

Co-authors: Jerry Liu (CEO at LlamaIndex), Amog Kamsetty (Software Engineer at Anyscale)
(note: this is cross-posted from the original blog post on Anyscale’s website. Check it out here!)
In this blog, we showcase how you can use LlamaIndex and Ray to build a query engine to answer questions and generate insights about Ray itself, given its documentation and blog posts.
We’ll give a quick introduction of LlamaIndex + Ray, and then walk through a step-by-step tutorial on building and deploying this query engine. We make use of both Ray Datasets to parallelize building indices as well as Ray Serve to build deployments.
Introduction
Large Language Models (LLMs) offer the promise of allowing users to extract complex insights from their unstructured text data. Retrieval-augmented generation pipelines have emerged as a common pattern for developing LLM applications allowing users to effectively perform semantic search over a collection of documents.
However, when productionizing these applications over many different data sources, there are a few challenges:
- Tooling for indexing data from many different data sources
- Handling complex queries over different data sources
- Scaling indexing to thousands or millions of documents
- Deploying a scalable LLM application into production
Here, we showcase how LlamaIndex and Ray are the perfect setup for this task.
LlamaIndex is a data framework for building LLM applications, and solves Challenges #1 and #2. It also provides a comprehensive toolkit allowing users to connect their private data with a language model. It offers a variety of tools to help users first ingest and index their data — convert different formats of unstructured and structured data into a format that the language model can use, and query their private data.
Ray is a powerful framework for scalable AI that solves Challenges #3 and #4. We can use it to dramatically accelerate ingest, inference, pretraining, and also effortlessly deploy and scale the query capabilities of LlamaIndex into the cloud.
More specifically, we showcase a very relevant use case — highlighting Ray features that are present in both the documentation as well as the Ray blog posts!
Data Ingestion and Embedding Pipeline
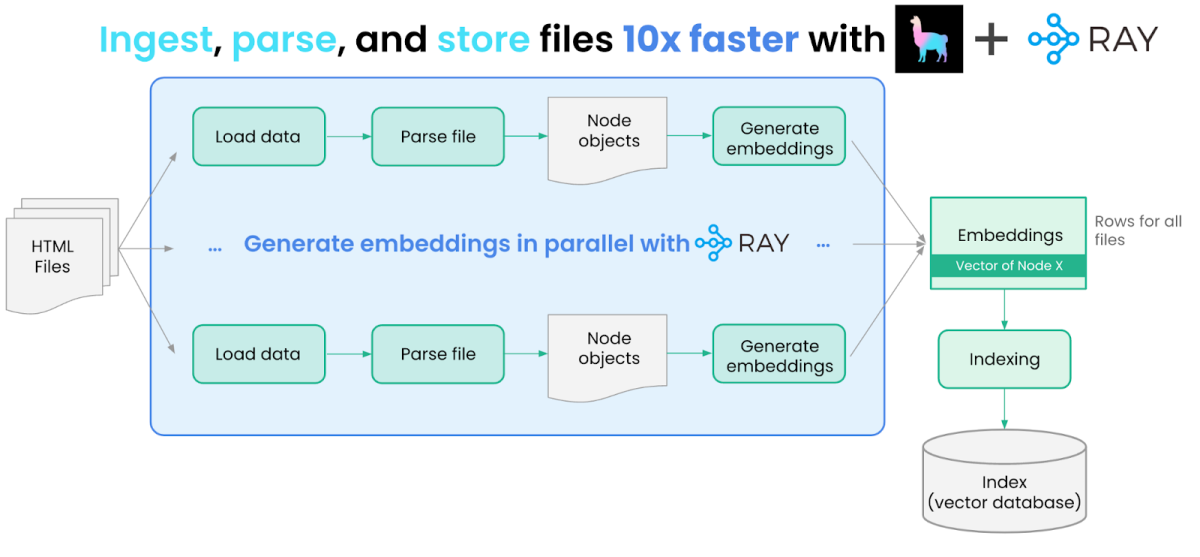
We use LlamaIndex + Ray to ingest, parse, embed and store Ray docs and blog posts in a parallel fashion. For the most part, these steps are duplicated across the two data sources, so we show the steps for just the documentation below.
Code for this part of the blog is available here.
