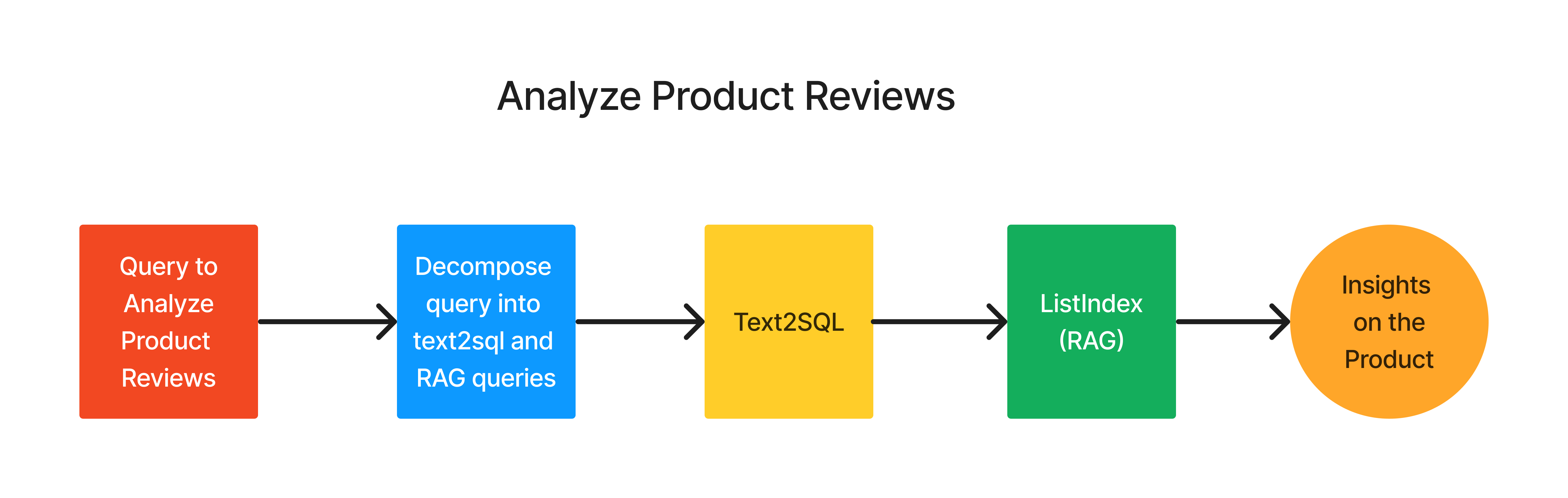
Deriving insights from data often requires intricate questioning.
SQL + RAG in LlamaIndex simplifies this by breaking it into a three-step process:
- Decomposition of the Question:
- Primary Query Formation: Frame the main question in natural language to extract preliminary data from the SQL table.
- Secondary Query Formation: Construct an auxiliary question to refine or interpret the results of the primary query.
2. Data Retrieval: Run the primary query using the Text2SQL LlamaIndex module to obtain the initial set of results.
3. Final Answer Generation: Use List Index to further refine the results based on the secondary question, leading to the conclusive answer.
Let’s start doing it step by step.
Decomposing User Query into Two Phases
When working with a relational database, it’s often helpful to break down user queries into more manageable parts. This makes it easier to retrieve accurate data from our database and subsequently process or interpret this data to meet the user’s needs. We’ve designed an approach to decompose queries into two distinct questions by giving an example to gpt-3.5-turbo model to generate two distinct questions.
Let’s apply this to the query “Get the summary of reviews of Iphone13” and our system would generate:
- Database Query: “Retrieve reviews related to iPhone13 from the table.”
- Interpretation Query: “Summarize the retrieved reviews.”
This approach ensures that we cater to both the data retrieval and data interpretation needs, resulting in more accurate and tailored responses to user queries.
def generate_questions(user_query: str) -> List[str]:
system_message = '''
You are given with Postgres table with the following columns.
city_name, population, country, reviews.
Your task is to decompose the given question into the following two questions.
