
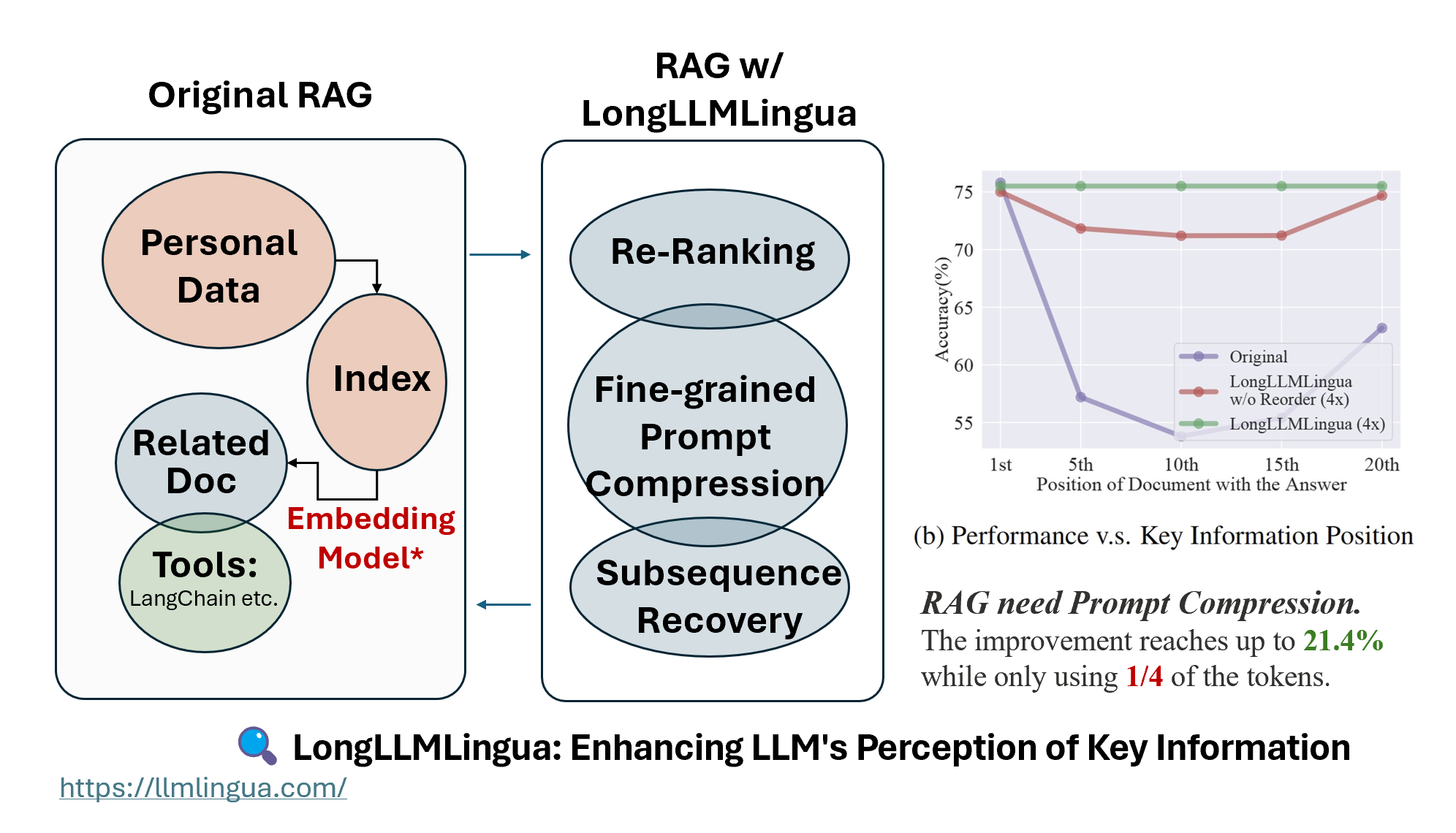
In the RAG, after the retrieval phase, it’s necessary to perform Re-ranking + Fine-Grained Prompt Compression + Subsequence Recovery to enhance LLM’s perception of key information, which is LongLLMLingua.
TL;DR: While Retrieval-Augmented Generation (RAG) is highly effective in various scenarios, it still has drawbacks such as 1) Performance drop, like the “Lost in the middle” issue, 2) High costs, both financially and in terms of latency, and 3) Context windows limitation. LongLLMLingua offers a solution to these problems in RAG or Long Context scenarios via prompt compression. It can boost accuracy by as much as 21.4% while only using ¼ of the tokens. In long context situations, it can save $28 for every 1000 examples.
See real-world cases on the project page.
We previously wrote a blog post introducing the design of LLMLingua, which started from the perspective of designing a special language for LLMs. This time, our focus will be on the scenarios involving RAG.
