

We’re excited to share with you the thought process and solution design of NewsGPT (Neotice) — Clickbait Buster, a Streamlit LLM hackathon-winning app powered by LlamaIndex, Streamlit, and Qdrant. In this article, we’ll define the problem we’re trying to solve and discuss how we approached it. Lastly, we offer a workaround to enable LlamaIndex streaming on Streamlit Chat Bot and the all the code can be found here. We hope you’ll find our insights helpful and informative.
Introduction
Problem Statement
It’s evident that people’s habits of consuming information have changed over time. Previously, we read lengthy articles content and watched long videos, such as newspapers and YouTube videos. However, we currently prefer reading titles and consuming short-form content, such as TikTok and YouTube shorts. Although this shift has made it easier to get more information in less time, it has also led to clickbait headlines that often contain incorrect information.
When we started developing NewsGPT, our primary focus was to solve the above-stated pain points and provide a solution that 1) provides accurate information and 2) saves time for users.
Neotice

We are excited to announce that the beta version of the Neotice app, which is the production version of NewsGPT, is now available for users to try out! We are grateful to the Streamlit Hackathon for showcasing our prototype and philosophy. With the help of this platform, we are confident that our app will revolutionize the way people consume news.
Why NewsGPT Stands Out
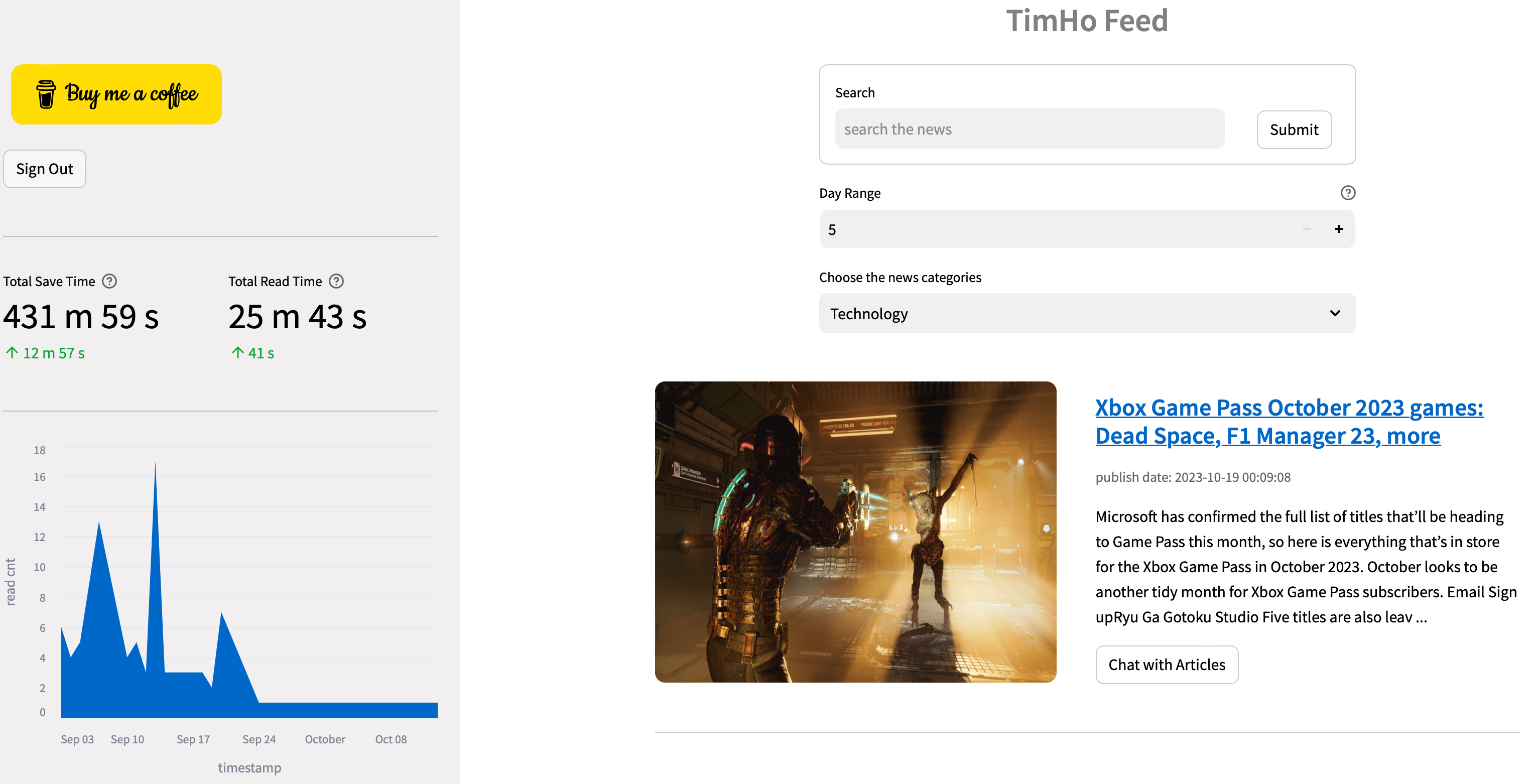
NewsGPT has four main components: Reliable News Sources, Tailored News Recommendations, Efficient Information Retrieval, and Time Saver.
