

Today we’re excited to introduce Llama Packs 🦙📦— a community-driven hub of prepackaged modules that you can use to kickstart your LLM application. Import them for a wide variety of use cases, from building a Streamlit app to building advanced retrieval over Weaviate to a resume parser that does structured data extraction. Just as important, inspect and customize them to your liking.
They’re available on LlamaHub: we’ve launched 16+ templates with our launch partners already, and we’re going to be adding a lot more!
(To those of you in the states, Happy Thanksgiving 🦃)
Context
There are so many choices when building an LLM app that it can be daunting to get started building for a specific use case. Even for RAG the user needs to make the following decisions:
- Which LLM should I use? Embedding model?
- Vector database?
- Chunking/parsing strategy
- Retrieval Algorithm
- Wrapping in surrounding application
Every use case requires different parameters, and LlamaIndex as a core LLM framework offers a comprehensive set of unopinionated modules to let users compose an application.
But we needed a way for users to get started more easily for their use case. And that’s exactly where Llama Packs comes in.
Overview
Llama Packs can be described in two ways:
- On one hand, they are prepackaged modules that can be initialized with parameters and run out of the box to achieve a given use case (whether that’s a full RAG pipeline, application template, and more). You can also import submodules (e.g. LLMs, query engines) to use directly.
- On another hand, LlamaPacks are templates that you can inspect, modify, and use.
They can be downloaded either through our llama_index Python library or the CLI in one line of code:
CLI:
llamaindex-cli download-llamapack <pack_name> --download-dir <pack_directory>Python
from llama_index.llama_pack import download_llama_pack
# download and install dependencies
VoyageQueryEnginePack = download_llama_pack(
"<pack_name>", "<pack_directory>"
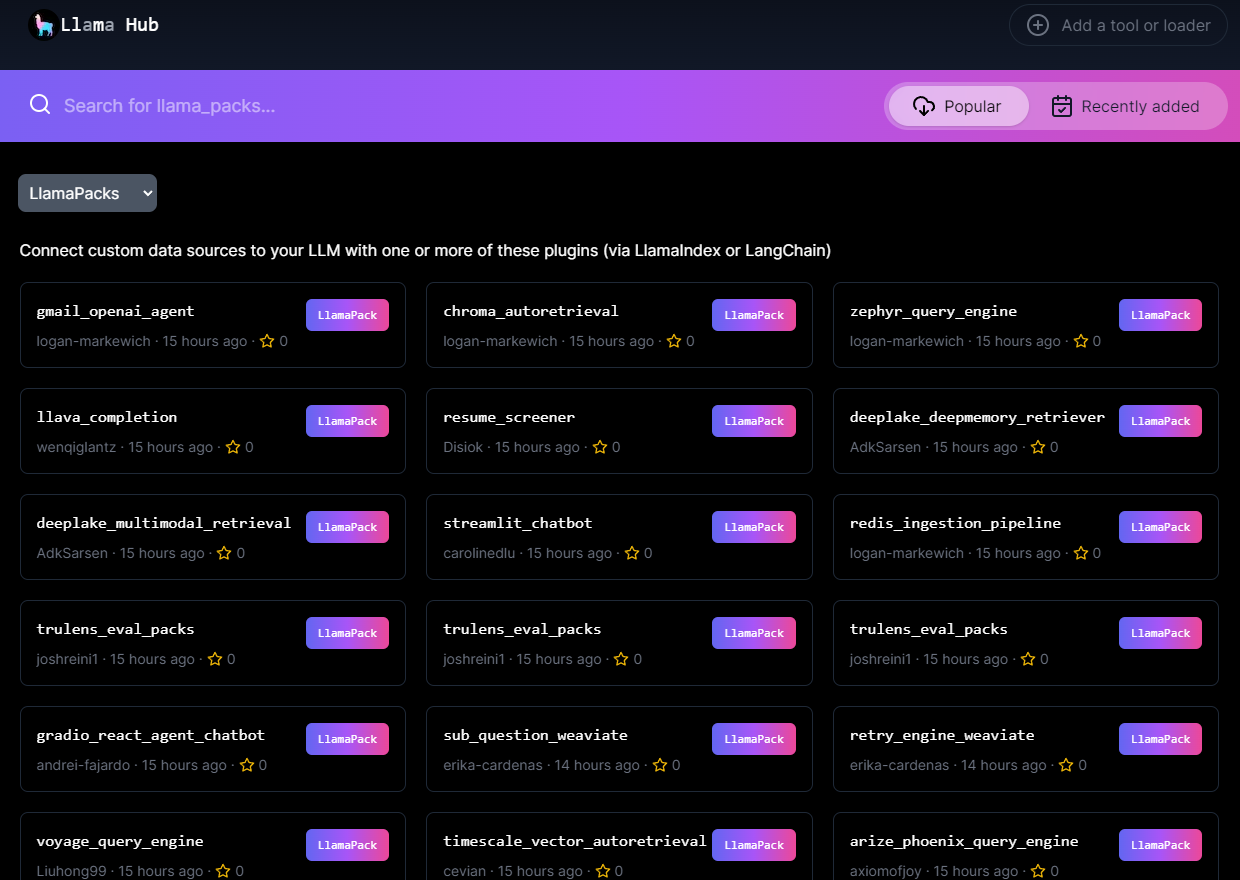
)Llama Packs can span abstraction levels — some are full prepackaged templates (full Streamlit / Gradio apps), and some combine a few smaller modules together (e.g. our SubQuestionQueryEngine with Weaviate). All of them are found in LlamaHub 👇. You can filter by packs by selecting “Llama Packs” from the dropdown.
