Summary
This blog post outlines some of the core abstractions we have created in LlamaIndex around LLM-powered retrieval and reranking, which helps to create enhancements to document retrieval beyond naive top-k embedding-based lookup.
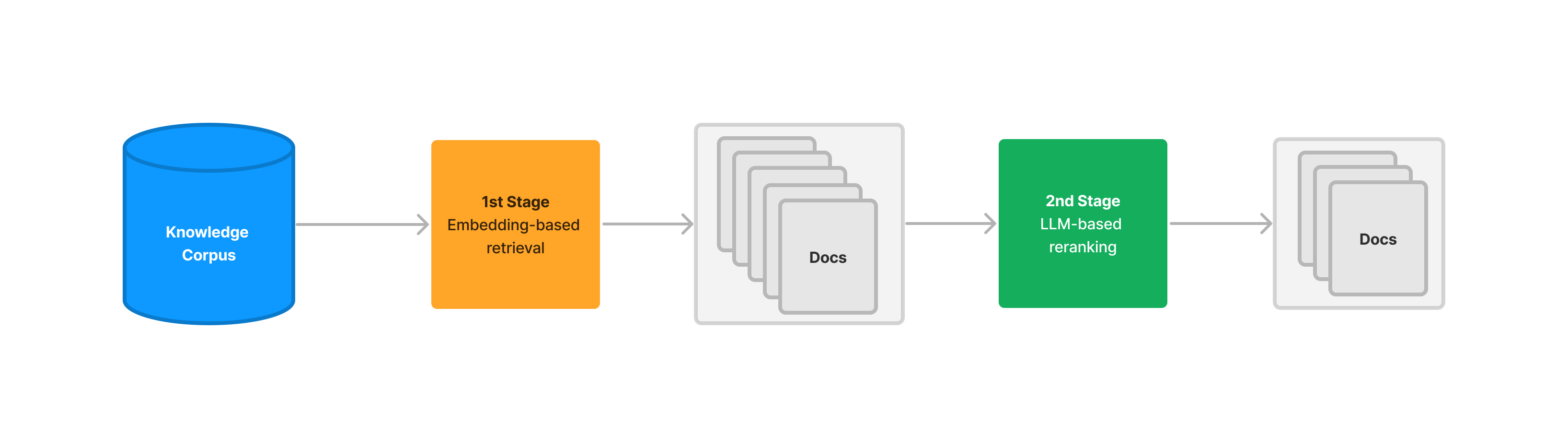
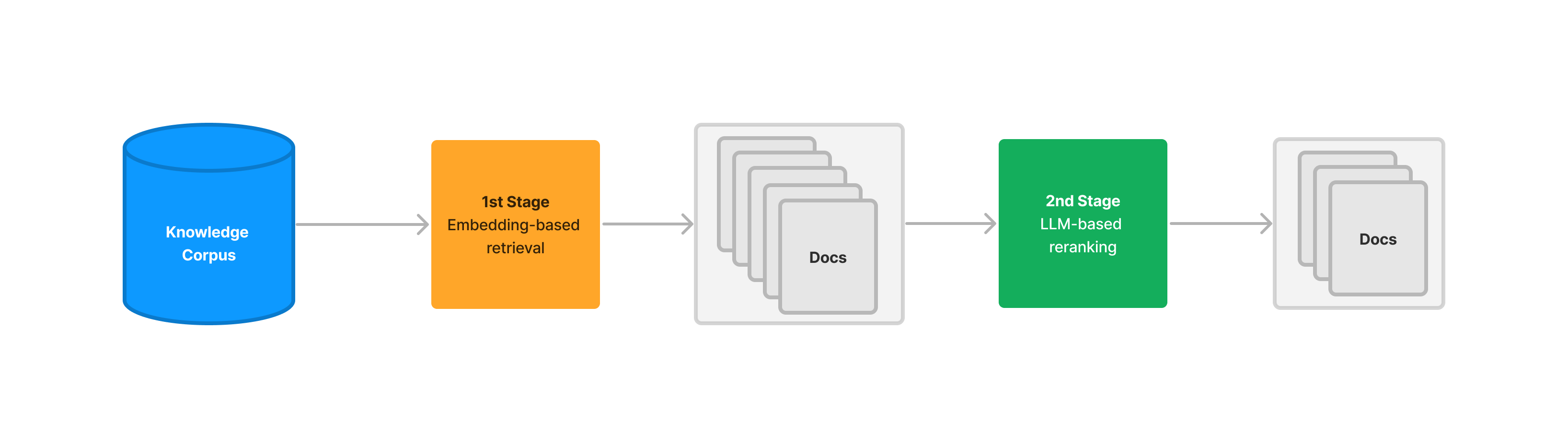
LLM-powered retrieval can return more relevant documents than embedding-based retrieval, with the tradeoff being much higher latency and cost. We show how using embedding-based retrieval as a first-stage pass, and second-stage retrieval as a reranking step can help provide a happy medium. We provide results over the Great Gatsby and the Lyft SEC 10-k.
