This is a guest post from Team CLAB, the winners of "Best Use of LlamaIndex" at our recent hackathon with MongoDB.
Imagine this: you’re deep in a coding project, and a critical question pops up about a specific tool or library. You start the dreaded documentation shuffle — searching through wikis, FAQs, maybe even firing up a separate chatbot for specific tools (like those from LlamaIndex, FireworksAI or anyone else). It’s frustrating! 🤯 We wanted to change that.
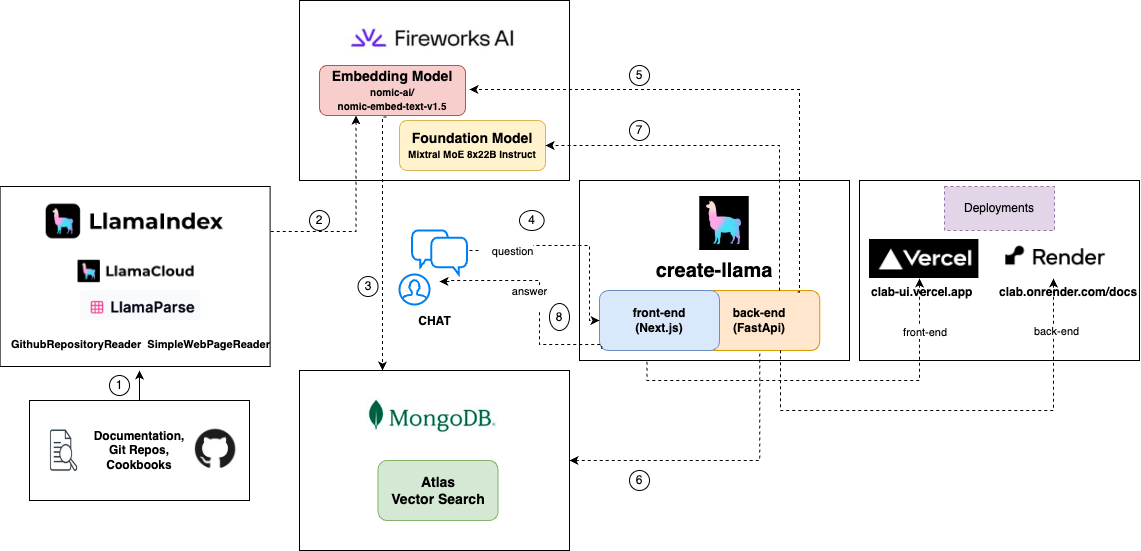
That’s why Team CLAB built LlamaWorksDB (try it out!), your friendly AI-powered doc wizard ✨. No more scattered searches! It taps into the knowledge of multiple sponsors of our hackathon including LlamaIndex, Fireworks.ai, and MongoDB, all through a single chatbot interface. Need something explained from MongoDB’s docs? Got it! Want a code example from Fireworks.ai? Easy!

The foundation: LlamaIndex and data ingestion
LlamaIndex was the heart and soul of LlamaWorksDB. It’s like a super versatile toolbox for handling all kinds of documentation! We primarily used their open-source readers to grab info straight from websites. A cool hack we did was customize the SimpleWebPageReader . We taught it to ignore website navigation bars, saving us a ton of precious tokens. 💪 While this worked great for the documentation sites, we used LlamaIndex’s GithubRepositoryReader to easily read through each repo.
python
from llama_index.readers.web import SimpleWebPageReader
import re
class LlamaDocsPageReader(SimpleWebPageReader):
def load_data(self, urls):
documents = super().load_data(urls)
processed_documents = []
for doc in documents:
processed_doc = self.process_document(doc)
processed_documents.append(processed_doc)
return processed_documents
def process_document(self, document):
# Split the document text by "Table of Contents"
pattern = r'(?i)\n\n*table\s*of\s*contents\n\n*'
parts = re.split(pattern, document.text, maxsplit=1)
# If there is a part after "Table of Contents", use it as the document text
if len(parts) > 1:
document.text = "Table of contents".join(parts[1:])
return document
Choosing how to split up the docs was interesting. LlamaIndex has options ranging from the basic SentenceSplitter to their SemanticNodeParser , which uses AI to group similar ideas. We went with the latter for those perfectly sized, meaningful chunks.
Finally, we embedded each ‘node’ and sent each as a document to MongoDB. Talk about streamlined! MongoDB stored the text, metadata, and our embeddings — ideal for the kind of search we wanted to build. We used Nomic’s flexible embedding model via Fireworks, which let us fine-tune the dimensions for maximum efficiency.
python
# FireworksEmbedding defaults to using model
embed_model = FireworksEmbedding(api_key=os.getenv('FIREWORKS_API_KEY'),
model="nomic-ai/nomic-embed-text-v1.5",
embed_batch_size=10,
dimensions=768 # can range from 64 to 768
)
# the tried and true sentence splitter
text_splitter = SentenceSplitter(chunk_size=1000, chunk_overlap=200)
# the semantic splitter uses our embedding model to group semantically related sentences together
semantic_parser = SemanticSplitterNodeParser(embed_model=embed_model)
# we set up MongoDB as our document and vector database
vector_store = MongoDBAtlasVectorSearch(
pymongo.MongoClient(os.getenv('MONGO_URI')),
db_name="fireParse",
collection_name="llamaIndexDocs",
index_name="llama_docs_index"
)
#finally we use LlamaIndex's pipeline to string this all together
pipeline = IngestionPipeline(
transformations=[
semantic_parser, #can replace with text_splitter
embed_model,
],
vector_store=vector_store,
)Once we have everything set up, we can create documents from URLs in MongoDB! Below is an example of using three URLs but we used hundreds.
python
example_urls = [
"https://docs.llamaindex.ai/en/stable/examples/cookbooks/llama3_cookbook",
"https://docs.llamaindex.ai/en/stable/examples/cookbooks/anthropic_haiku/",
"https://docs.llamaindex.ai/en/stable/examples/vector_stores/MongoDBAtlasVectorSearch/"
]
# read in the documents and pass them through our pipeline
documents = LlamaDocsPageReader(html_to_text=True).load_data(example_urls)
pipeline.run(documents=documents, show_progress=True)You can see in MongoDB how our documents have text, embedding (with 768 dimensions), and metadata.