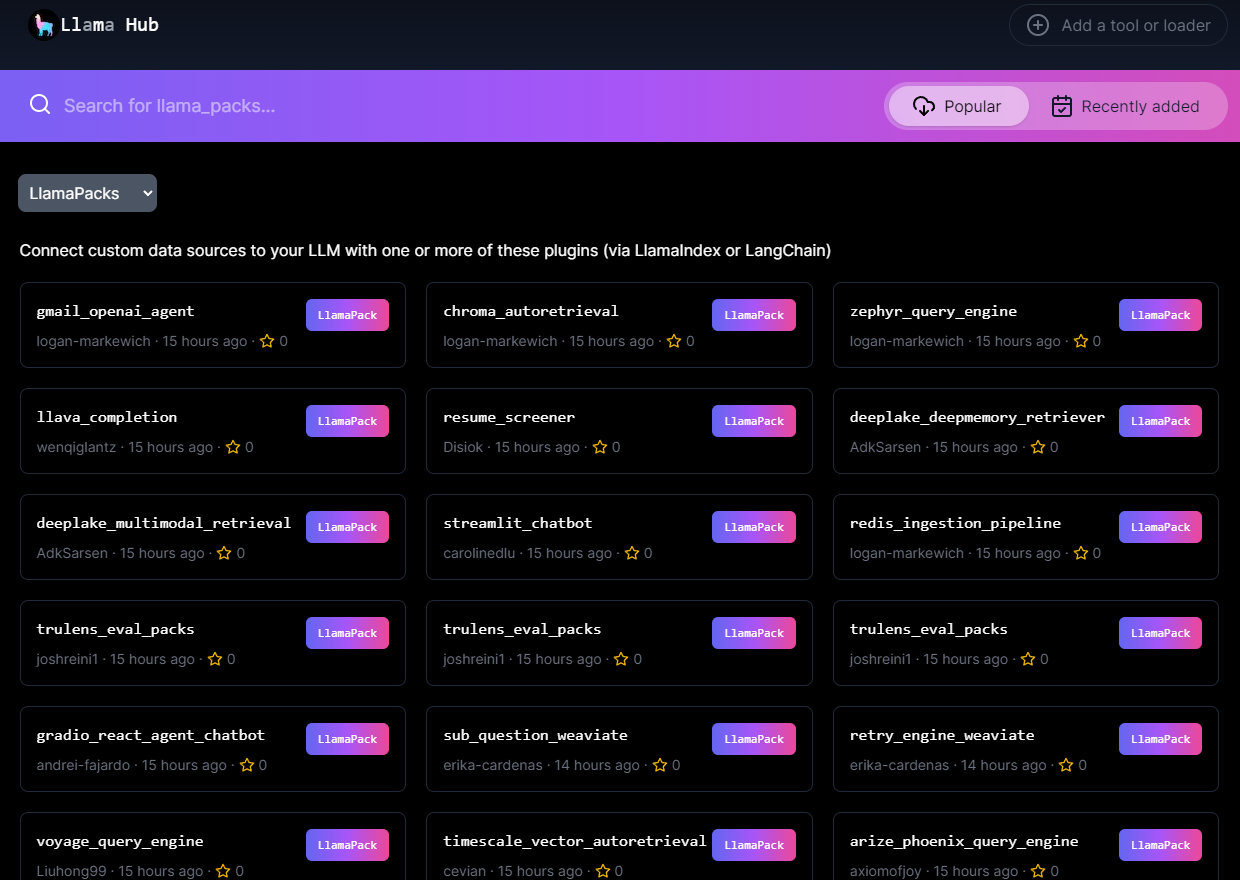
We’re excited to partner with the following companies/contributors for our launch, featuring 16+ templates. We highlight some examples below:
- Streamlit / Snowflake (Caroline F.): Streamlit Chatbot
- Arize (Mikyo K., Xander S.): Arize Phoenix
- ActiveLoop / DeepLake (Mikayel H., Adhilkhan S.): DeepMemory Pack, Multi-modal Retrieval
- Weaviate (Erika C.): Sub Question Query Engine, Retry Query Engine
- Voyage AI (Hong L.): Voyage AI Pack
- TruEra (Josh R.): TruLens Eval Pack (this is 3 packs in one)
- Timescale (Matvey A.): Timescale Vector AutoRetrieval
- Wenqi G.: LLaVa Completion Pack
There’s not enough room in this blog post to feature every template, we’ll be running features on every pack in the next few days.