Introduction and Background
There has been a wave of “Build a chatbot over your data” applications in the past few months, made possible with frameworks like LlamaIndex and LangChain. A lot of these applications use a standard stack for retrieval augmented generation (RAG):
- Use a vector store to store unstructured documents (knowledge corpus)
- Given a query, use a retrieval model to retrieve relevant documents from the corpus, and a synthesis model to generate a response.
- The retrieval model fetches the top-k documents by embedding similarity to the query.
In this stack, the retrieval model is not a novel idea; the concept of top-k embedding-based semantic search has been around for at least a decade, and doesn’t involve the LLM at all.
There are a lot of benefits to embedding-based retrieval:
- It’s very fast to compute dot products. Doesn’t require any model calls during query-time.
- Even if not perfect, embeddings can encode the semantics of the document and query reasonably well. There’s a class of queries where embedding-based retrieval returns very relevant results.
Yet for a variety of reasons, embedding-based retrieval can be imprecise and return irrelevant context to the query, which in turn degrades the quality of the overall RAG system, regardless of the quality of the LLM.
This is also not a new problem: one approach to resolve this in existing IR and recommendation systems is to create a two stage process. The first stage uses embedding-based retrieval with a high top-k value to maximize recall while accepting a lower precision. Then the second stage uses a slightly more computationally expensive process that is higher precision and lower recall (for instance with BM25) to “rerank” the existing retrieved candidates.
Covering the downsides of embedding-based retrieval is worth an entire series of blog posts. This blog post is an initial exploration of an alternative retrieval method and how it can (potentially) augment embedding-based retrieval methods.
LLM Retrieval and Reranking
Over the past week, we’ve developed a variety of initial abstractions around the concept of “LLM-based” retrieval and reranking. At a high-level, this approach uses the LLM to decide which document(s) / text chunk(s) are relevant to the given query. The input prompt would consist of a set of candidate documents, and the LLM is tasked with selecting the relevant set of documents as well as scoring their relevance with an internal metric.