✅ Reliable News Sources:
- We’ve established a dynamic data pipeline designed to ingest daily news, ensuring our information is up-to-date and relevant.
- Sophisticated Named-Entity Recognition, Text Embedding with OpenAI API, and asynchronous article embedding processes are incorporated. This data is systematically stored in the QdrantVector Database, promoting accuracy and efficiency.
✅ Tailored News Recommendations:
- Our system does more than just present news; it learns from you. By analyzing your reading habits, we leverage article embeddings to curate a personal news feed tailored to your interests.
- A versatile search bar is always at your disposal, letting users explore any news topics that capture their interest.
✅ Efficient Information Retrieval:
- With just a single click on an article of interest, NewsGPT gets to work. It collates similar news from multiple sources (3–5) and activates a Streamlit chatbot.
- Your engagement begins immediately: the first query is autonomously forwarded to our chatbot to fetch a concise news summary.
- For ease of user experience, we display predefined prompts as clickable buttons. This means users can receive information without the need for manual input.
- Curiosity welcomed: any questions users may have about the news article will be addressed as long as the answers are detailed within the source articles.
✅ Time-Saving Reminder & Category Distribution Chart:
- To keep you informed, our sidebar displays the time saved using NewsGPT and visually represents news category distribution.
Delving Deep into Architecture
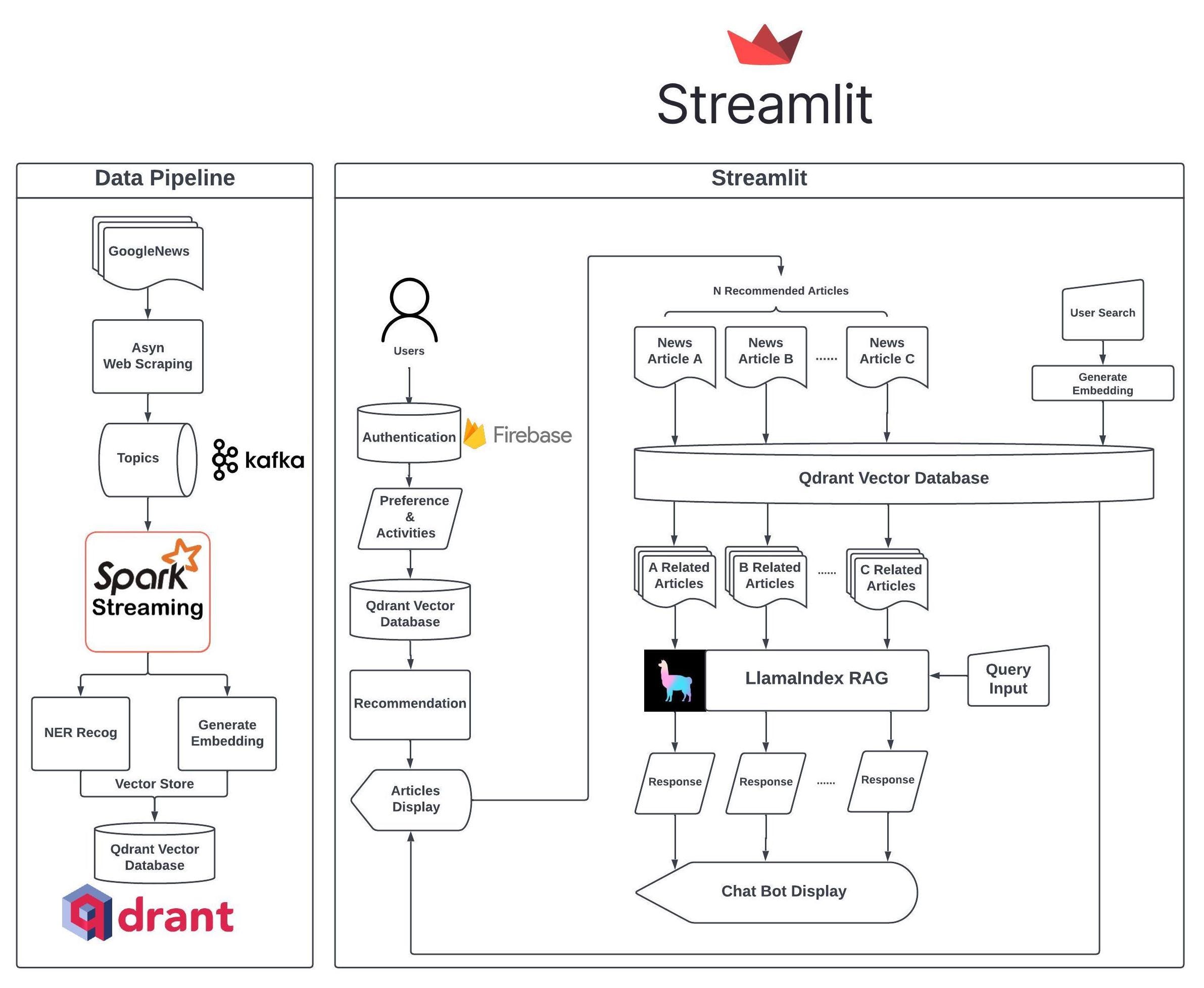
Data Pipeline
We start with a reliable and sustainable data pipeline to support the users to get fresh news with two powerful libraries, pygooglenews, and newspaper3k.
