

Google recently released Gemini 1.5 Pro with a 1M context window, available to a limited set of developers and enterprise customers. Its performance has caught the imagination of AI Twitter. It achieves 99.7% recall in the “Needle in a Haystack” experiment popularized by Greg Kamradt. Early users have shared results feeding dozens of research papers, financial reports at once and report impressive results in terms of its ability to synthesize across vast troves of information.
Naturally, this begs the question - is RAG dead? Some folks think so, while others disagree. Those in the first camp make valid points. Most small data use cases can fit within a 1-10M context window. Tokens will get cheaper and faster to process over time. Having an LLM natively interleave retrieval/generation via attention layers leads to a higher response quality compared to the one-shot retrieval present in naive RAG.
We were fortunate to have a preview of Gemini 1.5 Pro’s capabilities, and through playing around with it developed a thesis for how context-augmented LLM applications will evolve. This blog post clarifies our mission as a data framework along with our view of what long-context LLM architectures will look like. Our view is that while long-context LLMs will simplify certain parts of the RAG pipeline (e.g. chunking), there will need to be evolved RAG architectures to handle the new use cases that long-context LLMs bring along. No matter what new paradigms emerge, our mission at LlamaIndex is to build tooling towards that future.
Our Mission Goes Beyond RAG
The goal of LlamaIndex is very simple: enable developers to build LLM applications over their data. This mission goes beyond just RAG. To date we have invested a considerable amount of effort in advancing RAG techniques for existing LLMs, and we’ve done so because it’s enabled developers to unlock dozens of new use cases such as QA over semi-structured data, over complex documents, and agentic reasoning in a multi-doc setting.