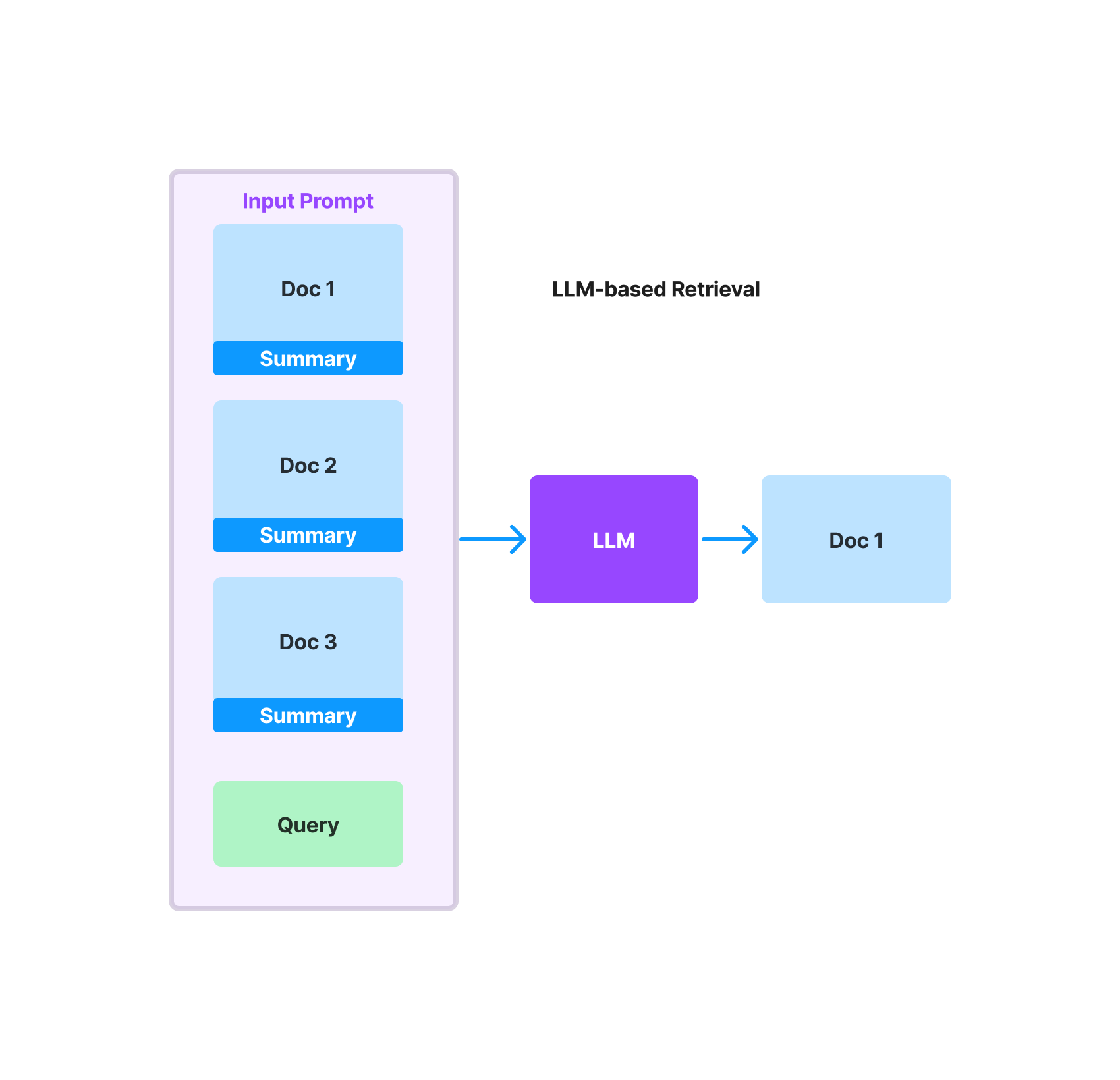
An example prompt would look like the following:
A list of documents is shown below. Each document has a number next to it along with a summary of the document. A question is also provided.
Respond with the numbers of the documents you should consult to answer the question, in order of relevance, as well
as the relevance score. The relevance score is a number from 1–10 based on how relevant you think the document is to the question.
Do not include any documents that are not relevant to the question.
Example format:
Document 1:
<summary of document 1>
Document 2:
<summary of document 2>
…
Document 10:
<summary of document 10>
Question: <question>
Answer:
Doc: 9, Relevance: 7
Doc: 3, Relevance: 4
Doc: 7, Relevance: 3
Let's try this now:
{context_str}
Question: {query_str}
Answer:The prompt format implies that the text for each document should be relatively concise. There are two ways of feeding in the text to the prompt corresponding to each document:
- You can directly feed in the raw text corresponding to the document. This works well if the document corresponds to a bite-sized text chunk.
