


(co-authored by Jerry Liu, Haotian Zhang, Logan Markewich, and Laurie Voss @ LlamaIndex)
Today is Google’s public release of its latest AI model, Gemini. We’re excited to be a day 1 launch partner for Gemini, with support immediately available in LlamaIndex today!
As of 0.9.15, LlamaIndex offers full support for all currently released and upcoming Gemini models (Gemini Pro, Gemini Ultra). We support both a “text-only” Gemini variant with a text-in/text-out format as well as a multimodal variant that takes in both text and images as input, and outputs text. We’ve made some fundamental multi-modal abstraction changes to support the Gemini multi-modal interface, which allows users to input multiple images along with text. Our Gemini integrations are also feature-complete: they support (non-streaming, streaming), (sync, async), and (text completion, chat message) formats — 8 combinations in total.
In addition, we also support the brand-new Semantic Retriever API, which bundles storage, embedding models, retrieval, and LLM in a RAG pipeline. We show you how it can be used on its own, or decomposed+bundled with LlamaIndex components to create advanced RAG pipelines.
Huge shoutout to the Google Labs and Semantic Retriever teams for helping us get setup with early access.
- Google Labs: Mark McDonald, Josh Gordon, Arthur Soroken
- Semantic Retriever: Lawrence Tsang, Cher Hu
The below sections contain a detailed walkthrough of both our brand-new Gemini and Semantic Retriever abstractions in LlamaIndex. If you don’t want to read that now, make sure you bookmark our detailed notebook guides below!
Gemini Release and Support
There’s been a ton of press around Gemini, which boasts impressive performance at a variety of benchmarks. The Ultra variants (which are not yet publicly available) outperform GPT-4 on benchmarks from MMLU to Big-Bench Hard to math and coding tasks. Their multimodal demos demonstrate joint image/text understanding from domains like scientific paper understanding to literature review.
Let’s walk through examples of using Gemini in LlamaIndex. We walk through both the text model (from llama_index.llms import Gemini) as well as the multi-modal model (from llama_index.multi_modal_llms.gemini import GeminiMultiModal)
Text Model
We start with the text model. In the code snippet below, we show a bunch of different configurations, from completion to chat to streaming to async.
from llama_index.llms import Gemini
# completion
resp = Gemini().complete("Write a poem about a magic backpack")
# chat
messages = [
ChatMessage(role="user", content="Hello friend!"),
ChatMessage(role="assistant", content="Yarr what is shakin' matey?"),
ChatMessage(
role="user", content="Help me decide what to have for dinner."
),
]
resp = Gemini().chat(messages)
# streaming (completion)
llm = Gemini()
resp = llm.stream_complete(
"The story of Sourcrust, the bread creature, is really interesting. It all started when..."
)
# streaming (chat)
llm = Gemini()
messages = [
ChatMessage(role="user", content="Hello friend!"),
ChatMessage(role="assistant", content="Yarr what is shakin' matey?"),
ChatMessage(
role="user", content="Help me decide what to have for dinner."
),
]
resp = llm.stream_chat(messages)
# async completion
resp = await llm.acomplete("Llamas are famous for ")
print(resp)
# async streaming (completion)
resp = await llm.astream_complete("Llamas are famous for ")
async for chunk in resp:
print(chunk.text, end="")The Gemini class of course has parameters that can be set. This includes model_name, temperature, max_tokens, and generate_kwargs.
As an example, you can do:
llm = Gemini(model="models/gemini-ultra")Multi-modal Model
In this notebook, we test out the gemini-pro-vision variant that features multi-modal inputs. It contains the following features:
- supports both
completeandchatcapabilities - supports streaming and async
- Supports feeding in multiple images in addition to text in the completion endpoint
- Future work: multi-turn chat interleaving text and images is supported within our abstraction, but is not yet enabled for gemini-pro-vision.