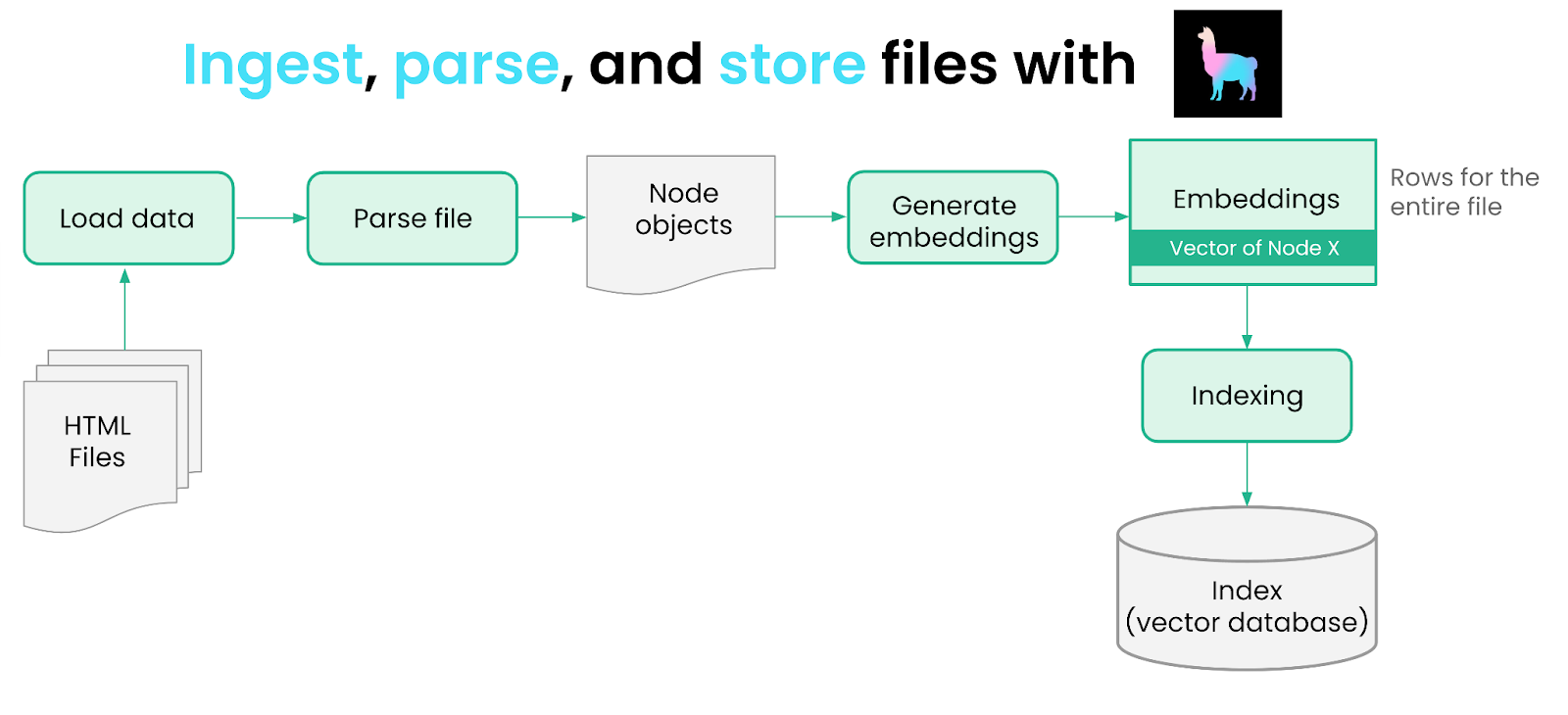
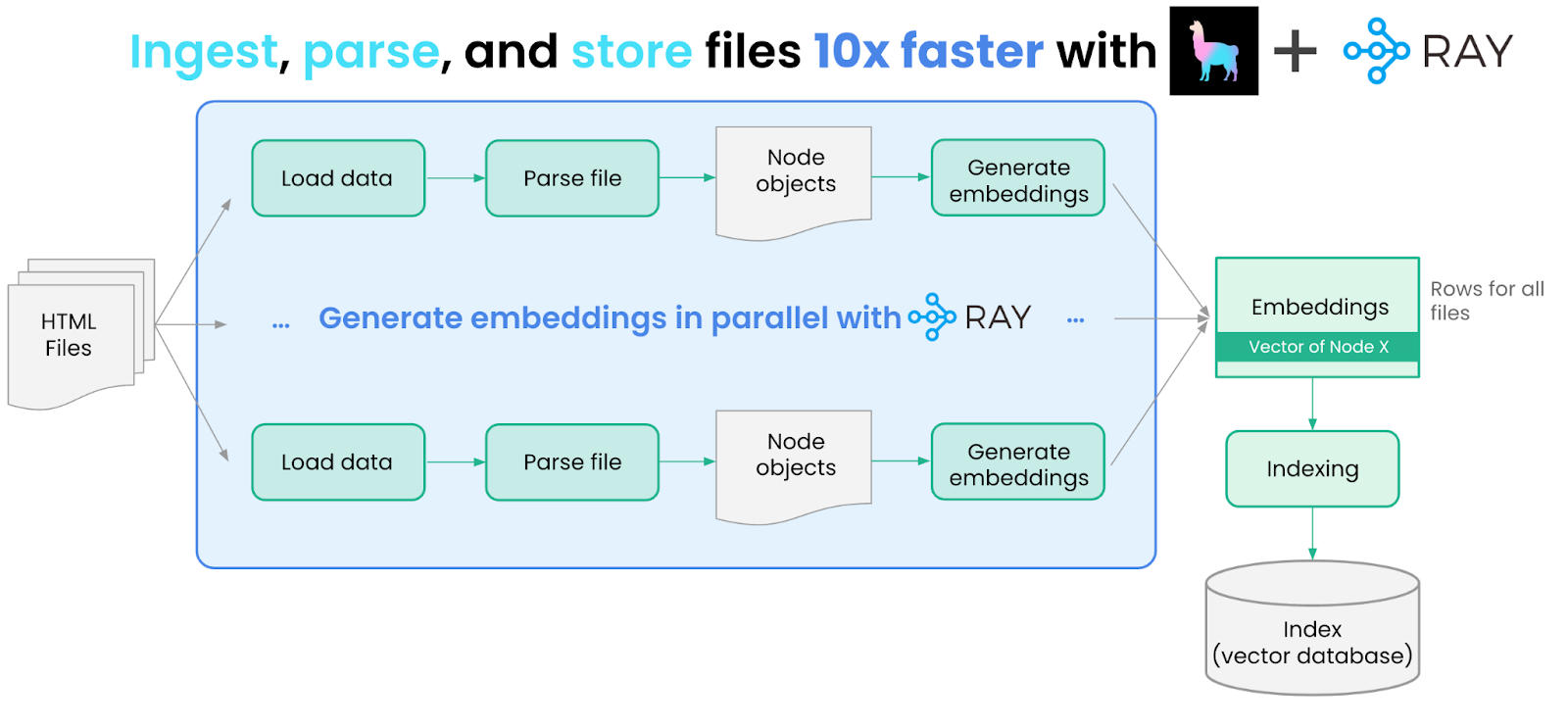
Load Data
We start by ingesting these two sources of data. We first fetch both data sources and download the HTML files.
