

The widespread consumption of videos on platforms like YouTube, Instagram, and others highlights the importance of efficiently processing and analyzing video content. This capability unlocks vast opportunities across various sectors, including media and entertainment, security, and education. However, the main challenge is effectively extracting meaningful information from videos, which are inherently complex and multimodal data streams.
This blog post introduces a solution that leverages the LlamaIndex Python API for using the advanced capabilities of OpenAI’s GPT4V, combined with the efficient data management by LanceDB across all data formats, to process videos.
…But what does ‘RAG’ even mean?
Retrieval-augmented generation (RAG) is a technique that merges information retrieval with generative AI to produce systems capable of generating precise and contextually relevant responses by tapping into large data repositories.
Core Concept of RAG
RAG operates in two stages:
- Retrieval: Utilizes semantic search to find documents related to a query, leveraging the context and meaning beyond mere keywords.
- Generation: Integrates retrieved information to produce coherent responses, allowing the AI to “learn” from a wide range of content dynamically.
RAG Architecture
The architecture typically involves a dense vector search engine for retrieval and a transformer model for generation. The process:
- Performs a semantic search to fetch relevant documents.
- Processes these documents with the query to create a comprehensive context.
- The generative model then crafts a detailed response based on this enriched context.
Extending to Multimodality
Multimodal RAG integrates various data types (text, images, audio, video) in both retrieval and generation phases, enabling richer information sourcing. For example, responding to queries about “climate change impacts on polar bears” might involve retrieving scientific texts, images, and videos to produce an enriched, multi-format response.
Let’s return to our use case and dive into how it’s all done. Moving forward, you can access the full code on Google Colab.
The solution is divided into the following sections. Click on the topic to skip to a specific part:
- Video Downloading
- Video Processing
- Building the Multi-Modal Index and Vector Store
- Retrieving Relevant Images and Context
- Reasoning and Response Generation
1. Video Downloading
To begin, we need to locally download multimodal content from a publicly available source, I used pytube to download a YouTube video by 3Blue1Brown on the Gaussian function.
# SET CONFIG
video_url = "https://www.youtube.com/watch?v=d_qvLDhkg00"
output_video_path = "./video_data/"
output_folder = "./mixed_data/"
output_audio_path = "./mixed_data/output_audio.wav"
filepath = output_video_path + "input_vid.mp4"
Path(output_folder).mkdir(parents=True, exist_ok=True)def download_video(url, output_path):
"""
Download a video from a given url and save it to the output path.
Parameters:
url (str): The url of the video to download.
output_path (str): The path to save the video to.
Returns:
dict: A dictionary containing the metadata of the video.
"""
from pytube import YouTube
yt = YouTube(url)
metadata = {"Author": yt.author, "Title": yt.title, "Views": yt.views}
yt.streams.get_highest_resolution().download(
output_path=output_path, filename="input_vid.mp4"
)
return metadata
Run metadata_vid = download_video(video_url, output_video_path) to invoke the function and store the video locally.
2. Video Processing
We need to now extract multimodal content — Images, Text(via Audio). I extracted 1 frame every 5 seconds of the video (~160 frames) using moviepy .
def video_to_images(video_path, output_folder):
"""
Convert a video to a sequence of images and save them to the output folder.
Parameters:
video_path (str): The path to the video file.
output_folder (str): The path to the folder to save the images to.
"""
clip = VideoFileClip(video_path)
clip.write_images_sequence(
os.path.join(output_folder, "frame%04d.png"), fps=0.2 #configure this for controlling frame rate.
)Following this, we extract the audio component:
def video_to_audio(video_path, output_audio_path):
"""
Convert a video to audio and save it to the output path.
Parameters:
video_path (str): The path to the video file.
output_audio_path (str): The path to save the audio to.