But we’re also excited about Gemini Pro, and we will continue to advance LlamaIndex as a production data framework in a long-context LLM future.
An LLM framework is intrinsically valuable. As an open-source data framework, LlamaIndex paves the cowpaths towards building any LLM use case from prototype to production. A framework makes it easier to build these use cases versus building from scratch. We enable all developers to build for these use cases, whether it’s setting up the proper architecture using our core abstractions or leveraging the hundreds of integrations in our ecosystem. No matter what the underlying LLM advancements are and whether RAG continues to exist in its current form, we continue to make the framework production-ready, including watertight abstractions, first-class documentation, and consistency.
We also launched LlamaParse last week. Our mission for LlamaParse remains building the data infra enabling any enterprise to make their vast unstructured, semi-structured, and structured data sources production-ready for use with LLMs.
Initial Gemini 1.5 Pro Observations
During our initial testing we played around with some PDFs: SEC 10K Filings, ArXiv papers, this monster Schematic Design Binder, and more. We will do a lot more deeper analyses once the APIs are available, but in the meantime we share observations below.
Gemini results are impressive and consistent with what we’ve seen in the technical report and on socials:
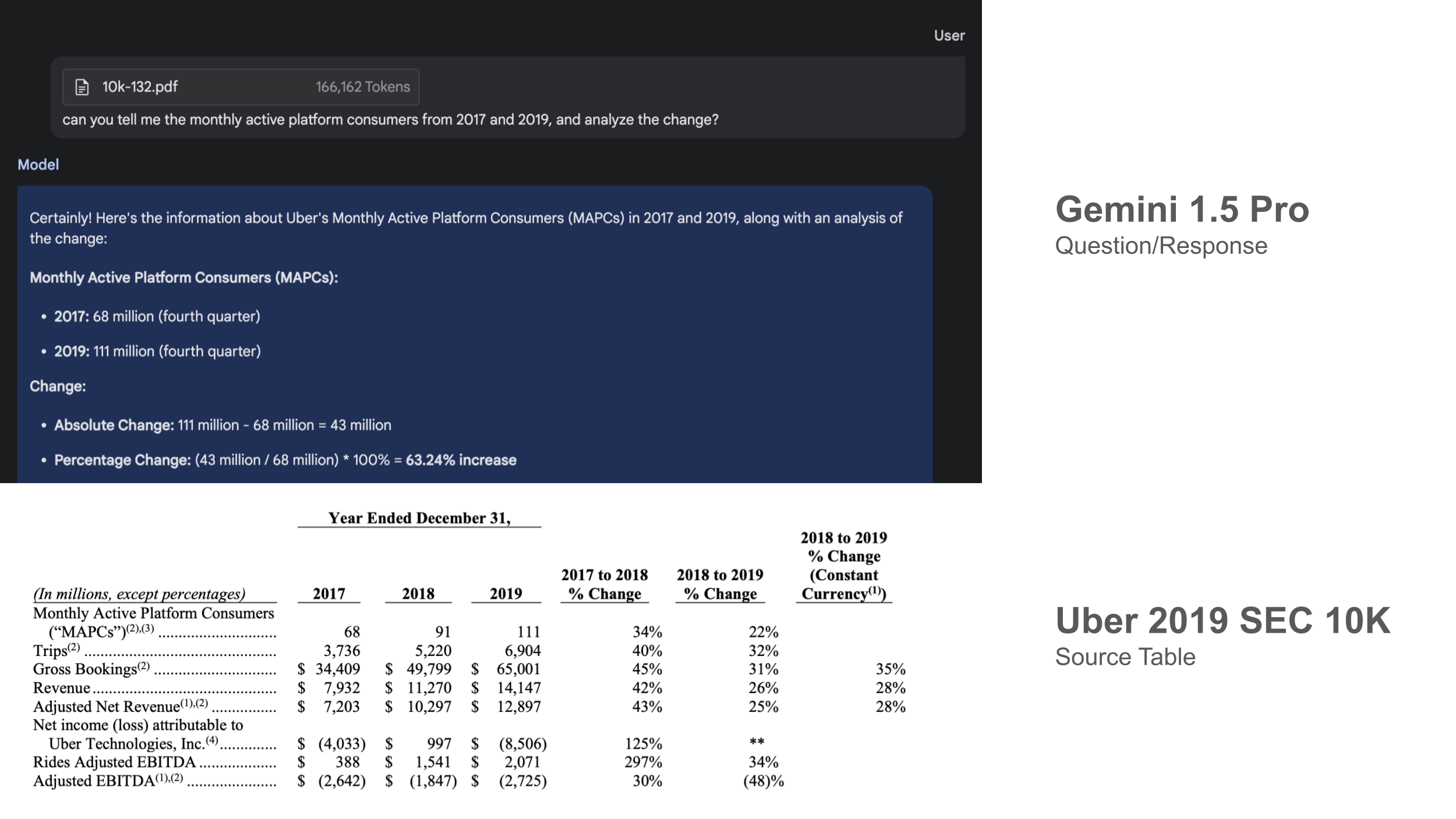
- Gemini has impressive recall of specific details: We threw in 100k-1M tokens of context, and asked questions over very specific details in these documents (unstructured text and tabular data), and in all cases Gemini was able to recall the details. See above for Gemini comparing table results in the 2019 Uber 10K Filing.
- Gemini has impressive summarization capabilities. The model can analyze large swaths of information across multiple documents and synthesize answers.
There are some parts where we noticed Gemini struggles a bit.