pip install pygooglenews --upgrade
pip install newspaper3kBy utilizing Spark batch processing, we efficiently process data with NER(Named-Entity Recognition) and create embeddings via OpenAI API (Ada model). After the preprocessing of the data, we collect the metadata, including keywords, NER results, summary, body, title, author, and so on, in the payload and push the payload with embedding to the Qdrant Vector Database.
We will skip the part on how to create embeddings with the OpenAI Ada model, as there are many existing tutorials available. To perform Named Entity Recognition, we utilize the dslim/bert-base-NER model from HuggingFace.
from transformers import pipeline
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("dslim/bert-base-NER")
model = AutoModelForTokenClassification.from_pretrained("dslim/bert-base-NER")
nlp = pipeline("ner", model=model, tokenizer=tokenizer, batch_size=batch_size)
ner_results = nlp(texts)Personalization
When accessing NewsGPT, we have two options: we can either create a new account or use a guest login to test the service. It should be noted, however, that using the guest login will not provide personalization. If we choose to sign up, we will be asked about our preferred news categories, which will help the service make initial recommendations during the cold start.
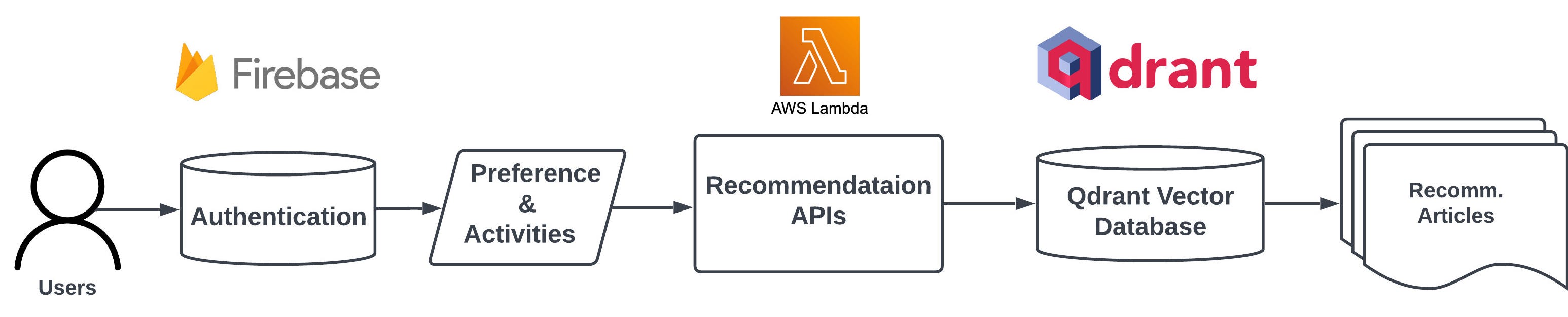
After users sign up and log in, we query the preferences and activities from Google Firebase, if any; otherwise, use the favorite categories for recommendation cold start. If the activities and preferences are available, we will call the recommendation API hosted on AWS Lambda and generate personalized articles for the users. The activities related to the user reading history. Users can indicate their preference for articles by clicking thumbs-up or down buttons on the article page. Some of the recommendation logic can be found in the code.