We then need to load and parse these files. We can do this with the help of LlamaHub, our community-driven repository of 100+ data loaders from various API’s, file formats (.pdf, .html, .docx), and databases. We use an HTML data loader offered by Unstructured.
from typing import Dict, List
from pathlib import Path
from llama_index import download_loader
from llama_index import Document
# Step 1: Logic for loading and parsing the files into llama_index documents.
UnstructuredReader = download_loader("UnstructuredReader")
loader = UnstructuredReader()
def load_and_parse_files(file_row: Dict[str, Path]) -> Dict[str, Document]:
documents = []
file = file_row["path"]
if file.is_dir():
return []
# Skip all non-html files like png, jpg, etc.
if file.suffix.lower() == ".html":
loaded_doc = loader.load_data(file=file, split_documents=False)
loaded_doc[0].extra_info = {"path": str(file)}
documents.extend(loaded_doc)
return [{"doc": doc} for doc in documents]Unstructured offers a robust suite of parsing tools on top of various files. It is able to help sanitize HTML documents by stripping out information like tags and formatting the text accordingly.
Scaling Data Ingest
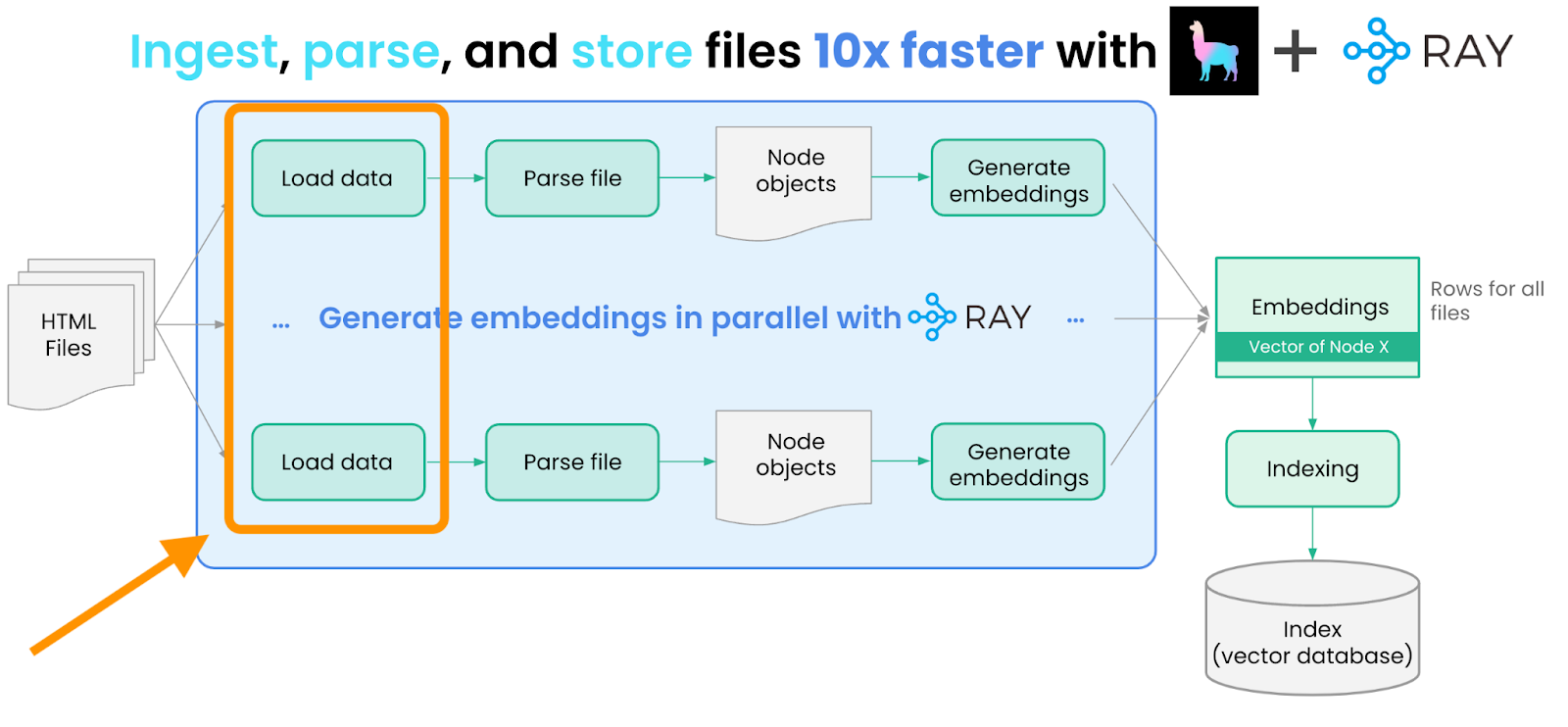
Since we have many HTML documents to process, loading/processing each one serially is inefficient and slow. This is an opportunity to use Ray and distribute execution of the `load_and_parse_files` method across multiple CPUs or GPUs.
import ray
# Get the paths for the locally downloaded documentation.
all_docs_gen = Path("./docs.ray.io/").rglob("*")
all_docs = [{"path": doc.resolve()} for doc in all_docs_gen]
# Create the Ray Dataset pipeline
ds = ray.data.from_items(all_docs)
# Use `flat_map` since there is a 1:N relationship.
# Each filepath returns multiple documents.
loaded_docs = ds.flat_map(load_and_parse_files)Parse Files
Now that we’ve loaded the documents, the next step is to parse them into Node objects — a “Node” object represents a more granular chunk of text, derived from the source documents. Node objects can be used in the input prompt as context; by setting a small enough chunk size, we can make sure that inserting Node objects do not overflow the context limits.