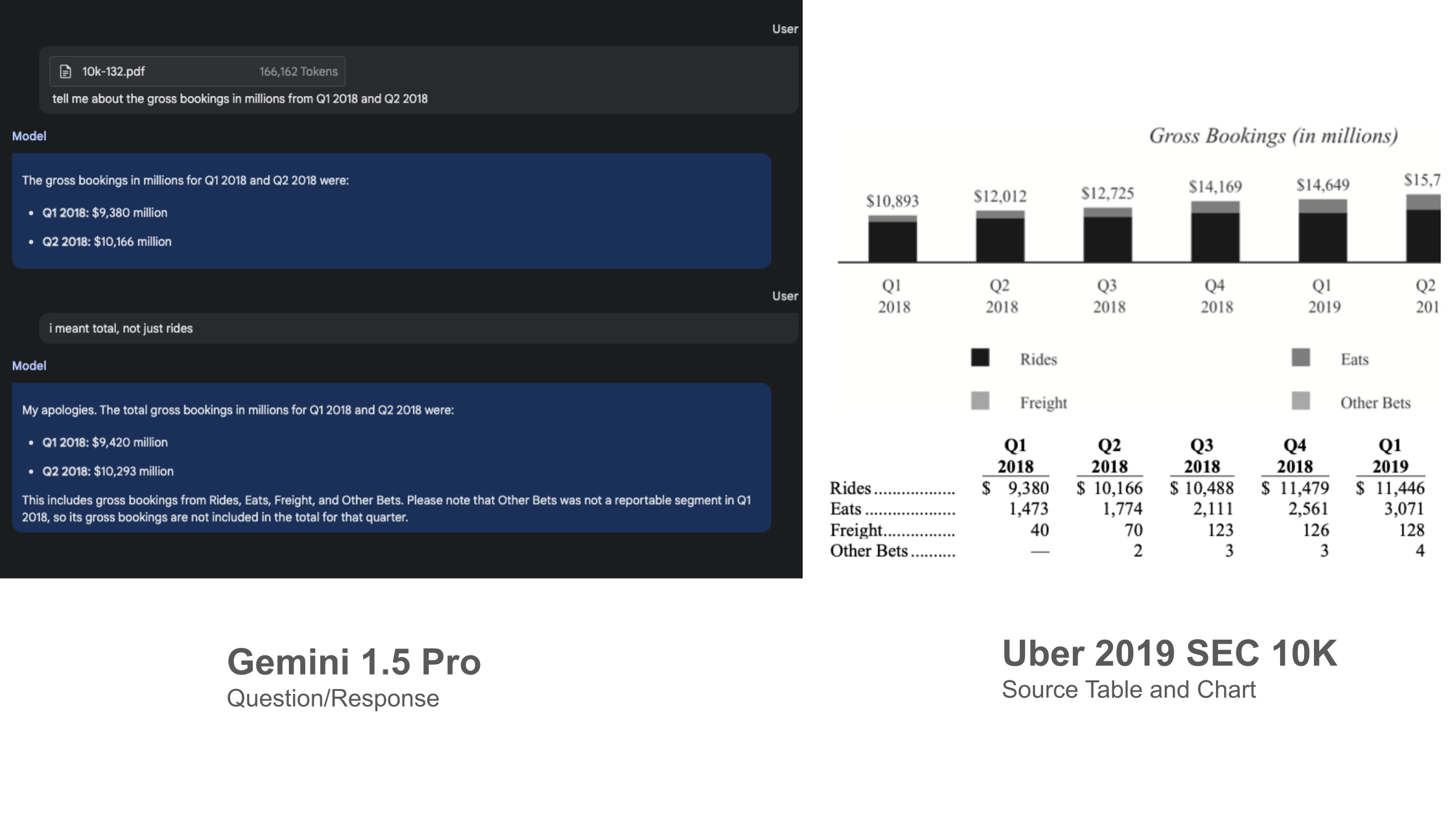
- Gemini doesn’t read all tables and charts correctly. Gemini Pro still has a hard time being able to read figures and complex tables.
- Gemini can take a long time. Returning an answer over the Uber 10K Filing (~160k) takes ~20 seconds. Returning an answer over the LHS Schematic Design Binder (~890k) takes ~60+ seconds.
- Gemini can hallucinate page numbers. When asked to give a summary but also with page number citations, Gemini hallucinated the sources.
Directionally though it’s an exciting glimpse of the future and warrants a bigger discussion on which RAG paradigms will fade and new architectures that will emerge. See below!
Long Contexts Resolve Some Pain Points, but some Challenges Remain
Gemini 1.5 Pro is just the first of many long-context LLMs to emerge, which will inevitably change how users are building RAG.