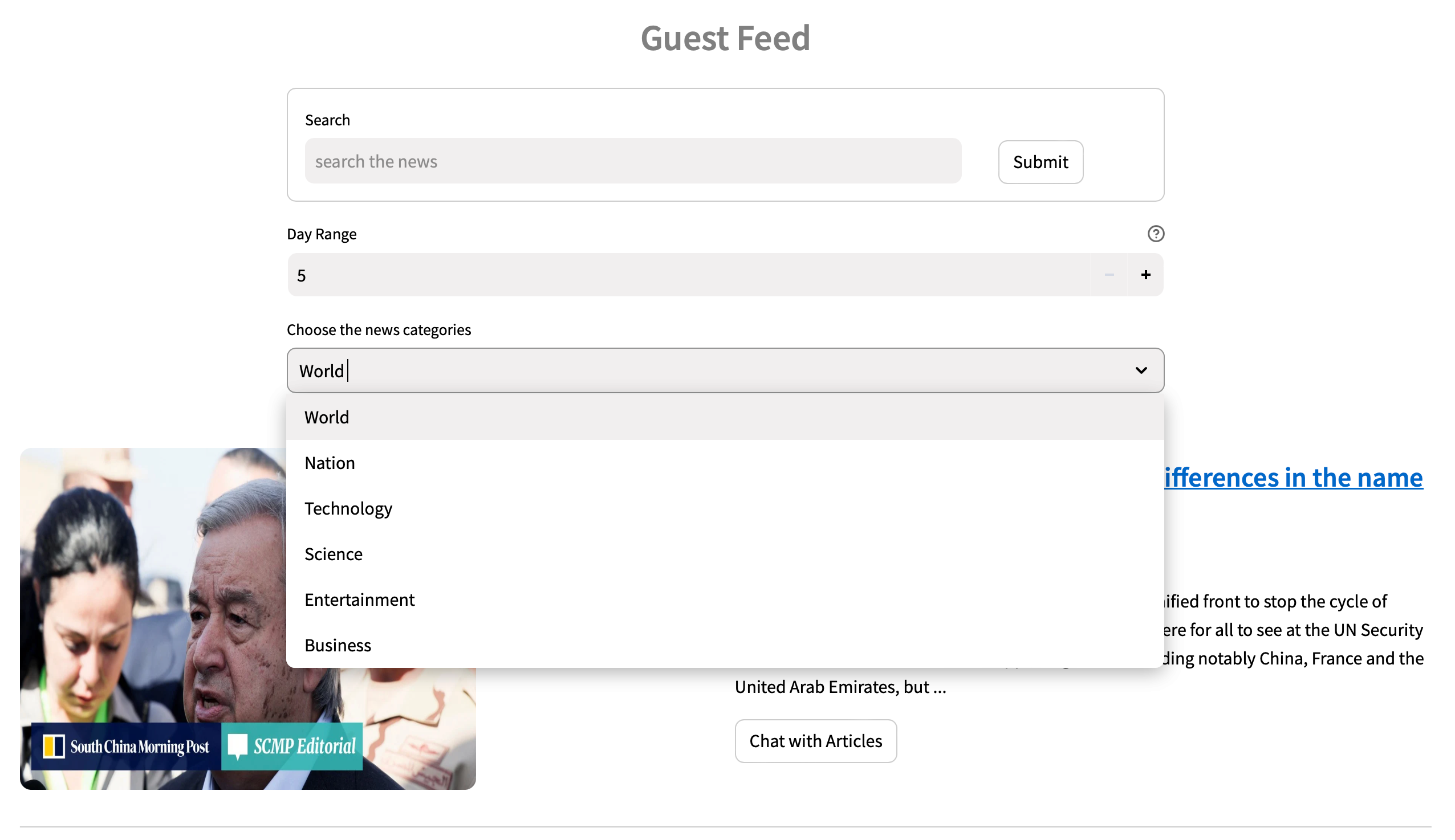
Besides the personalized feeds, users can also choose different categories or search for specific topics using the search bar.
Chat with Article Powered by LlamaIndex
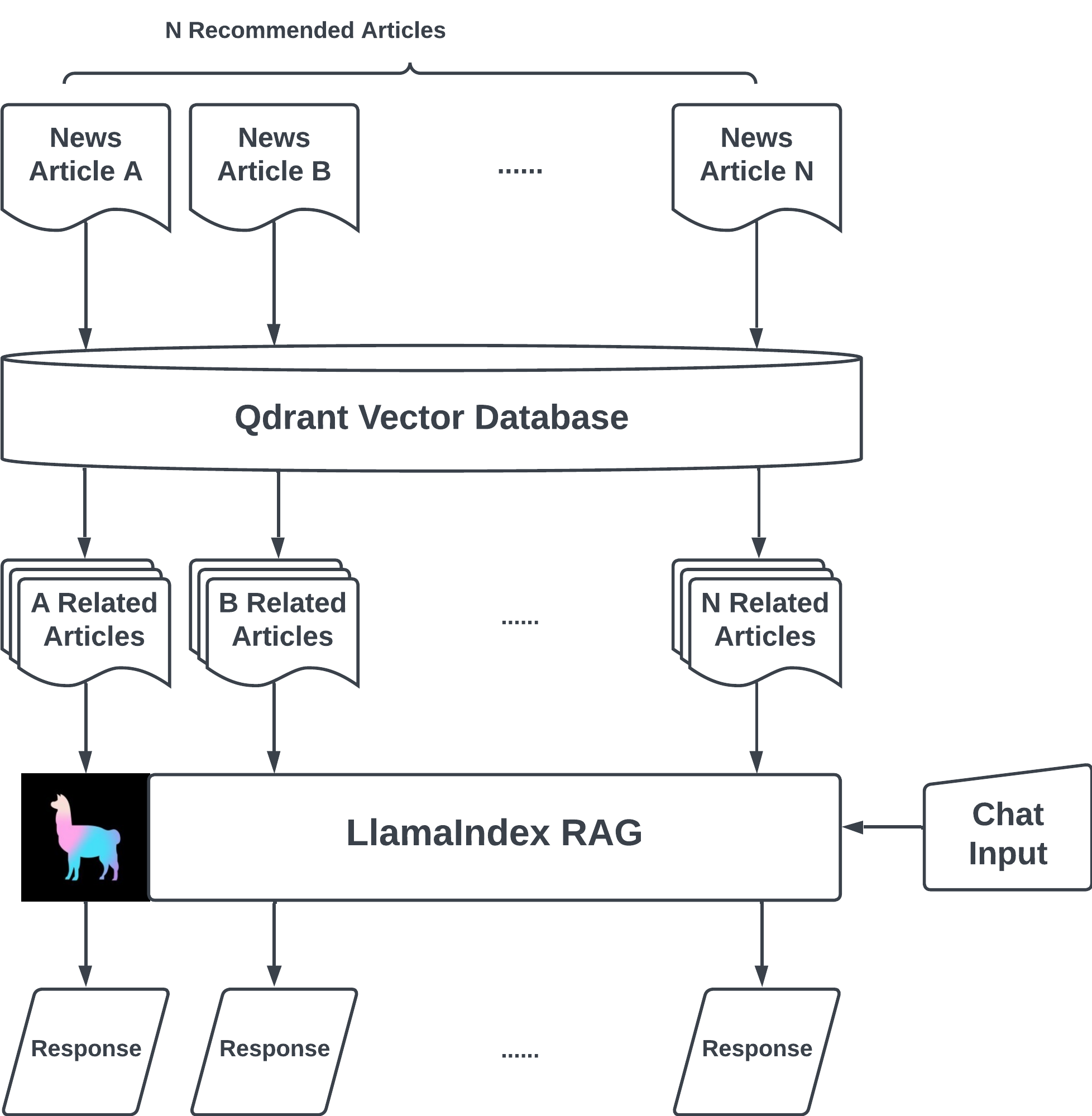
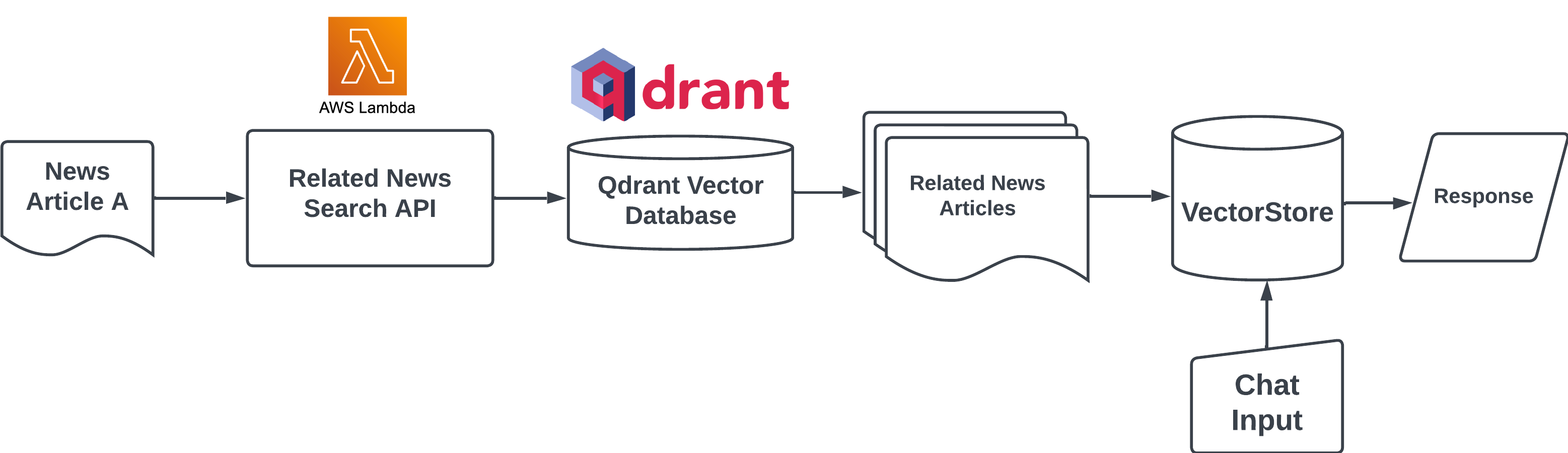
Unlike other news aggregator apps, NewsGPT offers a unique service by providing users with a summary and discrepancy key takeaway of a topic from various news sources. This feature not only saves users time by eliminating the need to read multiple articles but also helps identify which information can be trusted by comparing discrepancies. What is under the hood is when the user clicks on the “chat with article” button, the system first uses a search API hosted on AWS Lambda to find related articles from various sources. Then, the system utilizes the LlamaIndex library to create a vector store and a query engine, which can be integrated with the Streamlit chat component to create an RAG application for information retrieval.