Retrieval-Augmented Generation is currently the most reliable and proven technique for creating AI-agents that are grounded on any specific collection of text. Frameworks like LlamaIndex provide comprehensive RAG solutions to help users utilize specialized data in LLMs more conveniently.
A common misunderstanding is that retrieving as many relevant documents as possible during the RAG process and stitching them together to form a long retrieved prompt is beneficial, especially as more and more LLMs support longer context windows. However, this method can introduce more noise into the prompt and weaken the LLM’s perception of key information, leading to issues such as ‘lost in the middle’[1].
These issues become more apparent in real-world scenarios involving RAG. Better retrieval mechanisms can introduce higher quality noise documents, which can more easily lead to a drop in performance.
Re-ranking is an intuitive concept.
One intuitive idea is to reposition the most relevant information to the sides of the prompt through re-ranking. This concept of re-ranking has already been implemented in frameworks such as LlamaIndex and LangChain.
However, according to our experiments, it’s difficult for an embedding model to serve as a ‘good’ re-ranker. The underlying reason is the lack of an interaction process between the query and the document. The dual-tower structure of embeddings is not suitable for re-ranking in general scenarios, although it may be effective after fine-tuning.
Using LLMs directly as a re-ranker may also lead to misjudgments due to hallucinations. Recently, some re-ranking models have been extended from embedding models, such as bge-rerank. However, such re-ranking models generally have context window limitations.
To address the above issues, we propose a Question-aware Coarse-Grained prompt compression method. This method evaluates the relevance between the context and the question based on the perplexity corresponding to the question.
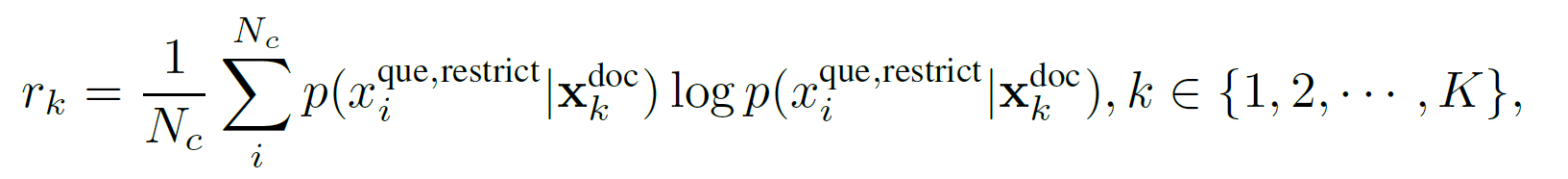