Here are some existing RAG pain points that we believe long-context LLMs will solve:
- Developers will worry less about how to precisely tune chunking algorithms. We honestly think this will be a huge blessing to LLM developers. Long-context LLMs enable native chunk sizes to be bigger. Assuming per-token cost and latency also go down, developers will no longer have to split hairs deciding how to split their chunks into granular strips through tuning chunking separators, chunk sizes, and careful metadata injection. Long-context LLMs enable chunks to be at the level of entire documents, or at the very least groups of pages.
- Developers will need to spend less time tuning retrieval and chain-of-thought over single documents. An issue with small-chunk top-k RAG is that while certain questions may be answered over a specific snippet of the document, other questions require deep analysis between sections or between two documents (for instance comparison queries). For these use cases, developers will no longer have to rely on a chain-of-thought agent to do two retrievals against a weak retriever; instead, they can just one-shot prompt the LLM to obtain the answer.
- Summarization will be easier. This is related to the above statement. A lot of summarization strategies over big documents involve “hacks” such as sequential refinement or hierarchical summarization (see our response synthesis modules as a reference guide). This can now be alleviated with a single LLM call.
- Personalized memory will be better and easier to build: A key issue for building conversational assistants is figuring out how to load sufficient conversational context into the prompt window. 4k tokens easily overflows this window for very basic web search agents - if it decides to load in a Wikipedia page for instance, that text will easily overflow the context. 1M-10M context windows will let developers more easily implement conversational memory with fewer compression hacks (e.g. vector search or automatic KG construction).
There are, however, some lingering challenges:
- 10M tokens is not enough for large document corpuses - kilodoc retrieval is still a challenge. 1M tokens is around ~7 Uber SEC 10K filings. 10M tokens would be around ~70 filings. 10M tokens is roughly bounded by 40MB of data. While this is enough for many “small” document corpuses, many knowledge corpuses in the enterprise are in the gigabytes or terabytes. To build LLM-powered systems over these knowledge corpuses, developers will still need to build in some way of retrieving this data to augment language models with context.
- Embedding models are lagging behind in context length. So far the largest context window we’ve seen for embeddings are 32k from together.ai. This means that even if the chunks used for synthesis with long-context LLMs can be big, any text chunks used for retrieval still need to be a lot smaller.
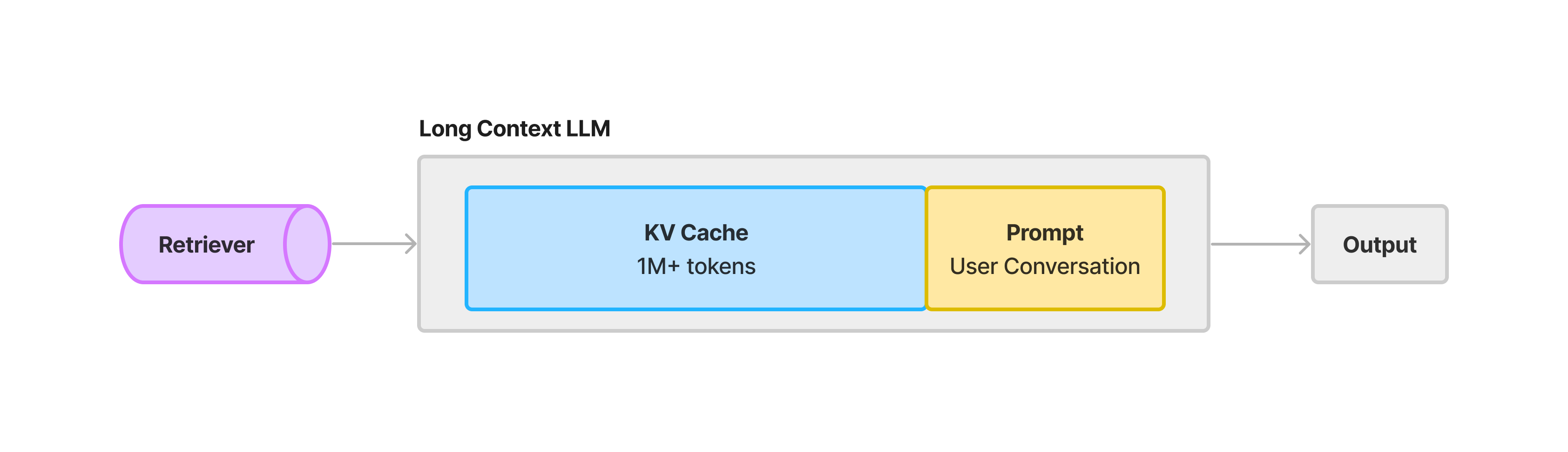
- Cost and Latency. Yes, all cost and latency concerns are alleviated with time. Nevertheless, stuffing a 1M context window takes ~60 seconds and can cost anywhere from $0.50 to $20 with current pricing. An solution to this that Yao Fu brought up is that a KV Cache can cache the document activations, so that any subsequent generations can reuse the same cache. Which leads to our next point below.
