This is a guest post from the team at Langfuse
There are so many different ways to make RAG work for a use case. What vector store to use? What retrieval strategy to use? LlamaIndex makes it easy to try many of them without having to deal with the complexity of integrations, prompts and memory all at once.
Initially, we at Langfuse worked on complex RAG/agent applications and quickly realized that there is a new need for observability and experimentation to tweak and iterate on the details. In the end, these details matter to get from something cool to an actually reliable RAG application that is safe for users and customers. Think of this: if there is a user session of interest in your production RAG application, how can you quickly see whether the retrieved context for that session was actually relevant or the LLM response was on point?
Thus, we started working on Langfuse.com (GitHub) to establish an open source LLM engineering platform with tightly integrated features for tracing, prompt management, and evaluation. In the beginning we just solved our own and our friends’ problems. Today we are at over 1000 projects which rely on Langfuse, and 2.3k stars on GitHub. You can either self-host Langfuse or use the cloud instance maintained by us.
We are thrilled to announce our new integration with LlamaIndex today. This feature was highly requested by our community and aligns with our project's focus on native integration with major application frameworks. Thank you to everyone who contributed and tested it during the beta phase!
The challenge
We love LlamaIndex, since the clean and standardized interface abstracts a lot of complexity away. Let’s take this simple example of a VectorStoreIndex and a ChatEngine.
python
from llama_index.core import SimpleDirectoryReader
from llama_index.core import VectorStoreIndex
documents = SimpleDirectoryReader("./data").load_data()
index = VectorStoreIndex.from_documents(documents)
chat_engine = index.as_chat_engine()
print(chat_engine.chat("What problems can I solve with RAG?"))
print(chat_engine.chat("How do I optimize my RAG application?"))In just 3 lines we loaded our local documents, added them to an index and initialized a ChatEngine with memory. Subsequently we had a stateful conversation with the chat_engine.
This is awesome to get started, but we quickly run into questions like:
- “What context is actually retrieved from the index to answer the questions?”
- “How is chat memory managed?”
- “Which steps add the most latency to the overall execution? How to optimize it?”