- You can feed in a condensed summary for each document. This would be preferred if the document itself corresponds to a long-piece of text. We do this under the hood with our new document summary index, but you can also choose to do it yourself.
Given a collection of documents, we can then create document “batches” and send each batch into the LLM input prompt. The output of each batch would be the set of relevant documents + relevance scores within that batch. The final retrieval response would aggregate relevant documents from all batches.
You can use our abstractions in two forms: as a standalone retriever module (ListIndexLLMRetriever) or a reranker module (LLMRerank). The remainder of this blog primarily focuses on the reranker module given the speed/cost.
LLM Retriever(ListIndexLLMRetriever)
This module is defined over a list index, which simply stores a set of nodes as a flat list. You can build the list index over a set of documents and then use the LLM retriever to retrieve the relevant documents from the index.
from llama_index import GPTListIndex
from llama_index.indices.list.retrievers import ListIndexLLMRetriever
index = GPTListIndex.from_documents(documents, service_context=service_context)
# high - level API
query_str = "What did the author do during his time in college?"
retriever = index.as_retriever(retriever_mode="llm")
nodes = retriever.retrieve(query_str)
# lower-level API
retriever = ListIndexLLMRetriever()
response_synthesizer = ResponseSynthesizer.from_args()
query_engine = RetrieverQueryEngine(retriever=retriever, response_synthesizer=response_synthesizer)
response = query_engine.query(query_str)Use Case: This could potentially be used in place of our vector store index. You use the LLM instead of embedding-based lookup to select the nodes.
LLM Reranker (LLMRerank)
This module is defined as part of our NodePostprocessor abstraction, which is defined for second-stage processing after an initial retrieval pass.
The postprocessor can be used on its own or as part of a RetrieverQueryEngine call. In the below example we show how to use the postprocessor as an independent module after an initial retriever call from a vector index.
from llama_index.indices.query.schema import QueryBundle
query_bundle = QueryBundle(query_str)
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=vector_top_k,
)
retrieved_nodes = retriever.retrieve(query_bundle)
# configure reranker
reranker = LLMRerank(choice_batch_size=5, top_n=reranker_top_n, service_context=service_context)
retrieved_nodes = reranker.postprocess_nodes(retrieved_nodes, query_bundle)Limitations/Caveats
There are certain limitations and caveats to LLM-based retrieval, especially with this initial version.
- LLM-based retrieval is orders of magnitude slower than embedding-based retrieval. Embedding search over thousands or even millions of embeddings can take less than a second. Each LLM prompt of 4000 tokens to OpenAI can take minutes to complete.
- Using third-party LLM API’s costs money.
- The current method of batching documents may not be optimal, because it relies on an assumption that document batches can be scored independently of each other. This lacks a global view of the ranking for all documents.
Using the LLM to retrieve and rank every node in the document corpus can be prohibitively expensive. This is why using the LLM as a second-stage reranking step, after a first-stage embedding pass, can be helpful.
Initial Experimental Results
Let’s take a look at how well LLM reranking works!
We show some comparisons between naive top-k embedding-based retrieval as well as the two-stage retrieval pipeline with a first-stage embedding-retrieval filter and second-stage LLM reranking. We also showcase some results of pure LLM-based retrieval (though we don’t showcase as many results given that it tends to run a lot slower than either of the first two approaches).
We analyze results over two very different sources of data: the Great Gatsby and the 2021 Lyft SEC 10-k. We only analyze results over the “retrieval” portion and not synthesis to better isolate the performance of different retrieval methods.
The results are presented in a qualitative fashion. A next step would definitely be more comprehensive evaluation over an entire dataset!
The Great Gatsby
In our first example, we load in the Great Gatsby as a Document object, and build a vector index over it (with chunk size set to 512).