- A KV Cache takes up a significant amount of GPU memory, and has sequential dependencies. We chatted with Yao and he mentioned that at the moment, caching 1M tokens worth of activations would use up approximately 100GB of GPU memory, or 2 H100s. There are also interesting challenges on how to best manage the cache especially when the underlying corpus is big - since each activation is a function of all tokens leading up to it, replacing any document in the KV cache would affect all activations following the document.
Towards New RAG Architectures
Proper usage of long-context LLMs will necessitate new architectures to best take advantage of their capabilities, while working around their remaining constraints. We outline some proposals below.
1. Small to Big Retrieval over Documents
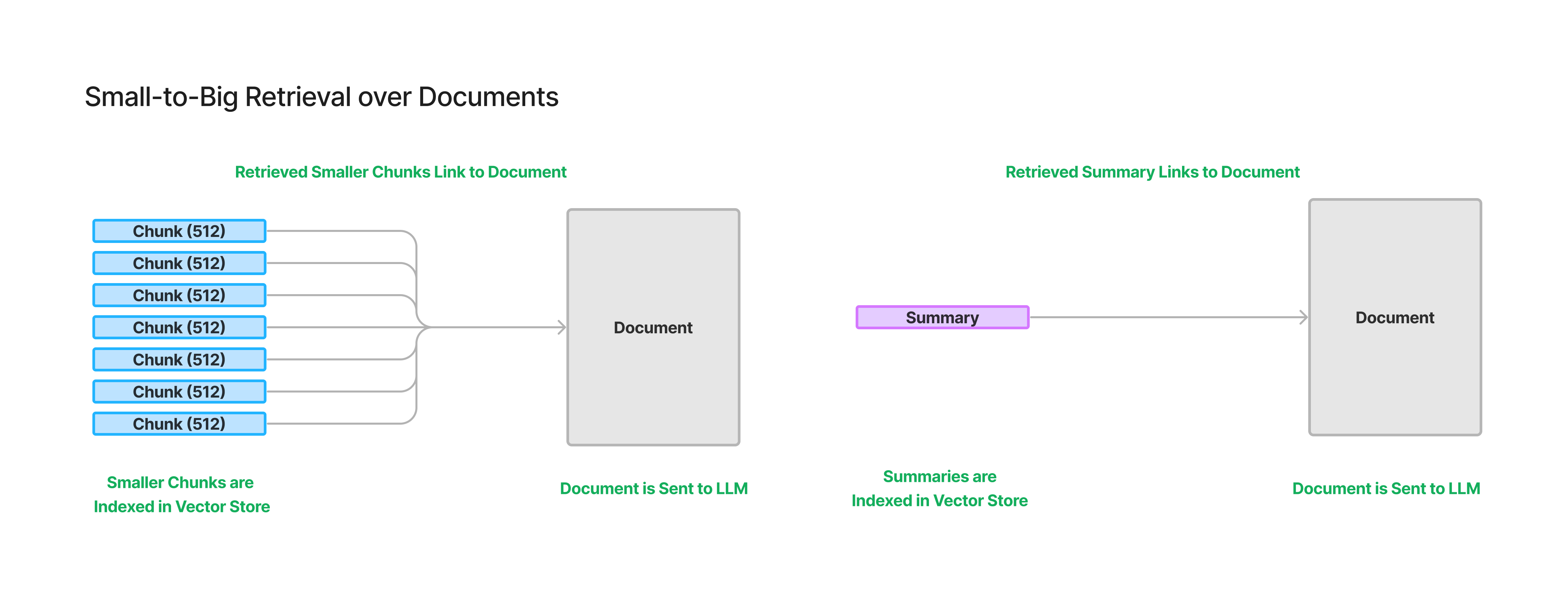
To the extent that long-context LLMs need retrieval augmentation over big knowledge bases (e.g. in the gigabytes), we will need small-to-big retrieval: index and retrieve small chunks, but have each chunk link to big chunks that will ultimately be fed to LLMs during synthesis.