To mitigate the hallucination problem in smaller LLMs, we append a restrictive statement, specifically “We can get the answer to this question in the given documents”, after the question to limit the latent space caused by related hallucinations.
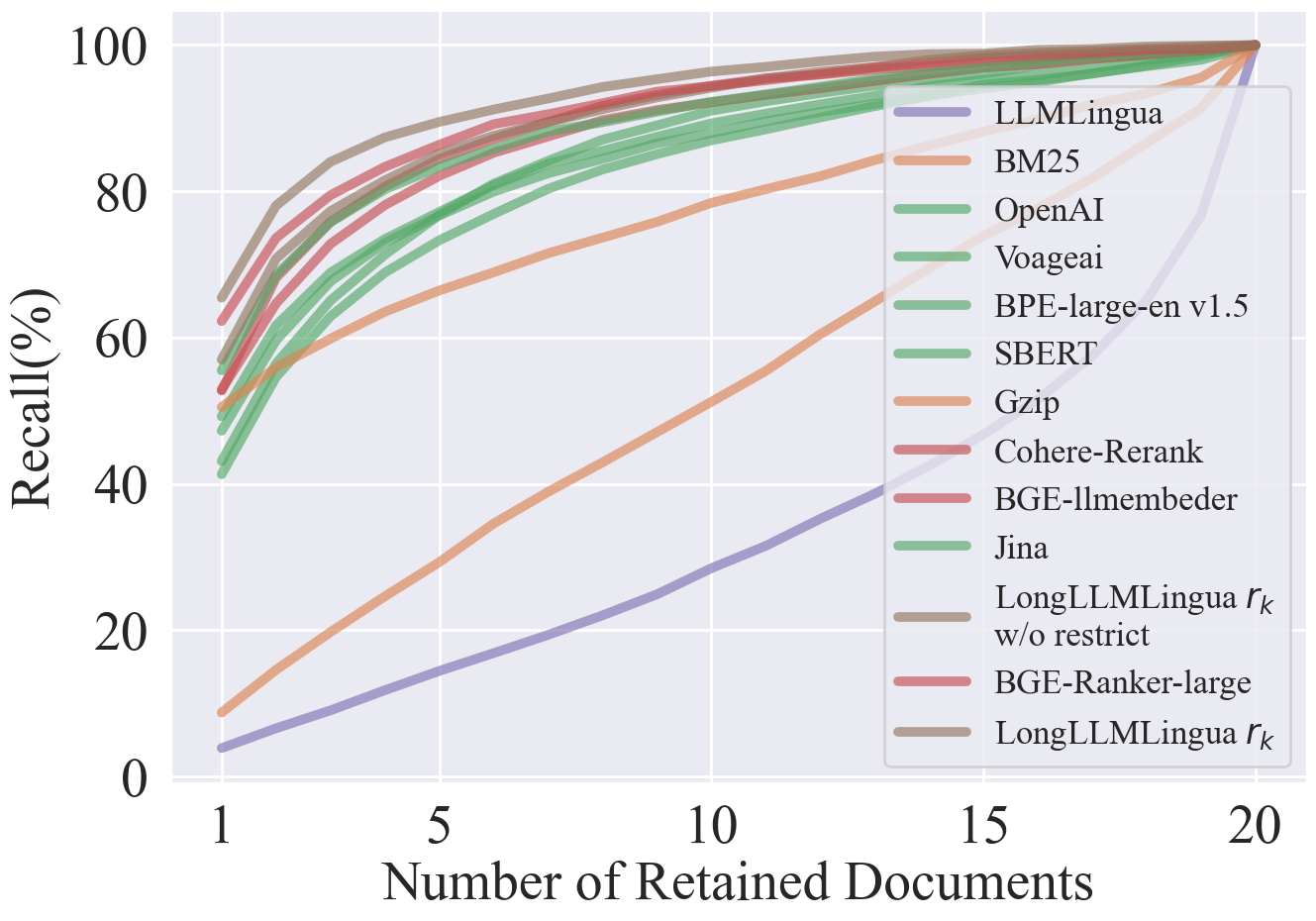
Results show that this approach significantly outperforms both embedding models and re-ranking models. We’ve added some recently released embedding and reranking models. As you can see, the performance of bge-rerank-large is very close to that of LongLLMLingua. Reranking models generally perform better than embedding models. Currently, Jina is the best performing method among the embedding models.
Compress unrelated and unimportant information
Besides recalling as many relevant documents as possible, another approach is to compress irrelevant or unimportant contexts as much as possible.
Previous work on long context has focused on how to extend LLMs to support longer context windows. However, almost no work has explored whether this can actually improve the performance of downstream tasks. Some previous studies have shown that the presence of more noise in the prompt, as well as the position of key information in the prompt, can affect the performance of LLMs.
From the perspective of prompt compression, Selective Context[2] and LLMLingua[3] estimate the importance of elements by using a small language model to calculate the mutual information or perplexity of the prompt. However, in scenarios like RAG or long context scenarios, this method can easily lose key information because it cannot perceive the question information.
In recent submissions to ICLR’24, there have been some similar practices. For example, Recomp[4] reduces the use of tokens in RAG scenarios by jointly training compressors of two different granularities. RAG in Long Context[5] decomposes the long context into a series of chunks and uses retrieval methods for compression, which is actually the retrieval-based method implemented in the LongLLMLingua paper. In addition, Walking Down the Memory Maze[6] also designed a hierarchical summarization tree to enhance the LLM’s perception of key information.