# LLM Predictor (gpt-3.5-turbo) + service context
llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo"))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor, chunk_size_limit=512)
# load documents
documents = SimpleDirectoryReader('../../../examples/gatsby/data').load_data()
index = GPTVectorStoreIndex.from_documents(documents, service_context=service_context)We then define a get_retrieved_nodes function — this function can either do just embedding-based retrieval over the index, or embedding-based retrieval + reranking.
def get_retrieved_nodes(
query_str, vector_top_k=10, reranker_top_n=3, with_reranker=False
):
query_bundle = QueryBundle(query_str)
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=vector_top_k,
)
retrieved_nodes = retriever.retrieve(query_bundle)
if with_reranker:
# configure reranker
reranker = LLMRerank(choice_batch_size=5, top_n=reranker_top_n, service_context=service_context)
retrieved_nodes = reranker.postprocess_nodes(retrieved_nodes, query_bundle)
return retrieved_nodesWe then ask some questions. With embedding-based retrieval we set k=3. With two-stage retrieval we set k=10 for embedding retrieval and n=3 for LLM-based reranking.
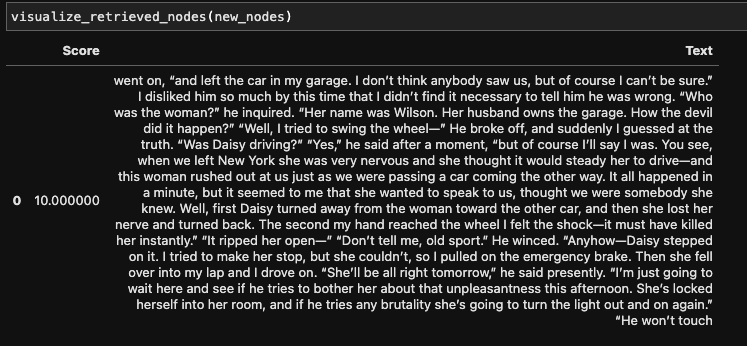
Question: ”Who was driving the car that hit Myrtle?”