We define a function called `convert_documents_into_nodes` which converts documents into nodes using a simple text splitting strategy.
# Step 2: Convert the loaded documents into llama_index Nodes. This will split the documents into chunks.
from llama_index.node_parser import SimpleNodeParser
from llama_index.data_structs import Node
def convert_documents_into_nodes(documents: Dict[str, Document]) -> Dict[str, Node]:
parser = SimpleNodeParser()
document = documents["doc"]
nodes = parser.get_nodes_from_documents([document])
return [{"node": node} for node in nodes]Run Parsing in Parallel
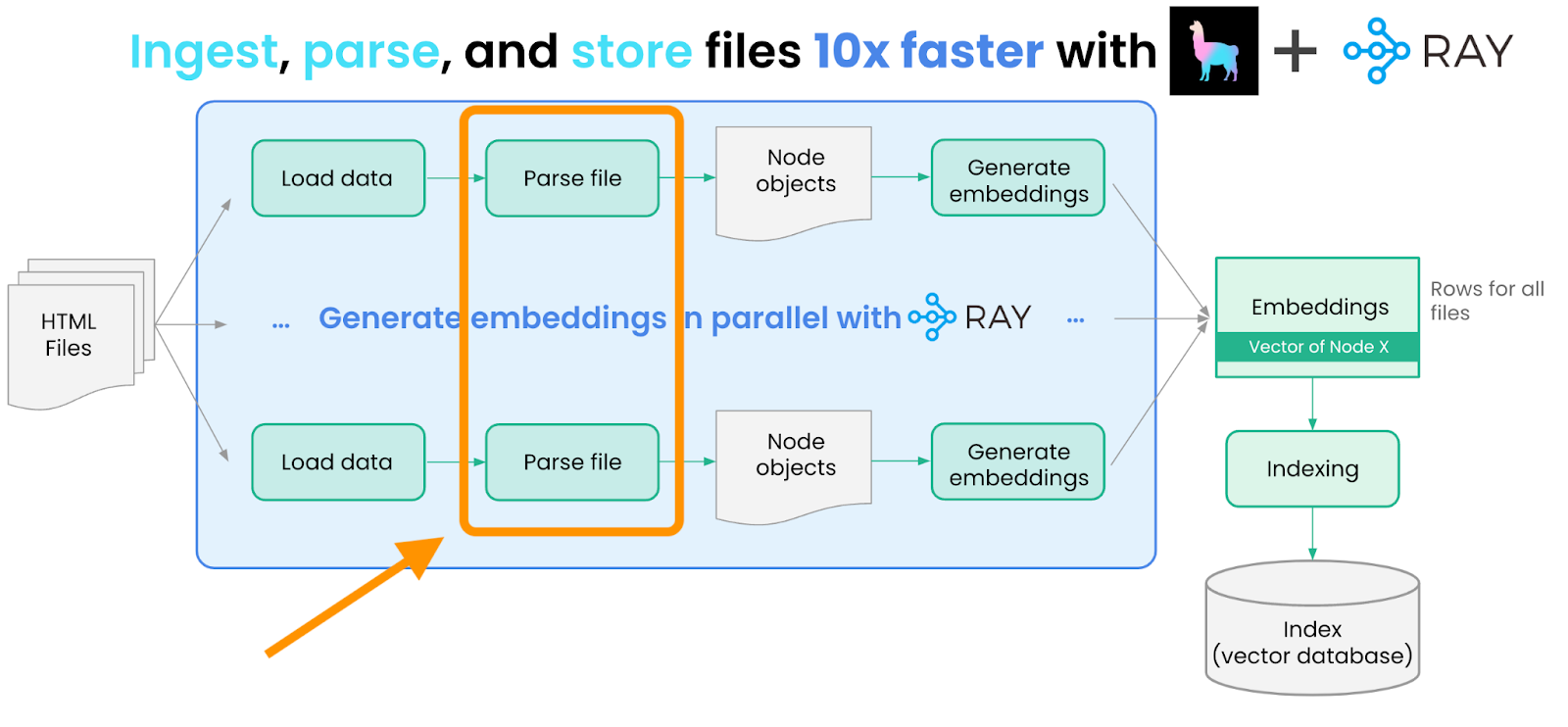
Since we have many documents, processing each document into nodes serially is inefficient and slow. We use Ray `flat_map` method to process documents into nodes in parallel:
# Use `flat_map` since there is a 1:N relationship. Each document returns multiple nodes.
nodes = loaded_docs.flat_map(convert_documents_into_nodes)Generate Embeddings
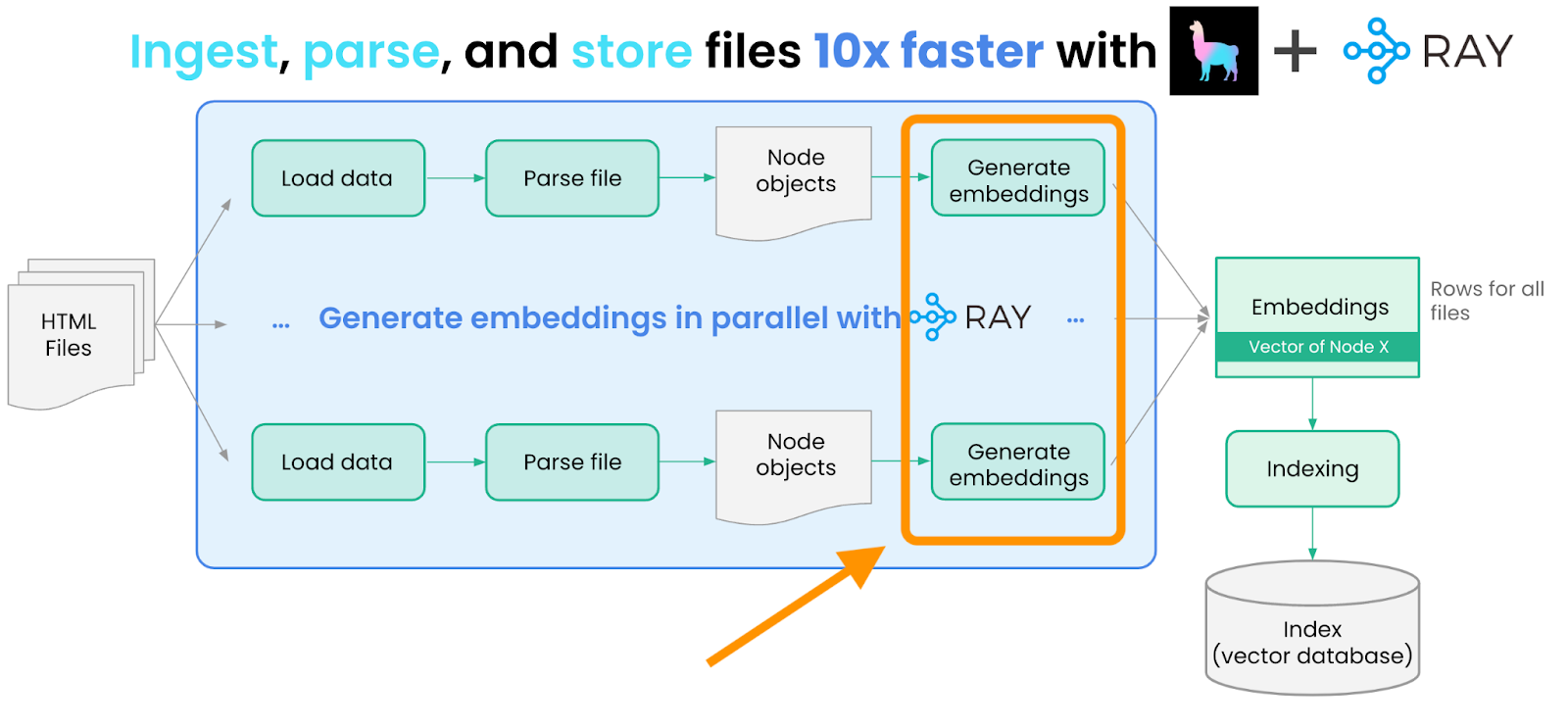
We then generate embeddings for each Node using a Hugging Face Sentence Transformers model. We can do this with the help of LangChain’s embedding abstraction.
Similar to document loading/parsing, embedding generation can similarly be parallelized with Ray. We wrap these embedding operations into a helper class, called `EmbedNodes`, to take advantage of Ray abstractions.
# Step 3: Embed each node using a local embedding model.
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
class EmbedNodes:
def __init__(self):
self.embedding_model = HuggingFaceEmbeddings(
# Use all-mpnet-base-v2 Sentence_transformer.
# This is the default embedding model for LlamaIndex/Langchain.
model_name="sentence-transformers/all-mpnet-base-v2",
model_kwargs={"device": "cuda"},
# Use GPU for embedding and specify a large enough batch size to maximize GPU utilization.
# Remove the "device": "cuda" to use CPU instead.
encode_kwargs={"device": "cuda", "batch_size": 100}
)
def __call__(self, node_batch: Dict[str, List[Node]]) -> Dict[str, List[Node]]:
nodes = node_batch["node"]
text = [node.text for node in nodes]
embeddings = self.embedding_model.embed_documents(text)
assert len(nodes) == len(embeddings)
for node, embedding in zip(nodes, embeddings):
node.embedding = embedding
return {"embedded_nodes": nodes}Afterwards, generating an embedding for each node is as simple as calling the following operation in Ray:
# Use `map_batches` to specify a batch size to maximize GPU utilization.
# We define `EmbedNodes` as a class instead of a function so we only initialize the embedding model once.
# This state can be reused for multiple batches.
embedded_nodes = nodes.map_batches(
EmbedNodes,
batch_size=100,
# Use 1 GPU per actor.
num_gpus=1,
# There are 4 GPUs in the cluster. Each actor uses 1 GPU. So we want 4 total actors.
compute=ActorPoolStrategy(size=4))
# Step 5: Trigger execution and collect all the embedded nodes.
ray_docs_nodes = []
for row in embedded_nodes.iter_rows():
node = row["embedded_nodes"]
assert node.embedding is not None
ray_docs_nodes.append(node)Data Indexing
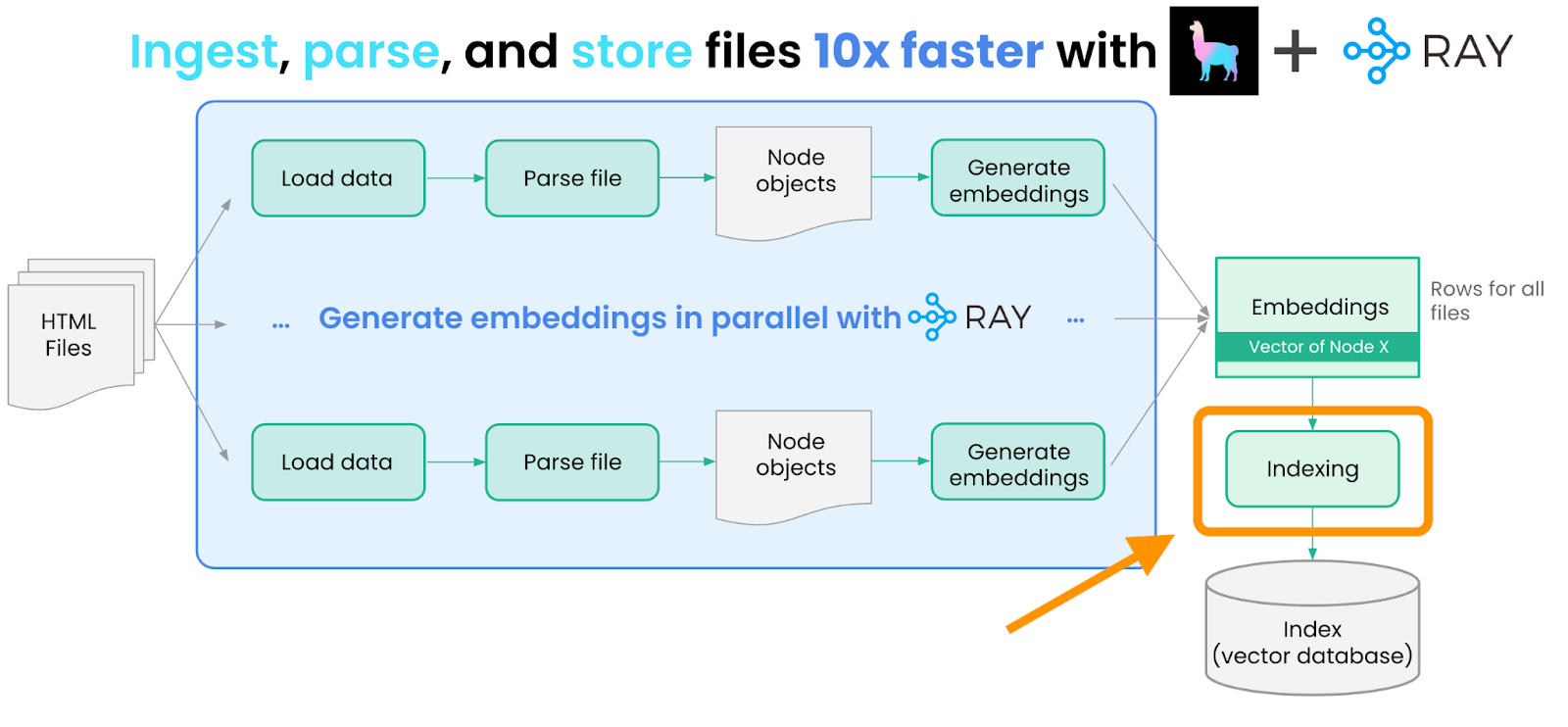
The next step is to store these nodes within an “index” in LlamaIndex. An index is a core abstraction in LlamaIndex to “structure” your data in a certain way — this structure can then be used for downstream LLM retrieval + querying. An index can interface with a storage or vector store abstraction.
The most commonly used index abstraction within LlamaIndex is our vector index, where each node is stored along with an embedding. In this example, we use a simple in-memory vector store, but you can also choose to specify any one of LlamaIndex’s 10+ vector store integrations as the storage provider (e.g. Pinecone, Weaviate, Chroma).
We build two vector indices: one over the documentation nodes, and another over the blog post nodes and persist them to disk. Code is available here.
from llama_index import GPTVectorStoreIndex
# Store Ray Documentation embeddings
ray_docs_index = GPTVectorStoreIndex(nodes=ray_docs_nodes)
ray_docs_index.storage_context.persist(persist_dir="/tmp/ray_docs_index")
# Store Anyscale blog post embeddings
ray_blogs_index = GPTVectorStoreIndex(nodes=ray_blogs_nodes)
ray_blogs_index.storage_context.persist(persist_dir="/tmp/ray_blogs_index")That’s it in terms of building a data pipeline using LlamaIndex + Ray Data!
Your data is now ready to be used within your LLM application. Check out our next section for how to use advanced LlamaIndex query capabilities on top of your data.