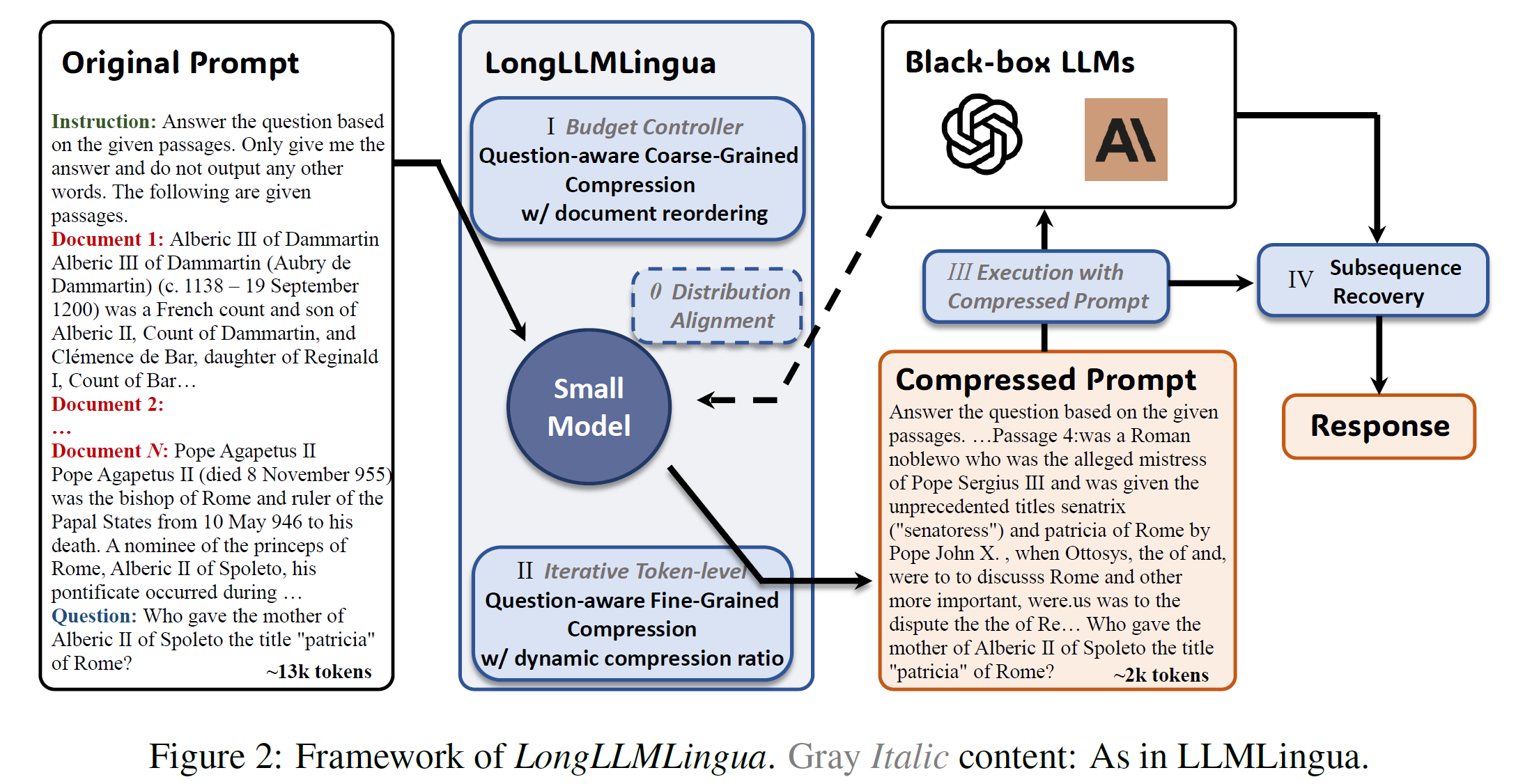
Question-aware Fine-grained Prompt Compression
In order to make token-level prompt compression also perceive the information of the question, we propose a contrastive perplexity, which compares the difference between the perplexity distribution corresponding to the document and the perplexity distribution corresponding to the document with the question.
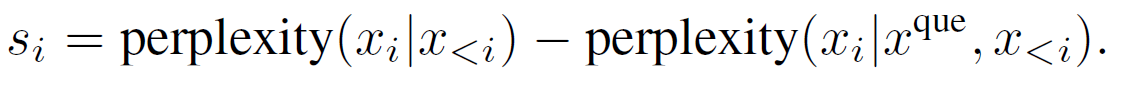
An intuitive feeling is that when the question serves as context, the perplexity corresponding to the relevant tokens in the document will decrease. This decrease in magnitude represents the importance of the tokens in the document relative to the question.
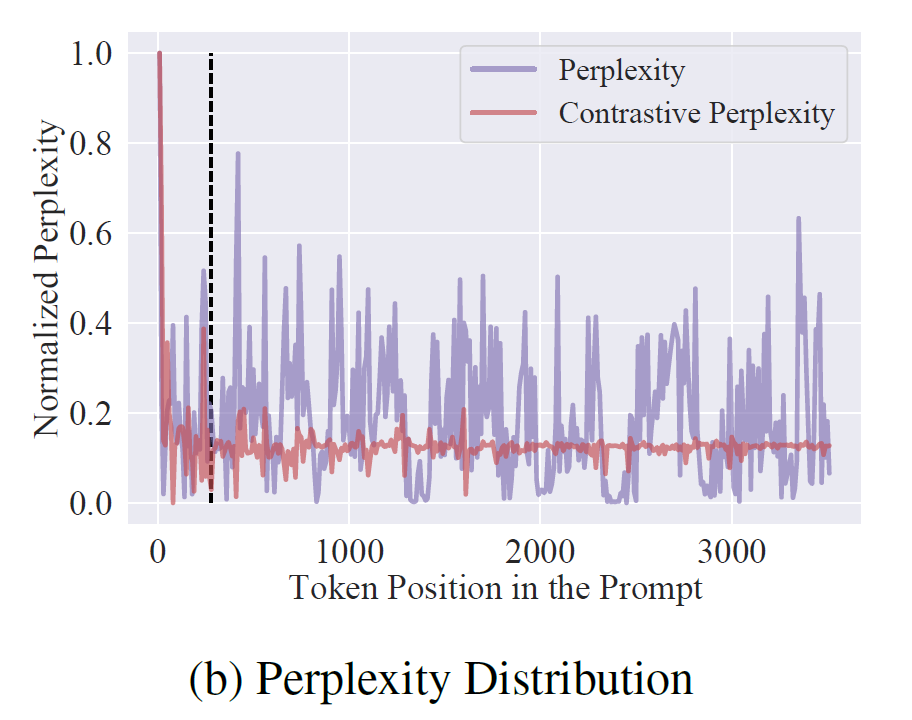
Figure 3 shows the distribution difference in extracting key tokens between perplexity and contrastive perplexity.