This architecture already exists in LlamaIndex in different forms (sentence window retriever and recursive retrieval over chunk sizes), but can be scaled up even more for long-context LLMs - embed document summaries, but link to entire documents.
One reason we want to embed and index smaller chunks is due to the fact that current embedding models are not keeping up with LLMs in terms of context length. Another reason is that there can actually be retrieval benefits in having multiple granular embedding representations compared to a single document-level embedding for a document. If there is a single embedding for a document, then that embedding has the burden of encoding all information throughout the entire document. On the other hand, we’ve found that embedding many smaller chunks and having each small chunk link to a bigger chunk, will lead to better retrieval of the relevant information.
Check out the diagram above for an illustration of two flavors of small-to-big retrieval. One is indexing document summaries and linking them to documents, and the other is indexing smaller chunks within a document and linking them to the document. Of course, you could also do both - a general best practice for improving retrieval is to just try out multiple techniques at once and fuse the results later.
2. Intelligent Routing for Latency/Cost Tradeoffs
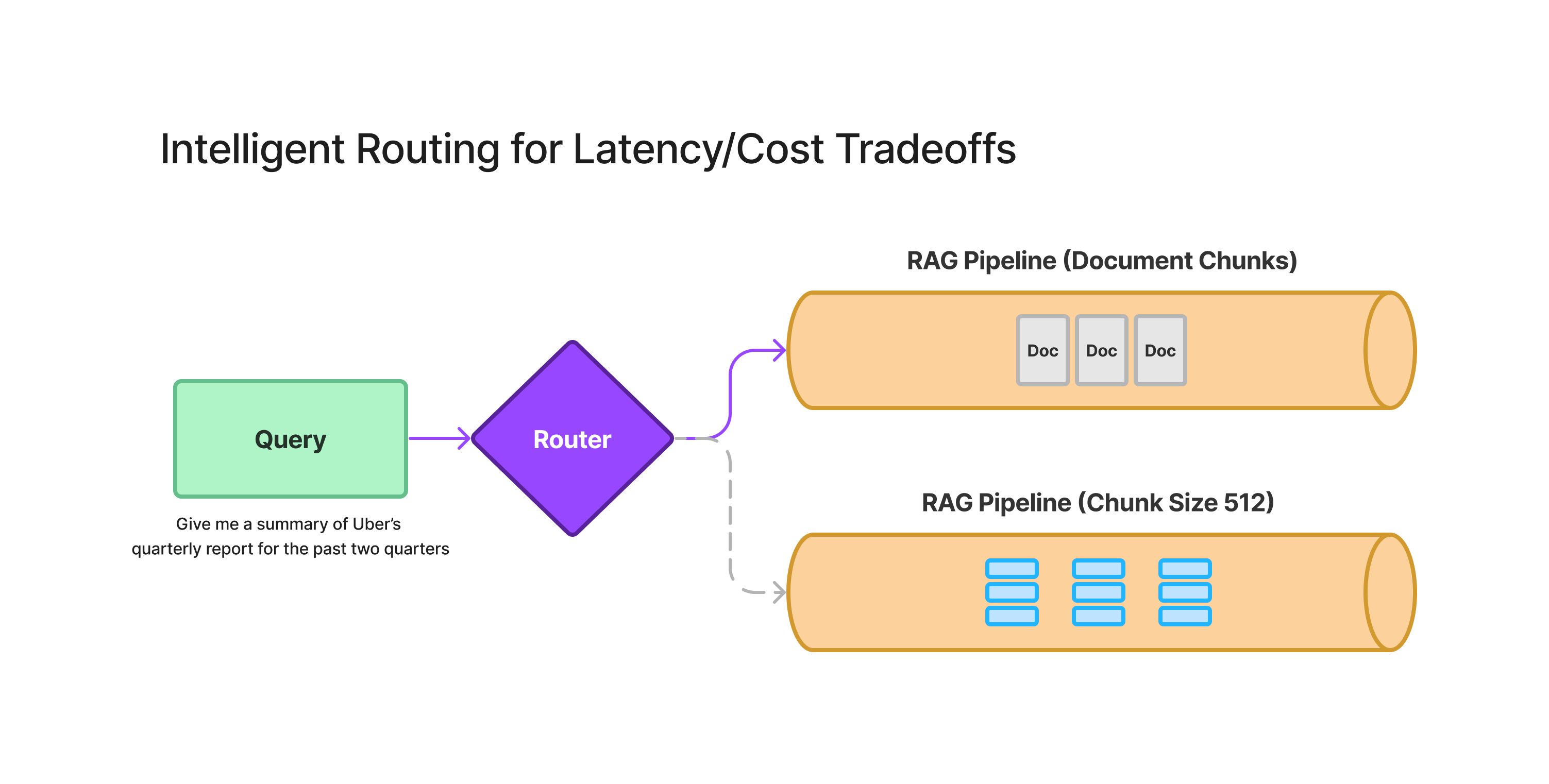
The arrival of long-context LLMs will inevitably raise questions on the amount of context that is suitable for each use case. Injecting LLMs with long context comes with real cost and latency tradeoffs and isn’t suitable for every use case or even every question. Although cost and latency will decrease in the future, we anticipate users will need to think carefully about this tradeoff for the next year or two.