1. Question in natural language that needs to be asked to retrieve results from the table.
2. Question that needs to be asked on the top of the result from the first question to provide the final answer.
Example:
Input:
How is the culture of countries whose population is more than 5000000
Output:
1. Get the reviews of countries whose population is more than 5000000
2. Provide the culture of countries
'''
messages = [
ChatMessage(role="system", content=system_message),
ChatMessage(role="user", content=user_query),
]
generated_questions = llm.chat(messages).message.content.split('\n')
return generated_questions
user_query = "Get the summary of reviews of Iphone13"
text_to_sql_query, rag_query = generate_questions(user_query)Data Retrieval — Executing the Primary Query
When we decompose a user’s question into its constituent parts, the first step is to convert the “Database Query in Natural Language” into an actual SQL query that can be run against our database. In this section, we’ll use the LlamaIndex’s NLSQLTableQueryEngine to handle the conversion and execution of this SQL query.
Setting up the NLSQLTableQueryEngine:
The NLSQLTableQueryEngine is a powerful tool that takes natural language queries and converts them into SQL queries. We initiate this by providing the necessary details:
sql_database: This represents our SQL database connection details.tables: We specify which table(s) our query will be run against. In this scenario, we're targeting theproduct_reviewstable.synthesize_response: When set toFalse, this ensures we receive raw SQL responses without additional synthesis.service_context: This is an optional parameter, which could be used to provide service-specific settings or plugins.
sql_query_engine = NLSQLTableQueryEngine(
sql_database=sql_database,
tables=["product_reviews"],
synthesize_response=False,
service_context=service_context
)Executing the natural language Query:
After setting up the engine, the next step is executing our natural language query against it. The engine’s query() method is used for this purpose.
sql_response = sql_query_engine.query(text_to_sql_query)Processing the SQL Response:
The result of our SQL query is usually a list of rows (with each row represented as a list of reviews). To make it more readable and usable for the third step of processing summarizing reviews, we convert this result into a single string.
sql_response_list = ast.literal_eval(sql_response.response)
text = [' '.join(t) for t in sql_response_list]
text = ' '.join(text)You can check the generated SQL query in sql_response.metadata["sql_query"].
By following this process, we’re able to seamlessly integrate natural language processing with SQL query execution. Let’s go with the last step in this process for getting a summary of the reviews.
Refining and Interpreting the reviews with ListIndex:
After obtaining the primary set of results from the SQL query, there are often situations where further refinement or interpretation is required. This is where ListIndex from LlamaIndex plays a crucial role. It allows us to execute the secondary question on our obtained text data to get a refined answer.
listindex = ListIndex([Document(text=text)])
list_query_engine = listindex.as_query_engine()
response = list_query_engine.query(rag_query)
print(response.response)Now let’s wrap everything under a function and try out a few interesting examples:
"""Function to perform SQL+RAG"""
def sql_rag(user_query: str) -> str:
text_to_sql_query, rag_query = generate_questions(user_query)
sql_response = sql_query_engine.query(text_to_sql_query)
sql_response_list = ast.literal_eval(sql_response.response)
text = [' '.join(t) for t in sql_response_list]
text = ' '.join(text)
listindex = ListIndex([Document(text=text)])
list_query_engine = listindex.as_query_engine()
summary = list_query_engine.query(rag_query)
return summary.responseExamples:
sql_rag("How is the sentiment of SamsungTV product?")The sentiment of the reviews for the Samsung TV product is generally positive. Users express satisfaction with the picture clarity, vibrant colors, and stunning picture quality. They appreciate the smart features, user-friendly interface, and easy connectivity options. The sleek design and wall-mounting capability are also praised. The ambient mode, gaming mode, and HDR content are mentioned as standout features. Users find the remote control with voice command convenient and appreciate the regular software updates. However, some users mention that the sound quality could be better and suggest using an external audio system. Overall, the reviews indicate that the Samsung TV is considered a solid investment for quality viewing.
sql_rag("Are people happy with Ergonomic Chair?")The overall satisfaction of people with the Ergonomic Chair is high.
You can play around with the approach and dataset in the Google Colab Notebook — here.
Conclusion
In the era of e-commerce, where user reviews dictate the success or failure of products, the ability to rapidly analyze and interpret vast swaths of textual data is paramount. LlamaIndex, through its ingenious integration of SQL and RAG, offers businesses a powerful tool to glean actionable insights from such datasets. By seamlessly blending structured SQL queries with the abstraction of natural language processing, we’ve showcased a streamlined approach to transform vague user queries into precise, informative answers.
With this approach, businesses can now efficiently sift through mountains of reviews, extract the essence of user sentiments, and make informed decisions. Whether it’s about gauging the overall sentiment for a product, understanding specific feature feedback, or even tracking the evolution of reviews over time, the Text2SQL+RAG methodology in LlamaIndex is the harbinger of a new age of data analytics.