One-click OSS observability to the rescue
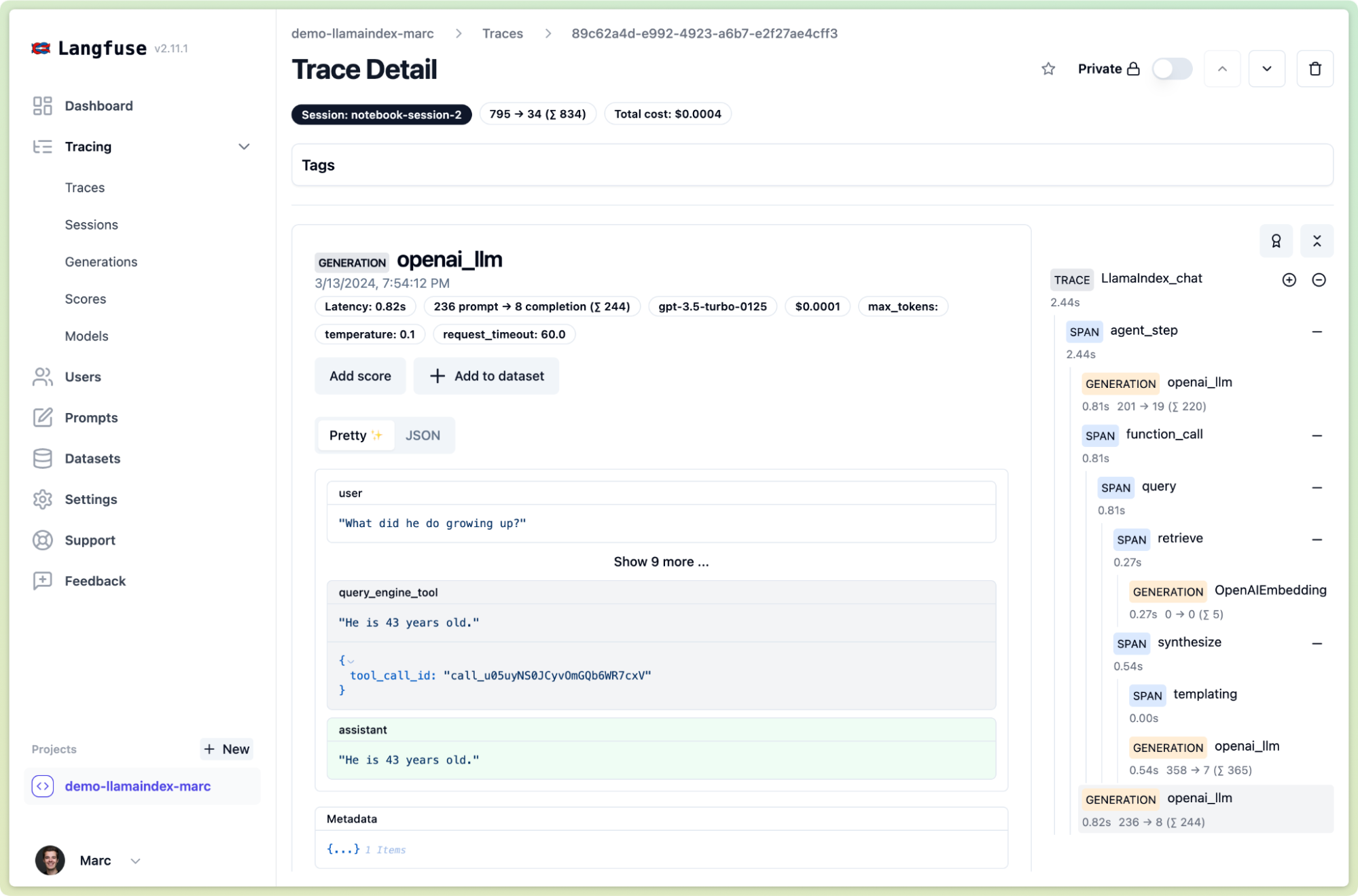
We integrated Langfuse to be a one-click integration with LlamaIndex using the global callback manager.
Preparation
- Install the community package (pip install llama-index-callbacks-langfuse)
- Copy/paste the environment variables from the Langfuse project settings to your Python project: 'LANGFUSE_SECRET_KEY', 'LANGFUSE_PUBLIC_KEY' and 'LANGFUSE_HOST'
Now, you only need to set the global langfuse handler:
python
from llama_index.core import set_global_handler
set_global_handler("langfuse")And voilá, with just two lines of code you get detailed traces for all aspects of your RAG application in Langfuse. They automatically include latency and usage/cost breakdowns.
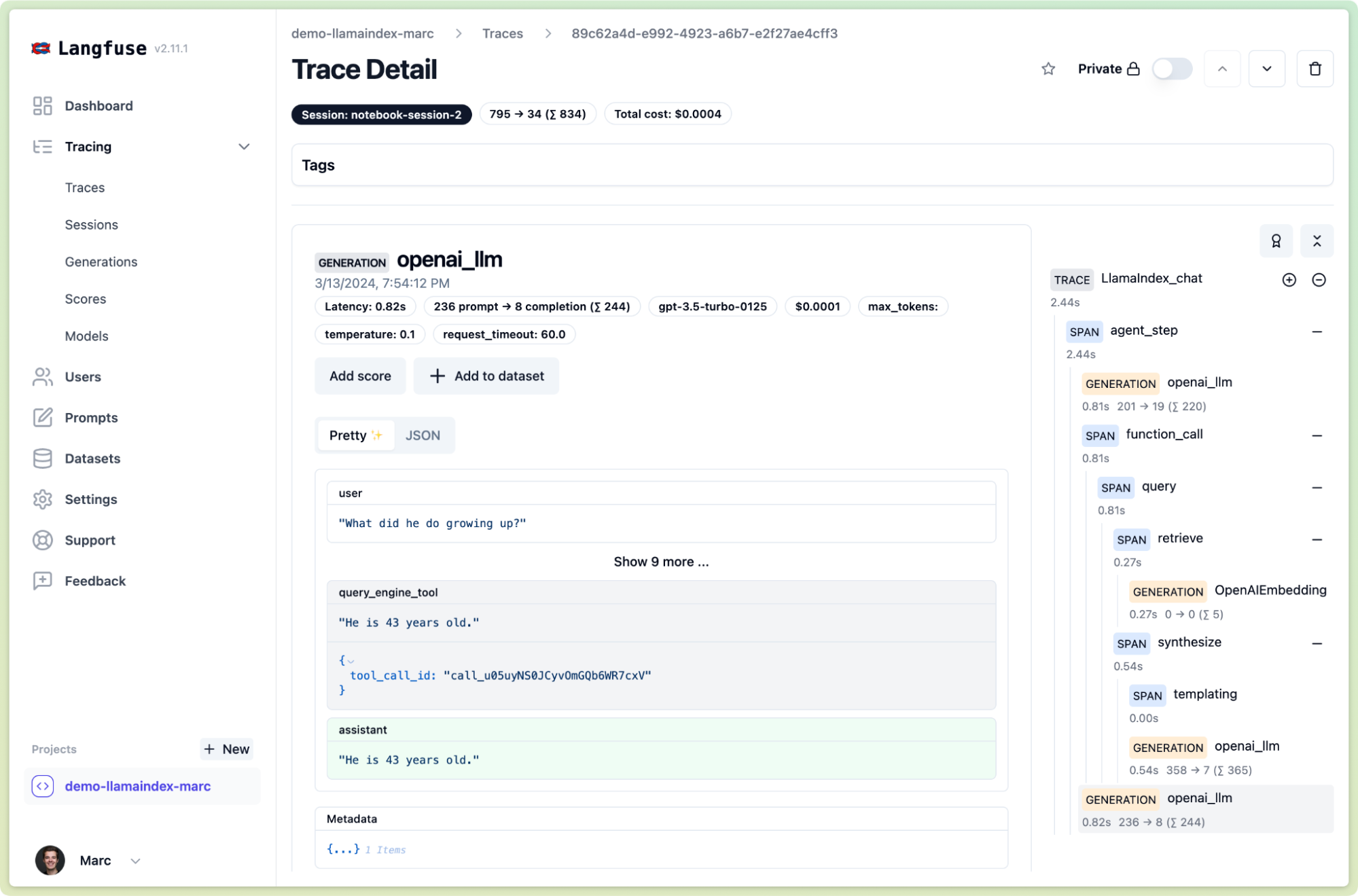
Group multiple chat threads into a session
Working with lots of teams building GenAI/LLM/RAG applications, we’ve continuously added more features that are useful to debug and improve these applications. One example is session tracking for conversational applications to see the traces in context of a full message thread.
To activate it, just add an id that identifies the session as a trace param before calling the chat_engine.