Certain questions that are asking about specific details are well suited for existing RAG techniques of top-k retrieval and synthesis.
More complex questions require more context from disparate pieces of different documents, and in those settings it is less clear how to correctly answer these questions while optimizing for latency and cost:
- Summarization questions require going over entire documents.
- Multi-part questions can be solved by doing chain-of-thought and interleaving retrieval and reasoning; they can also be solved by shoving all context into the prompt.
We imagine an intelligent routing layer that operates on top of multiple RAG and LLM synthesis pipelines over a knowledge base. Given a question, the router can ideally choose an optimal strategy in terms of cost and latency in terms of retrieving context to answer the question. This ensures that a single interface can handle different types of questions while not becoming prohibitively expensive.
3. Retrieval Augmented KV Caching
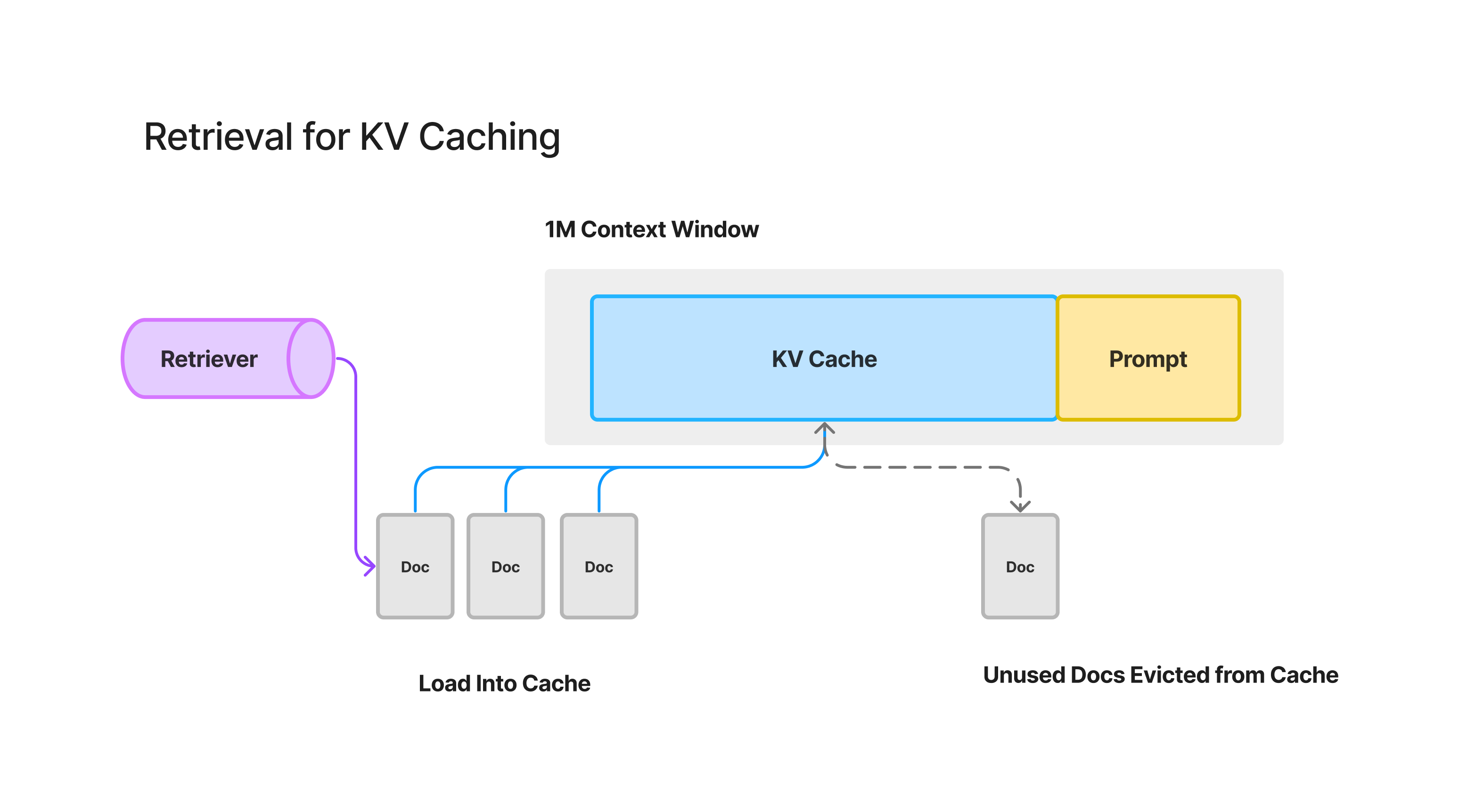
An optimization that Google and other companies are certainly working on is resolving latency and cost concerns through a KV Cache. At a high-level, a KV cache stores activations from pre-existing key and query vectors in an attention layer, preventing the need to recompute activations across the entire text sequence during LLM generation (we found this to be a nice intro reference to how a KV Cache works).
Using a KV Cache to cache all document tokens within the context window prevents the need to recompute activations for these tokens on subsequent conversations, bringing down latency and cost significantly.
But this leads to interesting retrieval strategies on how to best use the cache, particularly for knowledge corpuses that exceed the context length. We imagine a “retrieval augmented caching” paradigm emerging, where we want to retrieve the most relevant documents that the user would want to answer, with the expectation that they will continue to use the documents that are in the cache.
This could involve interleaving retrieval strategies with traditional caching algorithms such as LRU caching. But a difference with existing KV cache architectures is that the position matters, since the cached vector is a function of all tokens leading up to that position, not just the tokens in the document itself. This means that you can’t just swap out a chunk from the KV cache without affecting all cached tokens that occur after it positionally.
In general the API interface for using a KV Cache is up in the air. It’s also up in the air as to whether the nature of the cache itself will evolve or algorithms will evolve to best leverage the cache.
What’s Next
We believe the future of LLM applications is bright, and we are excited to be at the forefront of this rapidly evolving field. We invite developers and researchers to join us in exploring the possibilities of long-context LLMs and building the next generation of intelligent applications.