How to reduce the loss in the middle
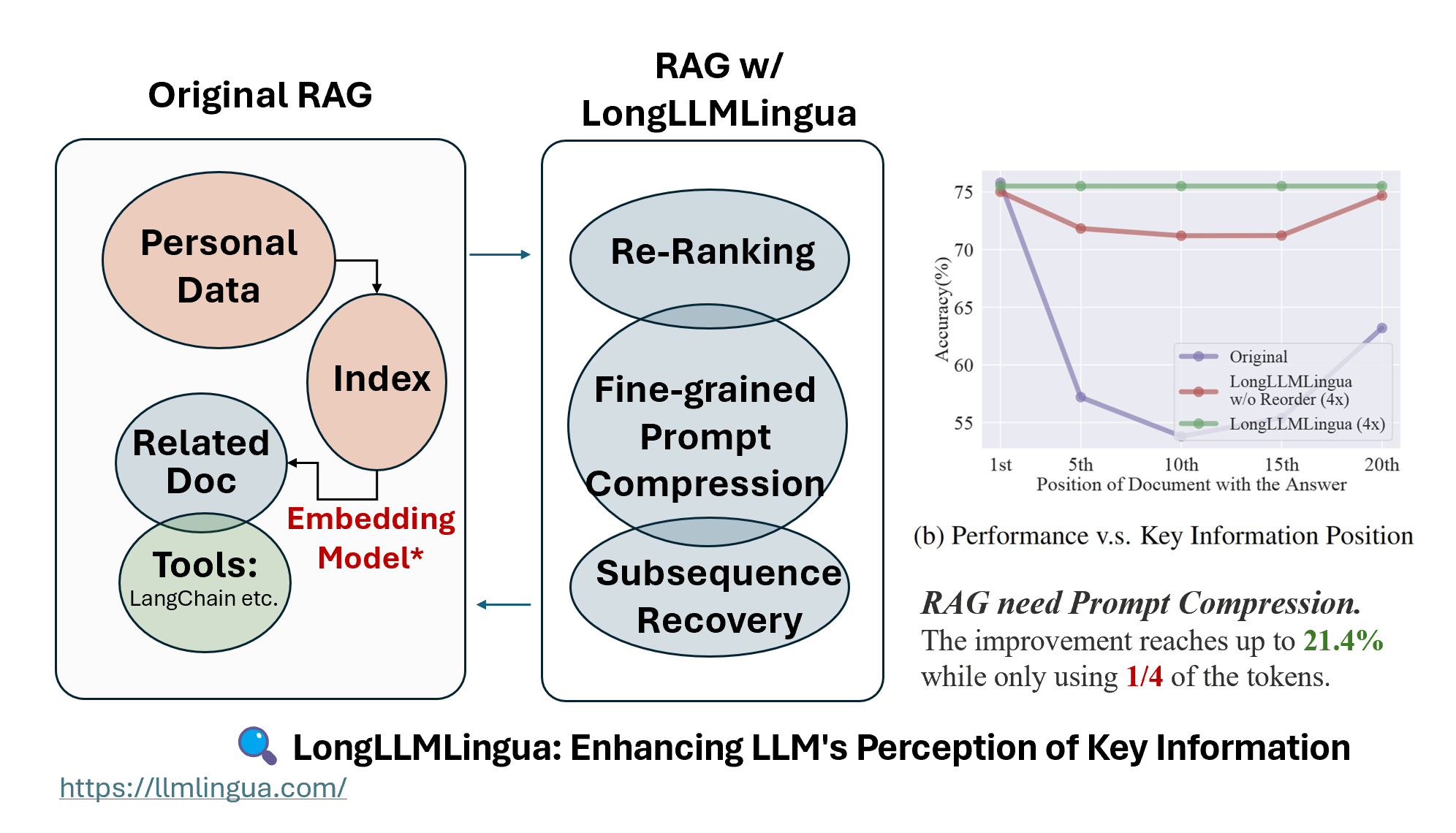
Since Coarse-grained Prompt compression far exceeds other retrieval methods in terms of accuracy, it is a very natural idea to use this ranking information to rearrange the documents that are more related to the question to the beginning and end of the prompt. However, through our testing, we found that rearranging to the beginning of the prompt is more effective than evenly distributing at both ends. So, we choose to reorder the most related document to the beginning of the prompt.