python
from llama_index.core import global_handler
global_handler.set_trace_params(
session_id="your-session-id"
)
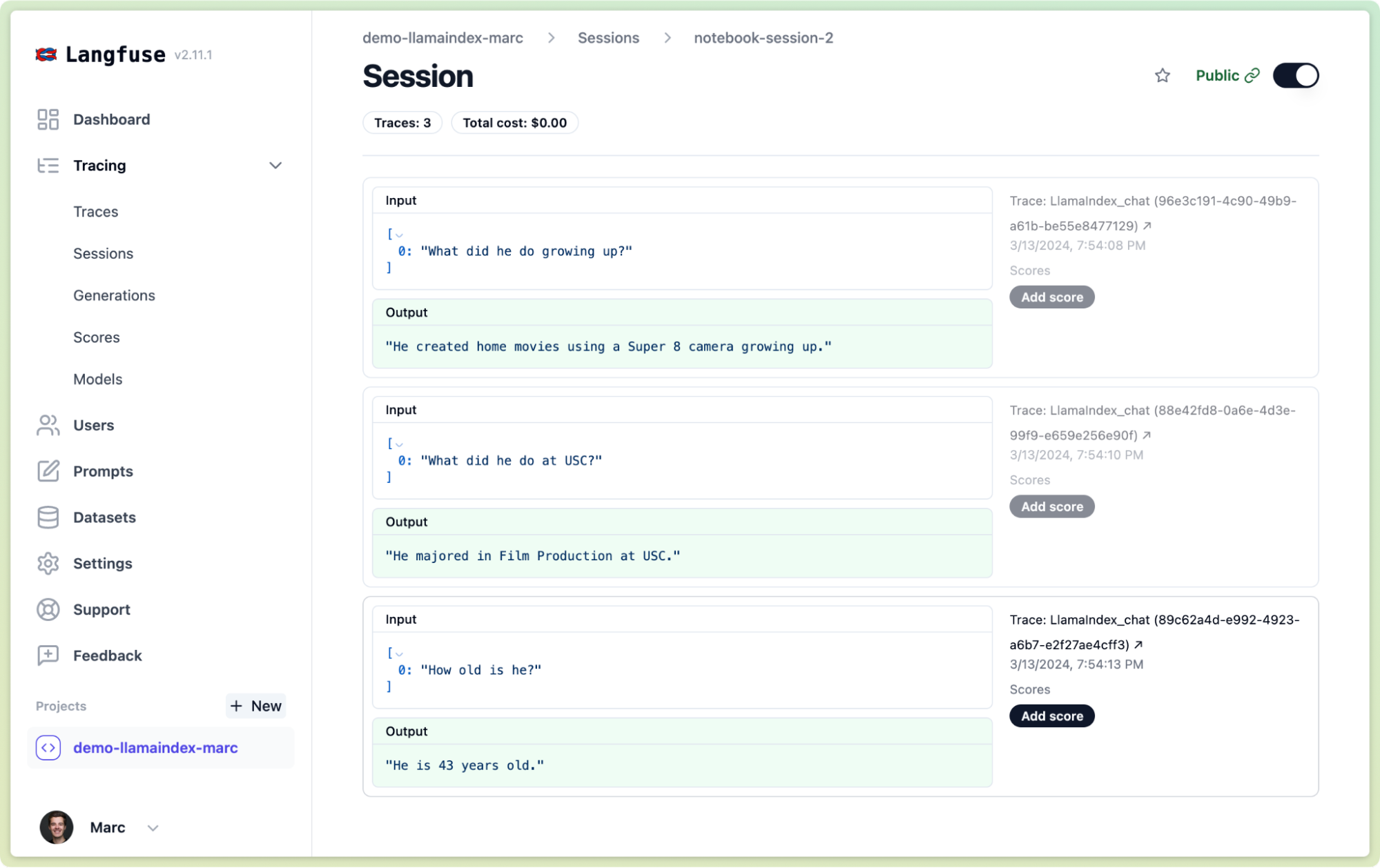
chat_engine.chat("What did he do growing up?")
chat_engine.chat("What did he do at USC?")
chat_engine.chat("How old is he?")Thereby you can see all these chat invocations grouped into a session view in Langfuse Tracing:
Next to sessions, you can also track individual users or add tags and metadata to your Langfuse traces.
Trace more complex applications and use other Langfuse features for prompt management and evaluation
This integration makes it easy to get started with Tracing. If your application ends up growing into using custom logic or other frameworks/packages, all Langfuse integrations are fully interoperable.
We have also built additional features to version control and collaborate on prompts (langfuse prompt management), track experiments, and evaluate production traces. For RAG specifically, we collaborated with the RAGAS team and it’s easy to run their popular eval suite on traces captured with Langfuse (see cookbook).
Get started
The easiest way to get started is to follow the cookbook and check out the docs.
Feedback? Ping us
We’d love to hear any feedback. Come join us on our community discord or add your thoughts to this GitHub thread.