Streaming Output with LlamaIndex and Streamlit
Thanks to the powerful library, Streamlit-Extras, which provides additional functionality not officially supported. To enhance the user experience and make it more like chatting with ChatGPT, we use the streaming_write functions from the Streamlit-Extras library. Additionally, we set streaming=True for the query_engine to ensure a smoother experience. Let’s take a look at the code.
pip install streamlit-extrasTo begin with, we set up the service_context.
from llama_index import ServiceContext
st.session_state["service_context"] = ServiceContext.from_defaults(
llm=OpenAI(
model="gpt-3.5-turbo",
temperature=0.2,
chunk_size=1024,
chunk_overlap=100,
system_prompt="As an expert current affairs commentator and analyst,\
your task is to summarize the articles and answer the questions from the user related to the news articles",
),
chunk_size=256,
chunk_overlap=20
)Next, we create a text splitter using TokenTextSplitter and a node parser using SimpleNodeParser to parse multiple articles.
from llama_index.text_splitter import TokenTextSplitter
from llama_index.node_parser import SimpleNodeParser
text_splitter = TokenTextSplitter(separator=" ", chunk_size=256, chunk_overlap=20)
#create node parser to parse nodes from document
node_parser = SimpleNodeParser(text_splitter=text_splitter)
nodes = node_parser.get_nodes_from_documents(documents)In the third step, we create an index using VectorStoreIndex. To enable streaming capability, ensure to set streaming=True while setting up the query_engine.
from llama_index import VectorStoreIndex
index = VectorStoreIndex(
nodes=nodes,
service_context=st.session_state["service_context"]
)
st.session_state["chat_engine"] = index.as_query_engine(streaming=True)To add streaming capability to Streamlit chat components, we took inspiration from this code. Instead of using st.write() from the regular chat implementation, we replaced it with the write function from streaming_write.
response = st.session_state["chat_engine"].query(prompt)
def stream_example():
for word in response.response_gen:
yield word
write(stream_example)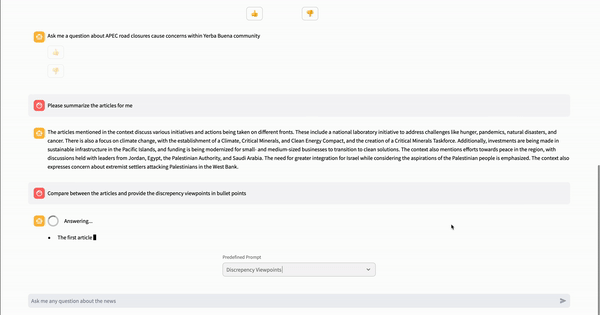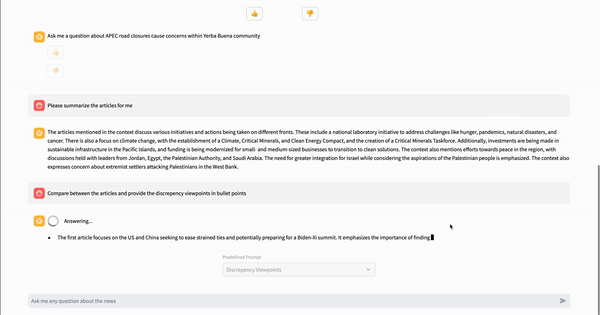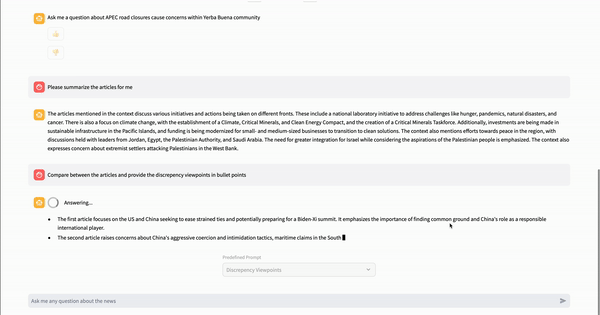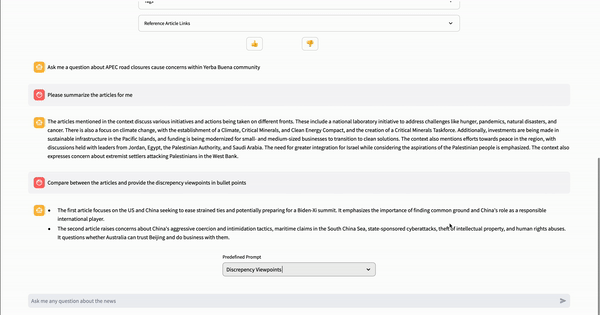
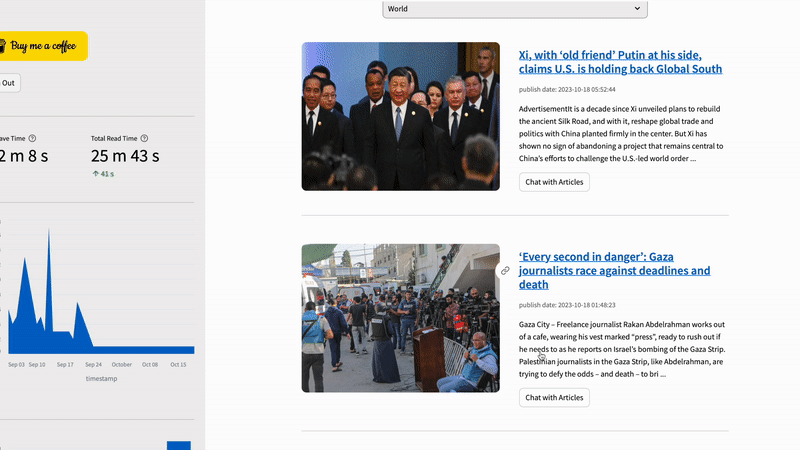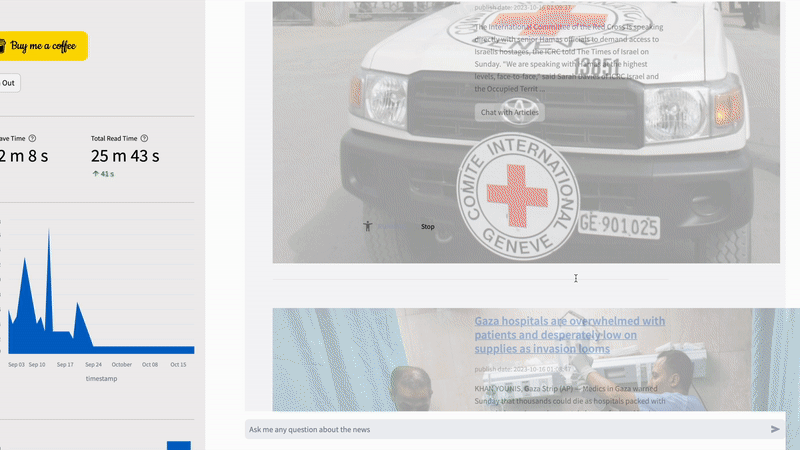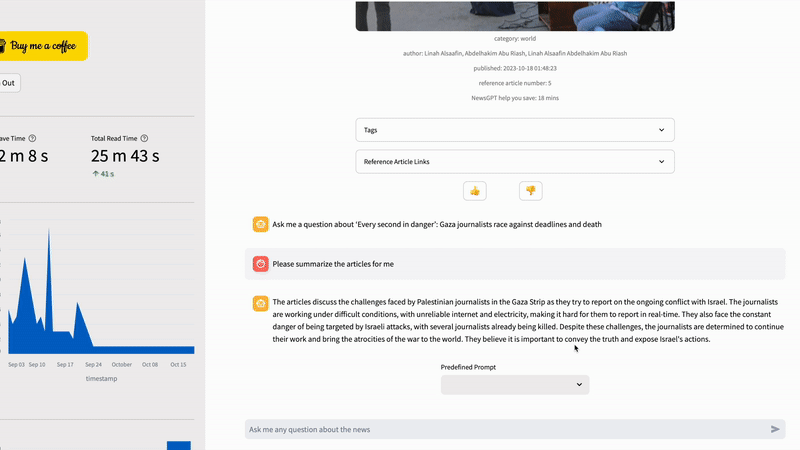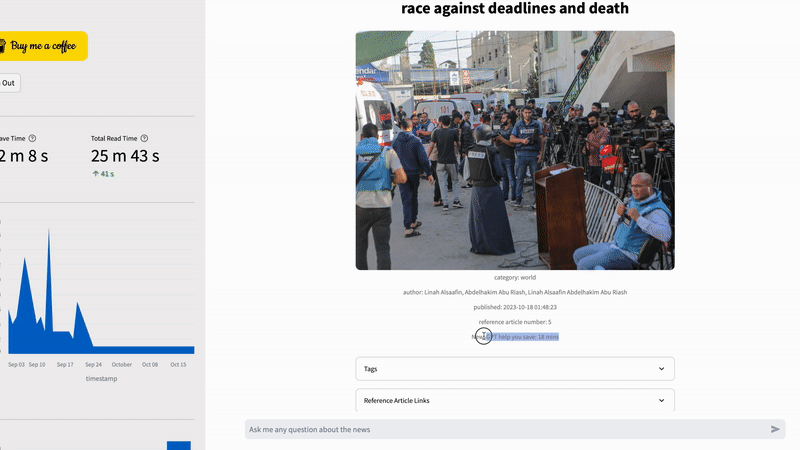