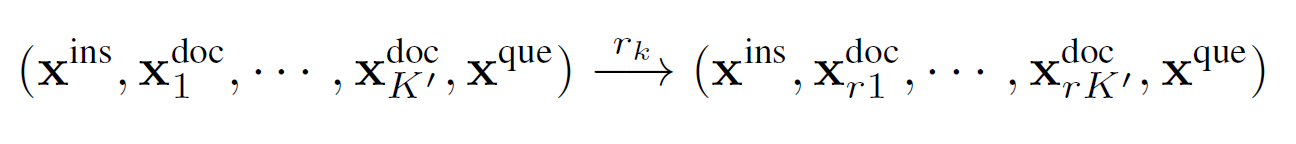
How to achieve adaptive granular control during compression?
In order to better use the information from the two grained compressions, in the fine-grained prompt compression, we dynamically allocate different compression ratios to different documents based on the rank information obtained from the coarse-grained compression, thereby preserving more important information from important documents.
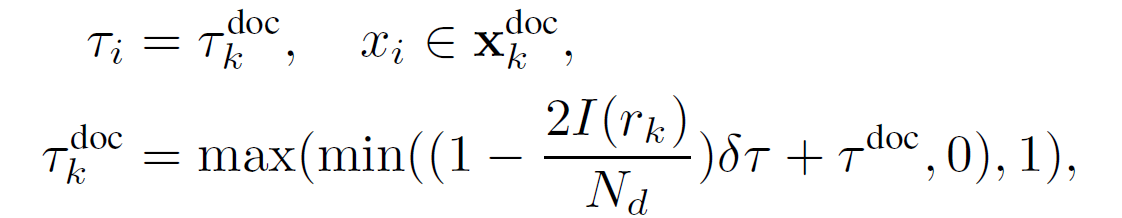
How to improve the integrity of key information?
Since LongLLMLingua is a token-level prompt compression, it will inevitably delete some tokens of the word, which may result in some retrieval-related tasks not getting complete results. But this can actually be recovered through a simple subsequence matching method. Specifically, there is a subsequence relationship between the original prompt, compressed prompt and response. By establishing the mapping relationship between the response subsequence that appears in the compressed prompt and the subsequence of the original prompt, the original prompt content can be effectively recovered.

Experiments