Data Querying
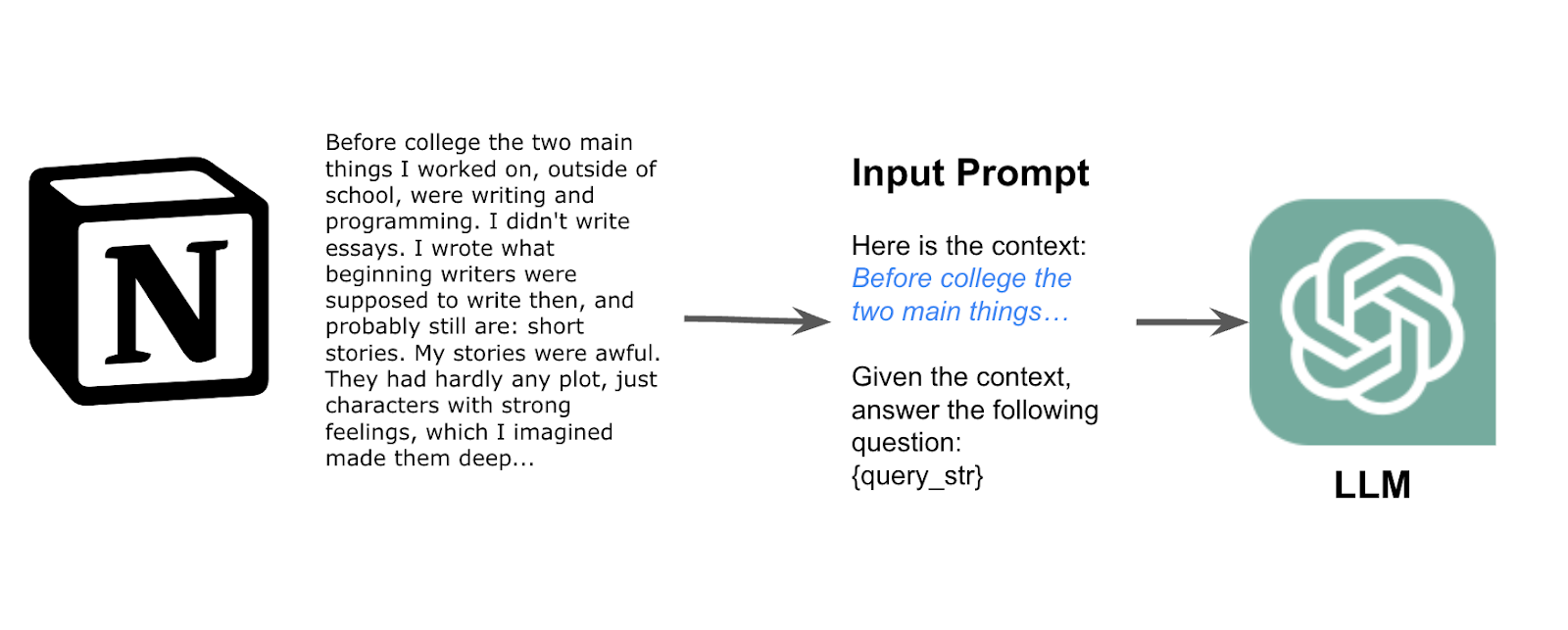
LlamaIndex provides both simple and advanced query capabilities on top of your data + indices. The central abstraction within LlamaIndex is called a “query engine.” A query engine takes in a natural language query input and returns a natural language “output”. Each index has a “default” corresponding query engine. For instance, the default query engine for a vector index first performs top-k retrieval over the vector store to fetch the most relevant documents.
These query engines can be easily derived from each index:
ray_docs_engine = ray_docs_index.as_query_engine(similarity_top_k=5, service_context=service_context)
ray_blogs_engine = ray_blogs_index.as_query_engine(similarity_top_k=5, service_context=service_context)LlamaIndex also provides more advanced query engines for multi-document use cases — for instance, we may want to ask how a given feature in Ray is highlighted in both the documentation and blog. `SubQuestionQueryEngine` can take in other query engines as input. Given an existing question, it can decide to break down the question into simpler questions over any subset of query engines; it will execute the simpler questions and combine results at the top-level.
This abstraction is quite powerful; it can perform semantic search over one document, or combine results across multiple documents.
For instance, given the following question “What is Ray?”, we can break this into sub-questions “What is Ray according to the documentation”, and “What is Ray according to the blog posts” over the document query engine and blog query engine respectively.
# Define a sub-question query engine, that can use the individual query engines as tools.
query_engine_tools = [
QueryEngineTool(
query_engine=self.ray_docs_engine,
metadata=ToolMetadata(name="ray_docs_engine", description="Provides information about the Ray documentation")
),
QueryEngineTool(
query_engine=self.ray_blogs_engine,
metadata=ToolMetadata(name="ray_blogs_engine", description="Provides information about Ray blog posts")
),
]
sub_query_engine = SubQuestionQueryEngine.from_defaults(query_engine_tools=query_engine_tools, service_context=service_context, use_async=False)Have a look at deploy_app.py to review the full implementation.