Special thanks to Logan Markewich and Andrei Fajardo on the LlamaIndex team for getting Llama Packs up and running.
Example Walkthrough
The best way to highlight LlamaPack features is to showcase an example. We’ll walk through a simple Llama Pack that gives the user a RAG pipeline setup with Voyage AI embeddings.
First, we download and initialize the Pack over a set of documents:
from llama_index.llama_pack import download_llama_pack
# download pack
VoyageQueryEnginePack = download_llama_pack("VoyageQueryEnginePack", "./voyage_pack")
# initialize pack (assume documents is defined)
voyage_pack = VoyageQueryEnginePack(documents)Every Llama Pack implements a get_modules() function allowing you to inspect/use the modules.
modules = voyage_pack.get_modules()
display(modules)
# get LLM, vector index
llm = modules["llm"]
vector_index = modules["index"]The Llama Pack can be run in an out of the box fashion. By calling run , we’ll execute the RAG pipeline and get back a response. In this setting, you don’t need to worry about the internals.
# this will run the full pack
response = voyage_pack.run("What did the author do growing up?", similarity_top_k=2)
print(str(response))
The author spent his time outside of school mainly writing and programming. He wrote short stories and attempted to write programs on an IBM 1401. Later, he started programming on a TRS-80, creating simple games and a word processor. He also painted still lives while studying at the Accademia.The second important thing is that you have full access to the code of the Llama Pack. This allows you to customize the Llama Pack, rip out code, or just use it as reference to build your own app. Let’s take a look at the downloaded pack in voyage_pack/base.py , and swap out the OpenAI LLM for Anthropic:
from llama_index.llms import Anthropic
...
class VoyageQueryEnginePack(BaseLlamaPack):
def __init__(self, documents: List[Document]) -> None:
llm = Anthropic()
embed_model = VoyageEmbedding(
model_name="voyage-01", voyage_api_key=os.environ["VOYAGE_API_KEY"]
)
service_context = ServiceContext.from_defaults(llm=llm, embed_model=embed_model)
self.llm = llm
self.index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
def get_modules(self) -> Dict[str, Any]:
"""Get modules."""
return {"llm": self.llm, "index": self.index}
def run(self, query_str: str, **kwargs: Any) -> Any:
"""Run the pipeline."""
query_engine = self.index.as_query_engine(**kwargs)
return query_engine.query(query_str)You can re-import the module directly and run it again:
from voyage_pack.base import VoyageQueryEnginePack
voyage_pack = VoyageQueryEnginePack(documents)
response = voyage_pack.run("What did the author do during his time in RISD?")
print(str(response))Conclusion
Try it out and let us know what you think!
Contributing
Not on here yet? We’d love to feature you! If you have any templates with LlamaIndex, adding it is almost as simple as copying/pasting your existing code over into aBaseLlamaPack subclass. Take a look at this folder for a full set of examples: https://github.com/run-llama/llama-hub/tree/main/llama_hub/llama_packs
Resources
All Llama Packs can be found on LlamaHub: https://llamahub.ai/
The full notebook walkthrough is here: https://github.com/run-llama/llama_index/blob/main/docs/examples/llama_hub/llama_packs_example.ipynb