To evaluate the effectiveness of LongLLMLingua, we conducted detailed tests in Multi-document QA (RAG) and two long Context benchmarks. Particularly, the dataset chosen for Multi-document QA is very close to the actual RAG scenario (e.g. Bing Chat), where Contriever (one of the state-of-the-art retrieval systems) is used to recall 20 relevant documents including one ground-truth. The original documents have a high semantic relevance with the question.
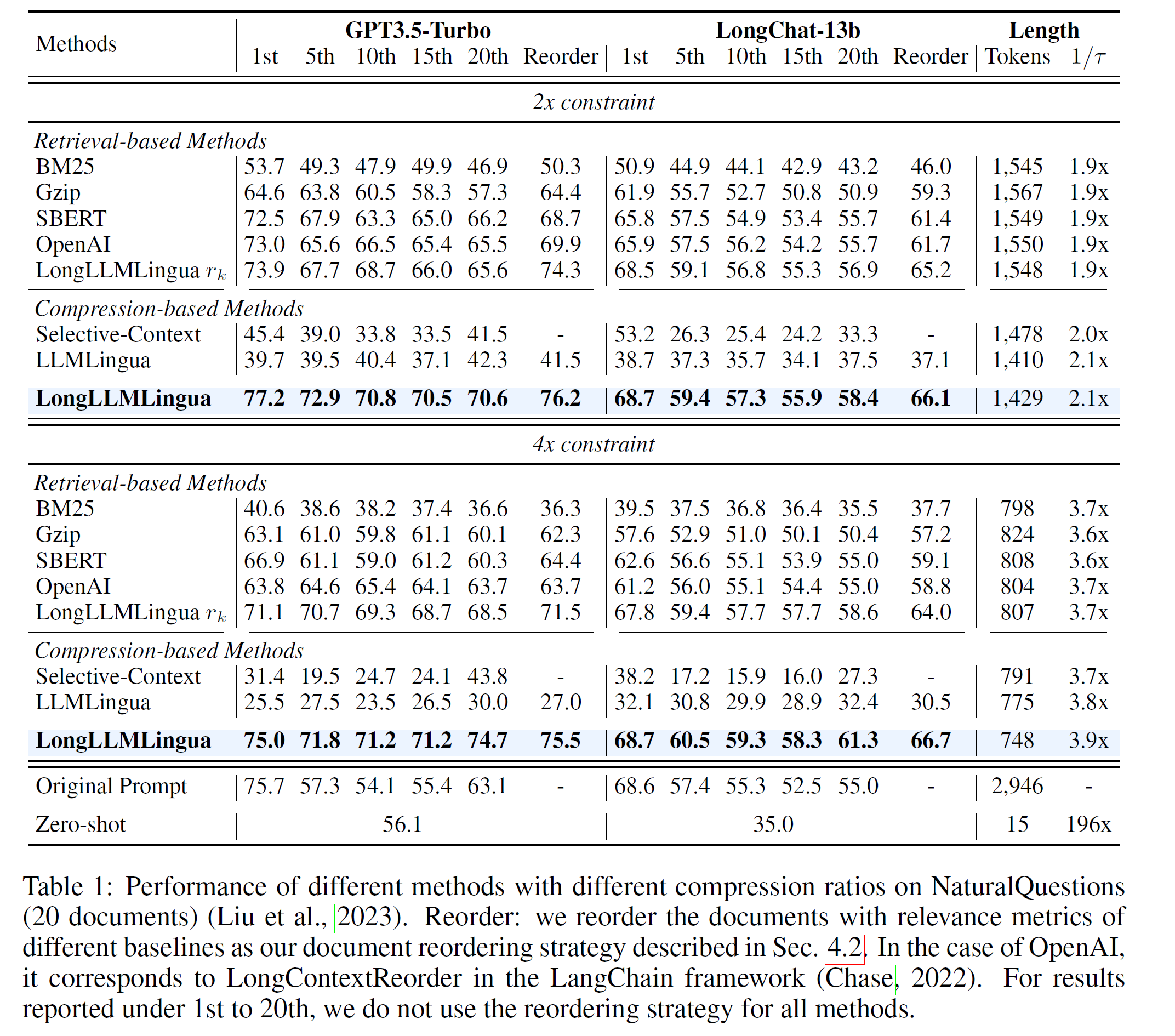
As can be seen, compared to Retrieval-based methods and compression-based methods, LongLLMLingua improves performance more in the RAG scenario, and can increase up to 21.4 points at a 4x compression rate, avoiding the original “lost in the middle” situation.
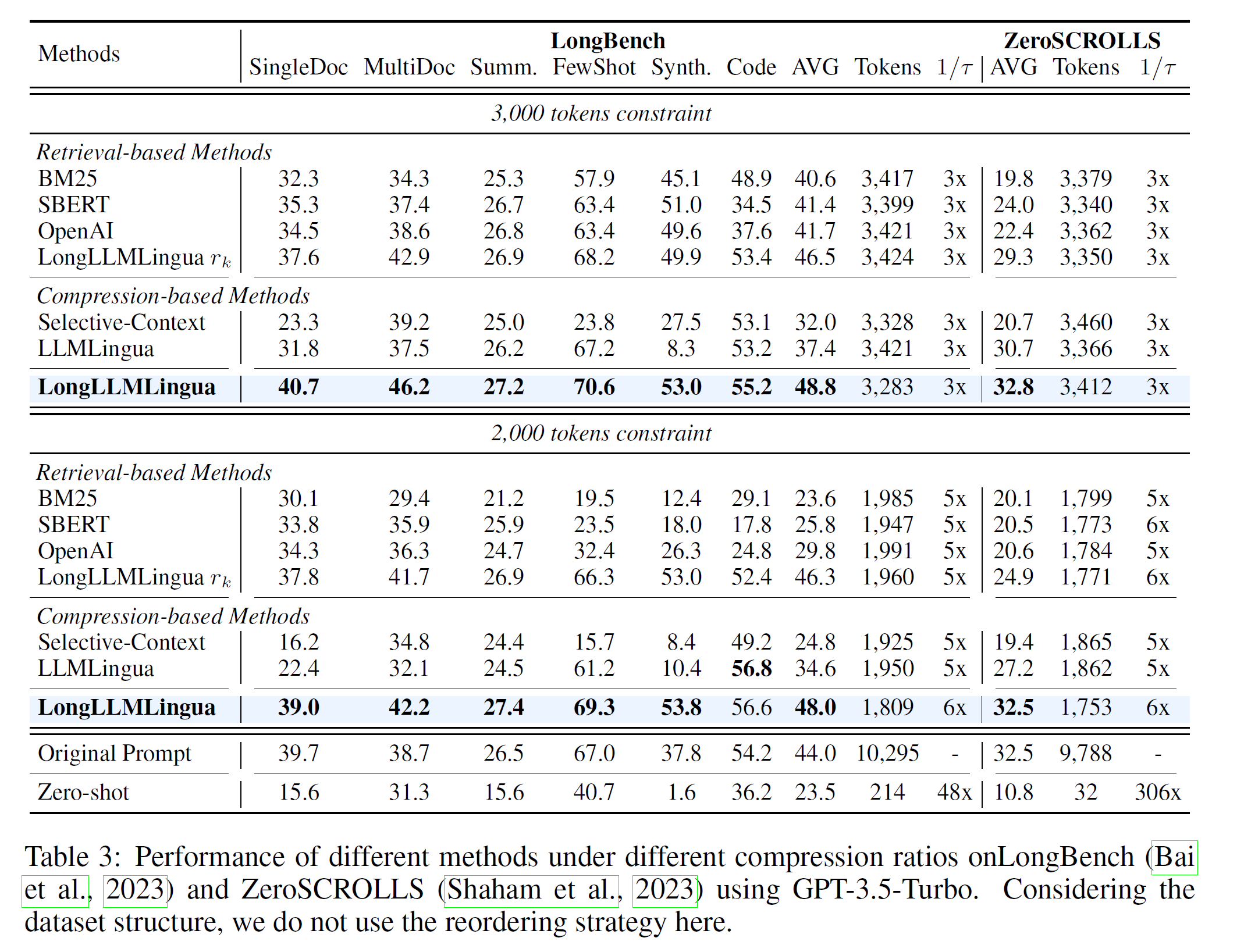
The results of the two benchmarks, LongBench and ZeroScrolls, also reached similar conclusions. LongLLMLingua is better at retaining key information related to the question in long context scenarios.
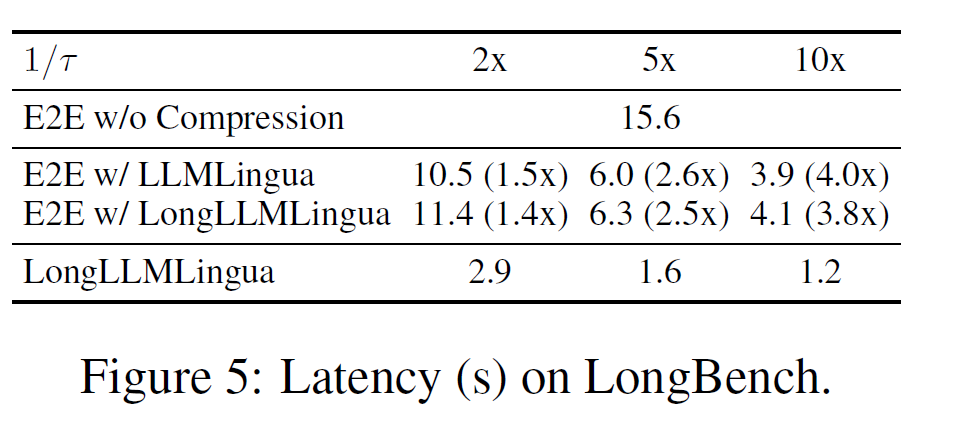
Besides, LongLLMLingua is very efficient and can speed up the end-to-end inference process.
Used in LlamaIndex
Thank Jerry Liu for your help with the LongLLMLingua project. Now you can use LongLLMLingua as a NodePostprocessor in this widely used RAG framework. For specific usage, you can refer to the example 1, example 2 and the following code.
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.response_synthesizers import CompactAndRefine
from llama_index.indices.postprocessor import LongLLMLinguaPostprocessor
node_postprocessor = LongLLMLinguaPostprocessor(
instruction_str="Given the context, please answer the final question",
target_token=300,
rank_method="longllmlingua",
additional_compress_kwargs={
"condition_compare": True,
"condition_in_question": "after",
"context_budget": "+100",
"reorder_context": "sort", # enable document reorder
"dynamic_context_compression_ratio": 0.4, # enable dynamic compression ratio
},
)References
[1] Lost in the Middle: How Language Models Use Long Contexts. Nelson F. Liu etc. [2] Compressing Context to Enhance Inference Efficiency of Large Language Models. Yucheng Li etc. [3] LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models. Huiqiang Jiang, Qianhui Wu etc. [4] RECOMP: Improving Retrieval-Augmented LMs with Compression and Selective Augmentation. Fangyuan Xu etc. [5] Retrieval meets Long Context Large Language Models. Peng Xu etc. [6] Walking Down the Memory Maze: Beyond Context Limit through Interactive Reading. Howard Chen etc.