Deploying with Ray Serve
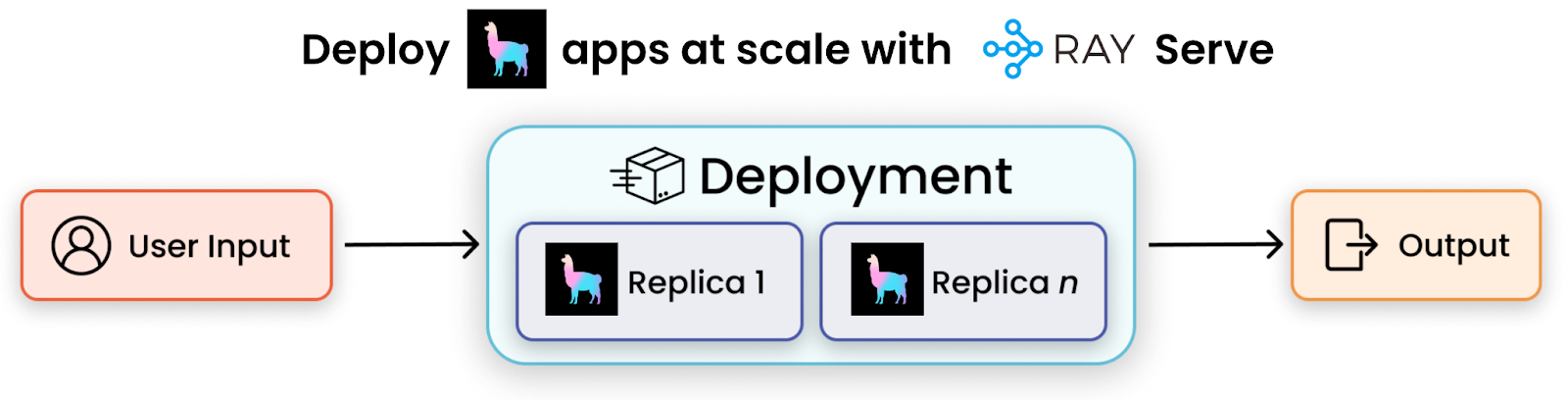
We’ve now created an incredibly powerful query module over your data. As a next step, what if we could seamlessly deploy this function to production and serve users? Ray Serve makes this incredibly easy to do. Ray Serve is a scalable compute layer for serving ML models and LLMs that enables serving individual models or creating composite model pipelines where you can independently deploy, update, and scale individual components.
To do this, you just need to do the following steps:
- Define an outer class that can “wrap” a query engine, and expose a “query” endpoint
- Add a `@ray.serve.deployment` decorator on this class
- Deploy the Ray Serve application
It will look something like the following:
from ray import serve
@serve.deployment
class QADeployment:
def __init__(self):
self.query_engine = ...
def query(self, query: str):
response = self.query_engine.query(query)
source_nodes = response.source_nodes
source_str = ""
for i in range(len(source_nodes)):
node = source_nodes[i]
source_str += f"Sub-question {i+1}:\n"
source_str += node.node.text
source_str += "\n\n"
return f"Response: {str(response)} \n\n\n {source_str}\n"
async def __call__(self, request: Request):
query = request.query_params["query"]
return str(self.query(query))
# Deploy the Ray Serve application.
deployment = QADeployment.bind()Have a look at the deploy_app.py for full implementation.
Example Queries
Once we’ve deployed the application, we can query it with questions about Ray.
We can query just one of the data sources:
Q: "What is Ray Serve?"
Ray Serve is a system for deploying and managing applications on a Ray
cluster. It provides APIs for deploying applications, managing replicas, and
making requests to applications. It also provides a command line interface
(CLI) for managing applications and a dashboard for monitoring applications.But, we can also provide complex queries that require synthesis across both the documentation and the blog posts. These complex queries are easily handled by the subquestion-query engine that we defined.
Q: "Compare and contrast how the Ray docs and the Ray blogs present Ray Serve"
Response:
The Ray docs and the Ray blogs both present Ray Serve as a web interface
that provides metrics, charts, and other features to help Ray users
understand and debug Ray applications. However, the Ray docs provide more
detailed information, such as a Quick Start guide, user guide, production
guide, performance tuning guide, development workflow guide, API reference,
experimental Java API, and experimental gRPC support. Additionally, the Ray
docs provide a guide for migrating from 1.x to 2.x. On the other hand, the
Ray blogs provide a Quick Start guide, a User Guide, and Advanced Guides to
help users get started and understand the features of Ray Serve.
Additionally, the Ray blogs provide examples and use cases to help users
understand how to use Ray Serve in their own projects.
---
Sub-question 1
Sub question: How does the Ray docs present Ray Serve
Response:
The Ray docs present Ray Serve as a web interface that provides metrics,
charts, and other features to help Ray users understand and debug Ray
applications. It provides a Quick Start guide, user guide, production guide,
performance tuning guide, and development workflow guide. It also provides
an API reference, experimental Java API, and experimental gRPC support.
Finally, it provides a guide for migrating from 1.x to 2.x.
---
Sub-question 2
Sub question: How does the Ray blogs present Ray Serve
Response:
The Ray blog presents Ray Serve as a framework for distributed applications
that enables users to handle HTTP requests, scale and allocate resources,
compose models, and more. It provides a Quick Start guide, a User Guide, and
Advanced Guides to help users get started and understand the features of Ray
Serve. Additionally, it provides examples and use cases to help users
understand how to use Ray Serve in their own projects.Conclusion
In this example, we showed how you can build a scalable data pipeline and a powerful query engine using LlamaIndex + Ray. We also demonstrated how to deploy LlamaIndex applications using Ray Serve. This allows you to effortlessly ask questions and synthesize insights about Ray across disparate data sources!
We used LlamaIndex — a data framework for building LLM applications — to load, parse, embed and index the data. We ensured efficient and fast parallel execution by using Ray. Then, we used LlamaIndex querying capabilities to perform semantic search over a single document, or combine results across multiple documents. Finally, we used Ray Serve to package the application for production use.
Implementation in open source, code is available on GitHub: LlamaIndex-Ray-app
What’s next?
Visit LlamaIndex site and docs to learn more about this data framework for building LLM applications.
Visit Ray docs to learn more about how to build and deploy scalable LLM apps.
Join our communities!
- Join Ray community on Slack and Ray #LLM channel.
- You can also join the LlamaIndex community on discord.
We have our Ray Summit 2023 early-bird registration open until 6/30. Secure your spot, save some money, savor the community camaraderie at the summit.