Let’s walk through a concrete example. Let’s say we are given a picture of the following scene:

We can then initialize our Gemini Vision model, and ask it a question: “Identify the city where this photo was taken”:
from llama_index.multi_modal_llms.gemini import GeminiMultiModal
from llama_index.multi_modal_llms.generic_utils import (
load_image_urls,
)
image_urls = [
"<https://storage.googleapis.com/generativeai-downloads/data/scene.jpg>",
# Add yours here!
]
image_documents = load_image_urls(image_urls)
gemini_pro = GeminiMultiModal(model="models/gemini-pro")
complete_response = gemini_pro.complete(
prompt="Identify the city where this photo was taken.",
image_documents=image_documents,
)Our response is the following:
New York CityWe can insert multiple images too. Here’s an example with an image of Messi and the Colosseum.
image_urls = [
"<https://www.sportsnet.ca/wp-content/uploads/2023/11/CP1688996471-1040x572.jpg>",
"<https://res.cloudinary.com/hello-tickets/image/upload/c_limit,f_auto,q_auto,w_1920/v1640835927/o3pfl41q7m5bj8jardk0.jpg>",
]
image_documents_1 = load_image_urls(image_urls)
response_multi = gemini_pro.complete(
prompt="is there any relationship between those images?",
image_documents=image_documents_1,
)
print(response_multi)Multi-Modal Use Cases (Structured Outputs, RAG)
We’ve created extensive resources about different multi-modal use cases, from structured output extraction to RAG.
Thanks to Haotian Zhang, we have examples for both these use cases with Gemini. Please see our extensive notebook guides for more details. In the meantime here’s the final results!
Structured Data Extraction with Gemini Pro Vision
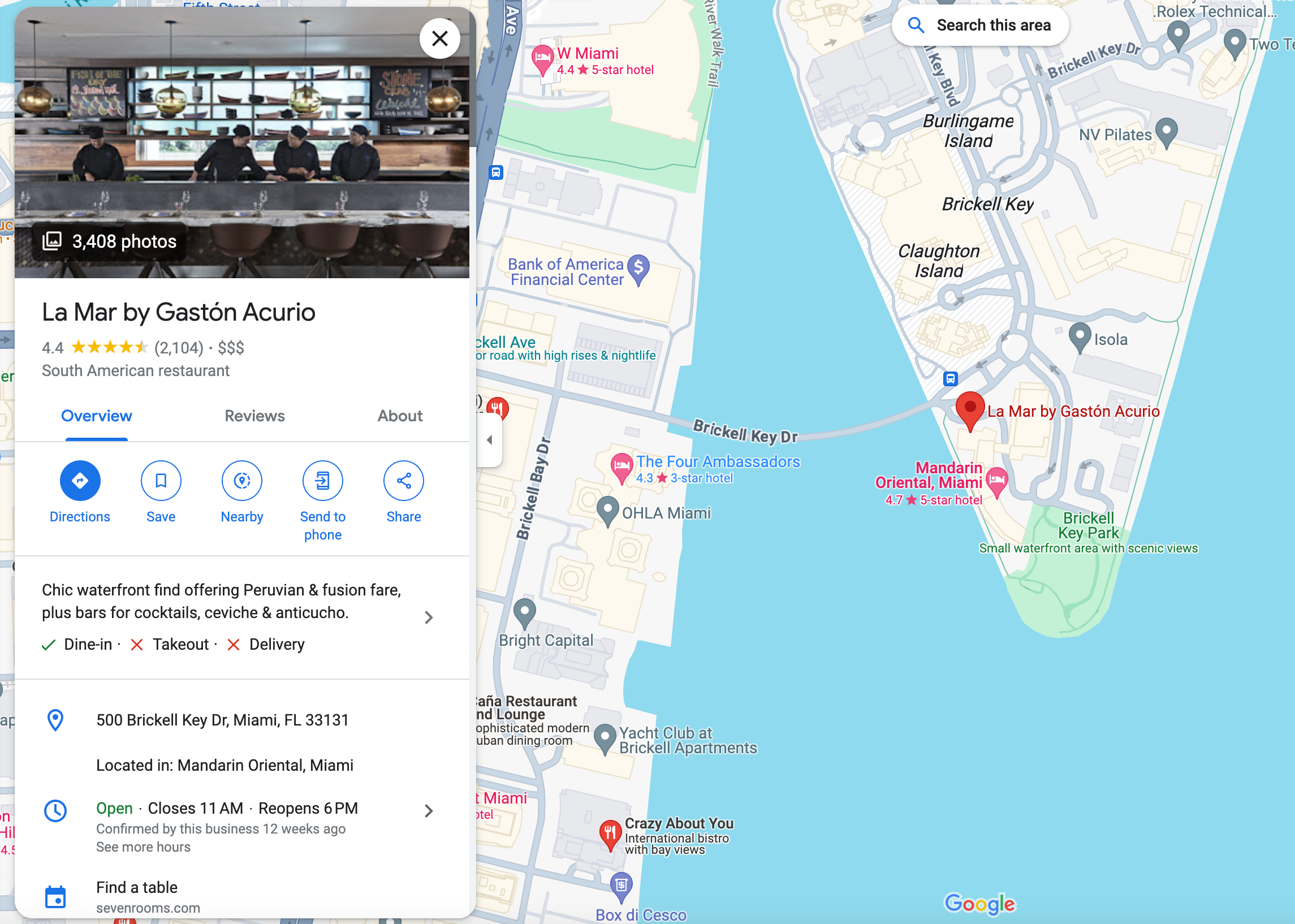
Output:
('restaurant', 'La Mar by Gaston Acurio')
('food', 'South American')
('location', '500 Brickell Key Dr, Miami, FL 33131')
('category', 'Restaurant')
('hours', 'Open ⋅ Closes 11 PM')
('price', 4.0)
('rating', 4)
('review', '4.4 (2,104)')
('description', 'Chic waterfront find offering Peruvian & fusion fare, plus bars for cocktails, ceviche & anticucho.')
