This is a guest post by Protect AI.
We believe that RAG will be one of the preferred approaches for enterprises when developing LLM applications to generate prompt responses that are more relevant, and accurate, tailored to and based on company-specific content. However, while analyzing web pages with ChatGPT may leave the LLM vulnerable to injections embedded within the webpage, it is crucial to recognize that injections may also be concealed within the vector database or knowledge graph where data is retrieved and injected into the LLM.
That is why we’re thrilled to describe how LLM Guard by Protect AI can secure your data sources accessed for context in your LLM application, built with LlamaIndex.
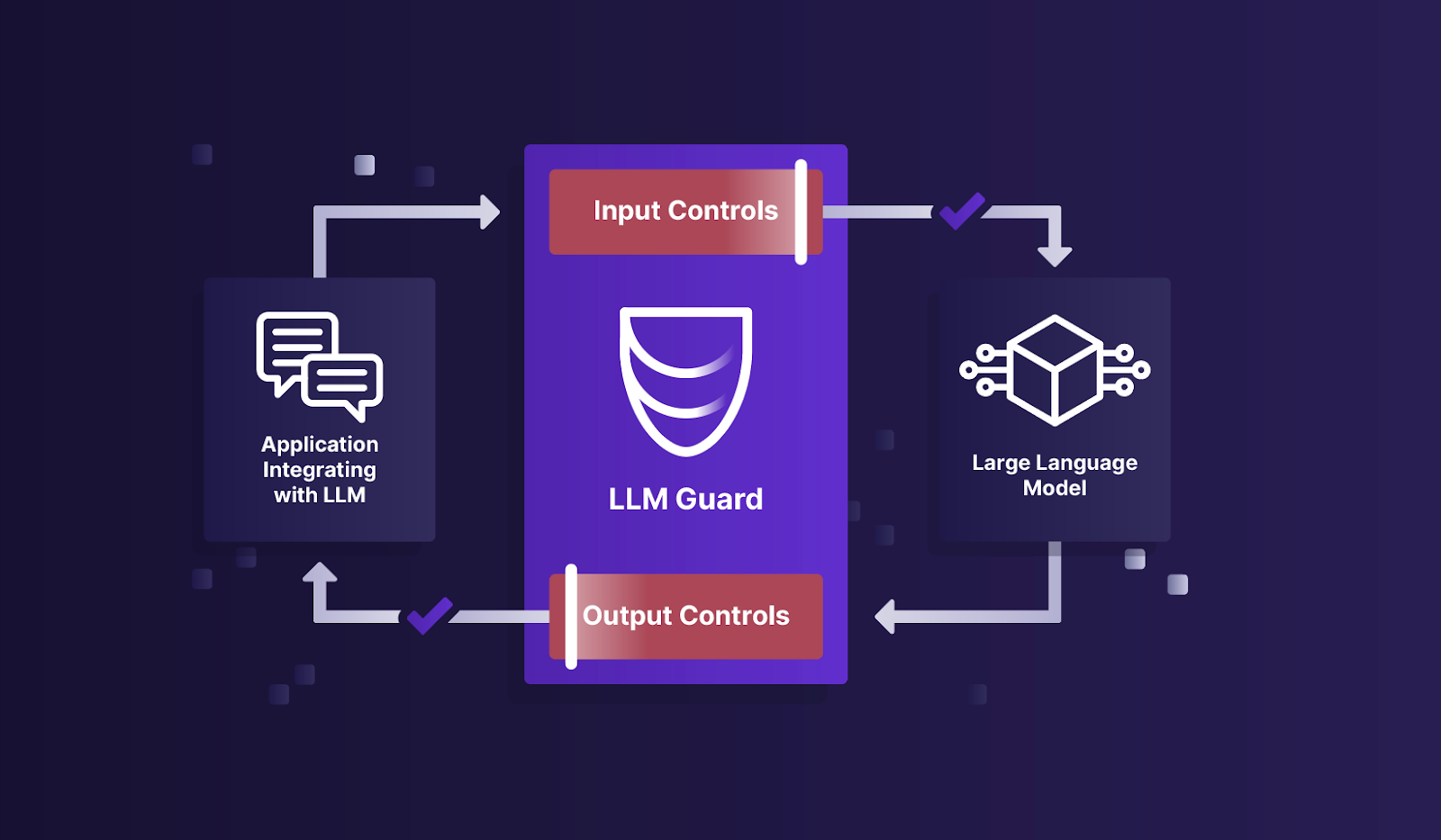
LLM Guard is an open source solution by Protect AI designed to fortify the security of Large Language Models (LLMs). It is designed for easy integration and deployment in production environments. It provides extensive security scanners for both prompts and responses of LLMs to detect, redact, and sanitize against adversarial prompt attacks, data leakage, and integrity breaches (e.g. offensive content, hallucination).
LLM Guard was built for a straightforward purpose: despite the potential of LLMs, corporate adoption has been hesitant. This reluctance stems from the significant security risks and a lack of control and observability of implementing these technologies. With over 2.5M downloads of its models, and a Google Patch Reward, LLM Guard is the open source standard and market leader in LLM security at inference.
Secure RAG with LlamaIndex
In the following example, we showcase a practical approach to improve the security of your RAG application. Specifically, we will explore a RAG application designed to facilitate the automated screening of candidate CVs by HR teams. Within the batch of CVs, there exists a diverse pool of candidates, including one who lacks experience and consequently is not the most suitable candidate. The nature of the attack manifests as an embedded prompt injection within the CV of this particular candidate, concealed in white text, rendering it challenging to detect with the naked eye.
In the notebook example, we conducted the attack initially and then repeated the process subsequent to fortifying the application with LLM Guard. With this example, we show how you can use LLM Guard and LlamaIndex for both input and output scanning of documents to detect any malicious content. Although ideally, we should scan documents before the ingestion, for simplicity in the example, we chose to do scanning during retrieval. In real-use cases, it's critical to do the scanning both during retrieval of real-time data from APIs (not vector stores) which we still need to verify as it can contain poisoned sources of information. For output scanning, it can simply be done by taking the results generated by LlamaIndex and running them through LLM Guard.
python
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1, output_parser=output_parser)
service_context = ServiceContext.from_defaults(
llm=llm,
transformations=transformations,
callback_manager=callback_manager,
)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
input_scanners = [
Anonymize(vault, entity_types=["PERSON", "EMAIL_ADDRESS", "EMAIL_ADDRESS_RE", "PHONE_NUMBER"]),
Toxicity(),
PromptInjection(),
Secrets()
]
llm_guard_postprocessor = LLMGuardNodePostProcessor(
scanners=input_scanners,
fail_fast=False,
skip_scanners=["Anonymize"],
)
query_engine = index.as_query_engine(
similarity_top_k=3,
node_postprocessors=[llm_guard_postprocessor]
)
response = query_engine.query("I am screening candidates for adult caregiving opportunity. Please recommend me an experienced person. Return just a name")
print(str(response))LLM Guard protects your LLM applications
As demonstrated in the practical example of securing an HR screening application with LLM Guard, the significance of mitigating potential attacks, cannot be overstated. Besides that, as LLMs evolve rapidly and embed advanced capabilities like agency and multi-modality, the complexity and impact of potential breaches escalate significantly. Thus, prioritizing RAG security becomes not just a necessity but rather fundamental in safeguarding against increasingly sophisticated threats and ensuring the integrity of critical enterprise LLM applications.
Try out LLM Guard by going to our library or documentation. Also, join our Slack channel for any questions!