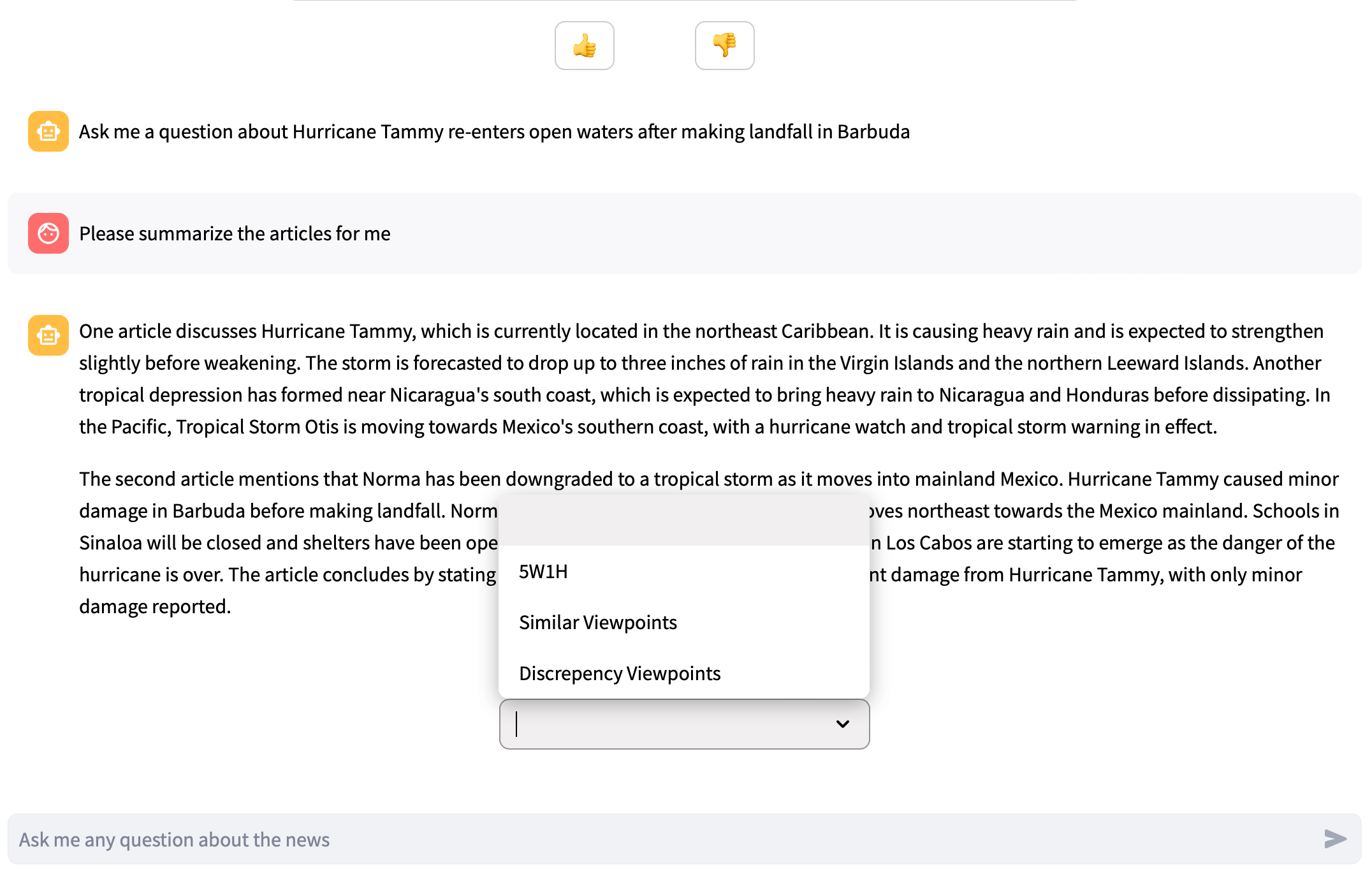
Predefined Prompts
Three different prompts are predefined in the article chat page, allowing users to select from a drop-down menu to ask questions without typing. The prompts are 5W1H, Similar Viewpoints, and Discrepancy Viewpoints.
prompt_content = {
"5W1H": 'Summarize the content details in the "5W1H" approach (Who, What, When, Where, Why, and How) in bullet points',
"Similar Viewpoints": "Compare between the articles and provide the similar viewpoints in bullet points",
"Discrepency Viewpoints": "Compare between the articles and provide the discrepency viewpoints in bullet points"
}
What’s Next
Huge thanks to LlamaIndex and Streamlit for generously providing a massive platform that allows more people to gain awareness of the organic news digest and save valuable time through NewsGPT. If you enjoyed reading the article and agree with our concept, please do not hesitate to leave a clap for the article and join Neotice, the production app of NewsGPT, to support us. We are confident in our mission and look forward to having you on board with us. Thank you!
You can also connect us on LinkedIn: Kang-Chi Ho, Jian-An Wang
🎉 Click Here to Join Neotice 👉 Neotice