MongoDB Atlas for vector search
MongoDB Atlas was our go-to for storing both the documentation text and the embeddings themselves. It’s incredibly versatile! Setting up vector search within Atlas is a breeze, allowing us to quickly find the most relevant document chunks. Plus, LlamaIndex’s metadata parsing played perfectly with Atlas — we could easily filter results based on things like document source or topic.
Setting up Vector Search: It was remarkably simple! We just specified these few things:
- Path to the embedding field within our documents.
- Embedding dimension size.
- Similarity metric (e.g., cosine similarity).
- That it’s a vector index.
Filtering Power (Optional): For even finer control, we could add paths to fields we wanted to filter our searches by (like the company’s name).

Whether you’re building a complex web app or a quick Streamlit prototype, LlamaIndex ChatEngines have you covered. They effortlessly manage conversation history, let you perform lightning-fast vector searches, and unlock a whole suite of powerful tools.
We built our ChatEngine directly from our trusty MongoDB index. This integration was surprisingly simple:
python
def get_index():
logger.info("Connecting to index from MongoDB...")
store = MongoDBAtlasVectorSearch(
db_name=os.environ["MONGODB_DATABASE"],
collection_name=os.environ["MONGODB_VECTORS"],
index_name=os.environ["MONGODB_VECTOR_INDEX"],
)
index = VectorStoreIndex.from_vector_store(store)
logger.info("Finished connecting to index from MongoDB.")
return index
index = get_index()
index.as_chat_engine(
llm = Fireworks(
api_key=env_vars['FIREWORKS_API_KEY'],
model="accounts/fireworks/models/mixtral-8x22b-instruct" #Can be changed out for Llama3
)
chat_mode="best",
context_prompt=(
""" You are a software developer bot that is an expert at reading over documentation to answer questions.
Use the relevant documents for context:
{context_str}
\nInstruction: Use the previous chat history, or the context above, to interact and help the user.
"""
),
verbose=True
) create-llama : from idea to app in record time
We were seriously impressed by Create-Llama. Usually, building a full-stack app takes time, but Create-Llama had us up and running in under 15 minutes! All we did was point it towards our vector database and give a few basic details. Honestly, it made development a joy! This blog post goes into more detail about how to use create-llama.


Deployment: Render and Vercel
To make LlamaWorksDB production-ready and easily accessible, we turned to Render and Vercel. Render was a perfect fit for our Python FastAPI backend, as it focuses on ease of deployment and scalability. Vercel seamlessly handled our Next.js frontend — we loved its developer-centric approach and the effortless build process. Both platforms made deployment a breeze, letting us focus on coding rather than complex infrastructure setup.
Future directions
Our hackathon success is just the beginning. We envision LlamaWorksDB evolving into a powerhouse for developers seeking answers within technical documentation. Here’s how we see it growing:
- Enhanced Retrieval: We’re excited to experiment with LlamaIndex’s powerful capabilities like MultiVectorSearch to further refine our results. Integrating different LLMs will open up new possibilities for how LlamaWorksDB understands and interacts with technical content.
- A Focus on Documentation: We want to double down on making LlamaWorksDB the ultimate tool for navigating documentation. This means exploring specialized techniques and tools designed specifically for understanding complex technical information.
LlamaWorksDB is an open-source project in Beta, and we believe in the power of collaboration! If you’re passionate about AI-powered documentation tools, we invite you to:
- Try it out: Explore our GitHub repo and give LlamaWorksDB a spin!
- Contribute: Help us build new features, test integrations, and refine our search capabilities.
- Share your feedback: Let us know how we can make LlamaWorksDB even better.
Together, let’s revolutionize the way developers interact with documentation!
🔗 Explore our project and join the innovation: https://github.com/clab2024/clab/
https://clab-ui.vercel.app/ (front-end) (leverages free credits responds late)
https://clab.onrender.com/docs (back-end)
Meet Team CLAB! 🎉
- Chris Wood: Up-and-coming tech whiz, ready to graduate with valuable insights from his internship at Tutello.
- Leo Walker: Data Scientist with the discipline and precision of a Military Veteran.
- Andrew Townsend: A Computer Science graduate from SJSU, bringing fresh academic perspectives.
- Barath Subramaniam: The strategic mind behind Product Security AI and Data engineering at Adobe. Twitter: @baraths84