(For those of you who are not familiar with the Great Gatsby, the narrator finds out later on from Gatsby that Daisy was actually the one driving the car, but Gatsby takes the blame for her).
The top retrieved contexts are shown in the images below. We see that in embedding-based retrieval, the top two texts contain semantics of the car crash but give no details as to who was actually responsible. Only the third text contains the proper answer.

In contrast, the two-stage approach returns just one relevant context, and it contains the correct answer.
2021 Lyft SEC 10-K
We want to ask some questions over the 2021 Lyft SEC 10-K, specifically about the COVID-19 impacts and responses. The Lyft SEC 10-K is 238 pages long, and a ctrl-f for “COVID-19” returns 127 matches.
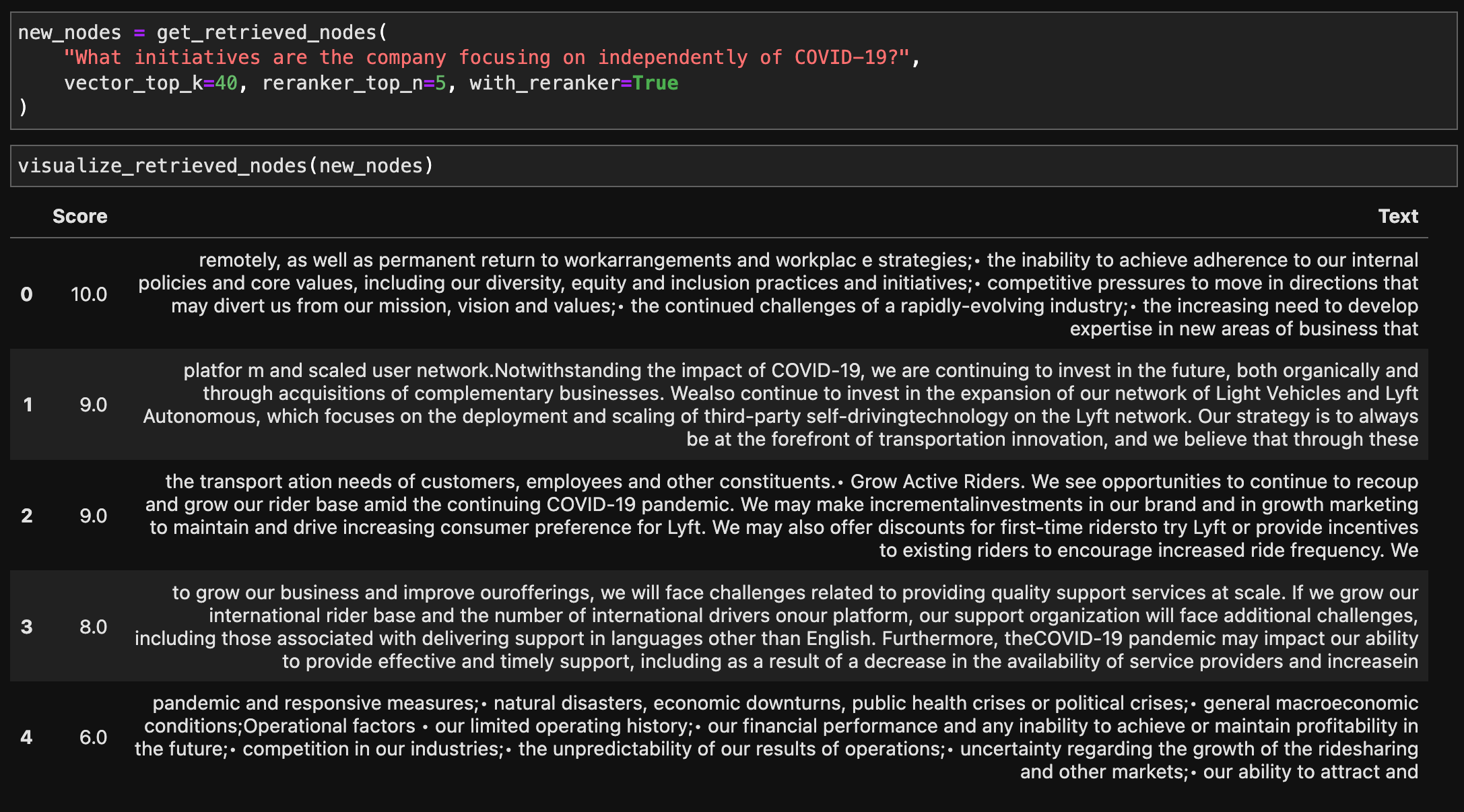
We use a similar setup as the Gatsby example above. The main differences are that we set the chunk size to 128 instead of 512, we set k=5 for the embedding retrieval baseline, and an embedding k=40 and reranker n=5 for the two-stage approach.
We then ask the following questions and analyze the results.
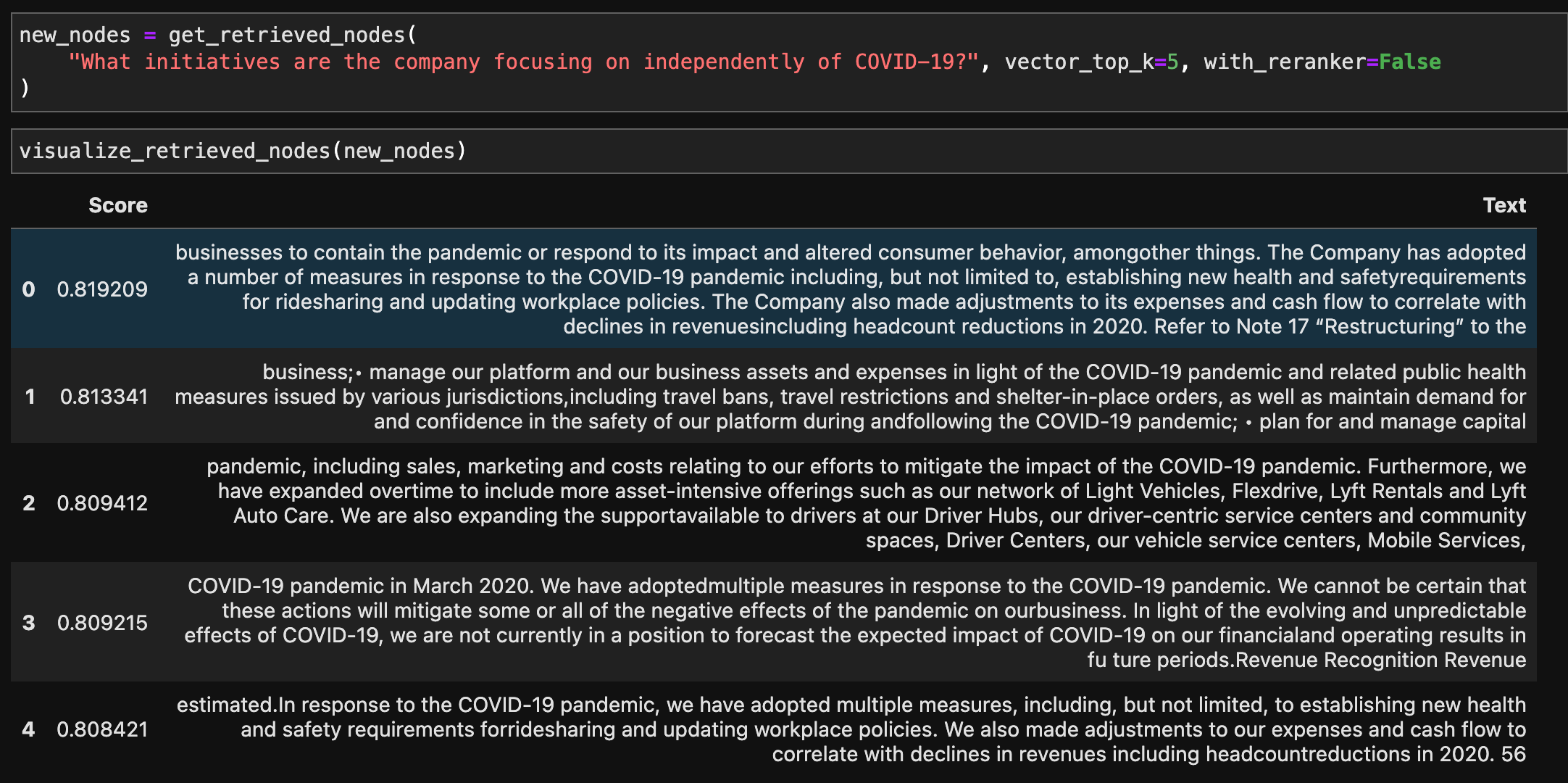
Question: “What initiatives are the company focusing on independently of COVID-19?”
Results for the baseline are shown in the image above. We see that results corresponding to indices 0, 1, 3, 4, are about measures directly in response to Covid-19, even though the question was specifically about company initiatives that were independent of the COVID-19 pandemic.
We get more relevant results in approach 2, by widening the top-k to 40 and then using an LLM to filter for the top-5 contexts. The independent company initiatives include “expansion of Light Vehicles” (1), “incremental investments in brand/marketing” (2), international expansion (3), and accounting for misc. risks such as natural disasters and operational risks in terms of financial performance (4).
Conclusion
That’s it for now! We’ve added some initial functionality to help support LLM-augmented retrieval pipelines, but of course there’s a ton of future steps that we couldn’t quite get to. Some questions we’d love to explore:
- How our LLM reranking implementation compares to other reranking methods (e.g. BM25, Cohere Rerank, etc.)
- What the optimal values of embedding top-k and reranking top-n are for the two stage pipeline, accounting for latency, cost, and performance.
- Exploring different prompts and text summarization methods to help determine document relevance
- Exploring if there’s a class of applications where LLM-based retrieval on its own would suffice, without embedding-based filtering (maybe over smaller document collections?)
Resources
You can play around with the notebooks yourself!