('nearby_tourist_places', 'Brickell Key Park')Multi-Modal RAG
We run our structured output extractor on multiple restaurant images, index these nodes, and then ask a question “Recommend a Orlando restaurant for me and its nearby tourist places”
I recommend Mythos Restaurant in Orlando. It is an American restaurant located at 6000 Universal Blvd, Orlando, FL 32819, United States. It has a rating of 4 and a review score of 4.3 based on 2,115 reviews. The restaurant offers a mythic underwater-themed dining experience with a view of Universal Studios' Inland Sea. It is located near popular tourist places such as Universal's Islands of Adventure, Skull Island: Reign of Kong, The Wizarding World of Harry Potter, Jurassic Park River Adventure, Hollywood Rip Ride Rockit, and Universal Studios Florida.Semantic Retriever
The Generative Language Semantic Retriever offers specialized embedding models for high-quality retrieval, and a tuned LLM for producing grounded-output with safety settings.
It can be used out of the box (with our GoogleIndex) or decomposed into different components (GoogleVectorStore and GoogleTextSynthesizer) and combined with LlamaIndex abstractions!
Our full semantic retriever notebook guide is here.
Out of the Box Configuration
You can use it out of the box with very few lines of setup. Simply define the index, insert nodes, and then get a query engine:
from llama_index.indices.managed.google.generativeai import GoogleIndex
index = GoogleIndex.from_corpus(corpus_id="<corpus_id>")
index.insert_documents(nodes)
query_engine = index.as_query_engine(...)
response = query_engine.query("<query>")A cool feature here is that Google’s query engine supports different answering styles as well as safety settings.
Answering Styles:
- ABSTRACTIVE (succinct but abstract)
- EXTRACTIVE (brief and extractive)
- VERBOSE (extra details)
Safety Settings
You can specify safety settings in the query engine, which let you define guardrails on whether the answer is explicit in different settings. See the generative-ai-python library for more information.
Decomposing into Different Components
The GoogleIndex is built upon two components: a vector store (GoogleVectorStore) and the response synthesizer (GoogleTextSynthesizer). You can use these as modular components in conjunction with LlamaIndex abstractions to create advanced RAG.
The notebook guide highlights three advanced RAG use cases:
- Google Retriever + Reranking: Use the Semantic Retriever to return relevant results, but then use our reranking modules to process/filter results before feeding it to response synthesis.
- Multi-Query + Google Retriever: Use our multi-query capabilities, like our
MultiStepQueryEngineto break a complex question into multiple steps, and execute each step against the semantic retriever. - HyDE + Google Retriever: HyDE is a popular query transformation technique that hallucinates an answer from a query, and uses the hallucinated answer for embedding lookup. Use that as a step before the retrieval step from the Semantic Retriever.
Conclusion
There’s a lot in here, and even then the blog post doesn’t even cover half of what we’ve released today.
Please please make sure to check out our extensive notebook guides! Linking the resources again below:
Again, huge shoutout to the Google teams and Haotian Zhang, Logan Markewich from the LlamaIndex team for putting together everything for this release.