"""
clip = VideoFileClip(video_path)
audio = clip.audio
audio.write_audiofile(output_audio_path)Next, let’s extract text from the audio using the SpeechRecognition library:
def audio_to_text(audio_path):
"""
Convert an audio file to text.
Parameters:
audio_path (str): The path to the audio file.
Returns:
test (str): The text recognized from the audio.
"""
recognizer = sr.Recognizer()
audio = sr.AudioFile(audio_path)
with audio as source:
# Record the audio data
audio_data = recognizer.record(source)
try:
# Recognize the speech
text = recognizer.recognize_whisper(audio_data)
except sr.UnknownValueError:
print("Speech recognition could not understand the audio.")
except sr.RequestError as e:
print(f"Could not request results from service; {e}")
return textRun the below chunk to complete the extraction and storage process:
video_to_images(filepath, output_folder)
video_to_audio(filepath, output_audio_path)
text_data = audio_to_text(output_audio_path)
with open(output_folder + "output_text.txt", "w") as file:
file.write(text_data)
print("Text data saved to file")
file.close()
os.remove(output_audio_path)
print("Audio file removed")3. Building the Multi-Modal Index and Vector Store
After processing the video, we proceed to construct a multi-modal index and vector store. This entails generating embeddings for both textual and visual data using OpenAI’s CLIP model, subsequently storing and managing these embeddings in LanceDB VectorStore via the LanceDBVectorStore class.
from llama_index.indices.multi_modal.base import MultiModalVectorStoreIndex
from llama_index import SimpleDirectoryReader, StorageContext
from llama_index import SimpleDirectoryReader, StorageContext
from llama_index.vector_stores import LanceDBVectorStore
from llama_index import (
SimpleDirectoryReader,
)
text_store = LanceDBVectorStore(uri="lancedb", table_name="text_collection")
image_store = LanceDBVectorStore(uri="lancedb", table_name="image_collection")
storage_context = StorageContext.from_defaults(
vector_store=text_store, image_store=image_store
)
# Create the MultiModal index
documents = SimpleDirectoryReader(output_folder).load_data()
index = MultiModalVectorStoreIndex.from_documents(
documents,
storage_context=storage_context,
)4. Retrieving Relevant Images and Context
With the index in place, the system can then retrieve pertinent images and contextual information based on input queries. This enhances the prompt with precise and relevant multimodal data, anchoring the analysis in the video’s content.
Lets set up the engine for retrieving, I am fetching top 5 most relevant Nodes from the vectordb based on the similarity score:
retriever_engine = index.as_retriever(
similarity_top_k=5, image_similarity_top_k=5
)A
Nodeobject is a “chunk” of any source Document, whether it’s text, an image, or other. It contains embeddings as well as meta information of the chunk of data.By default, LanceDB uses
l2as metric type for evaluating similarity. You can specify the metric type ascosineordotif required.
Next, we create a helper function for executing the retrieval logic:
from llama_index.response.notebook_utils import display_source_node
from llama_index.schema import ImageNode
def retrieve(retriever_engine, query_str):
retrieval_results = retriever_engine.retrieve(query_str)
retrieved_image = []
retrieved_text = []
for res_node in retrieval_results:
if isinstance(res_node.node, ImageNode):
retrieved_image.append(res_node.node.metadata["file_path"])
else:
display_source_node(res_node, source_length=200)
retrieved_text.append(res_node.text)
return retrieved_image, retrieved_textdef retrieve(retriever_engine, query_str):
retrieval_results = retriever_engine.retrieve(query_str)Lets input the query now and then move on to complete the process by retrieving and visualizing the data :
query_str = """
Using examples from the video, explain all things covered regarding
the Gaussian function
"""
img, txt = retrieve(retriever_engine=retriever_engine, query_str=query_str)
image_documents = SimpleDirectoryReader(
input_dir=output_folder, input_files=img
).load_data()
context_str = "".join(txt)
plot_images(img)You should see something similar to the example below (note that the output will vary depending on your query):
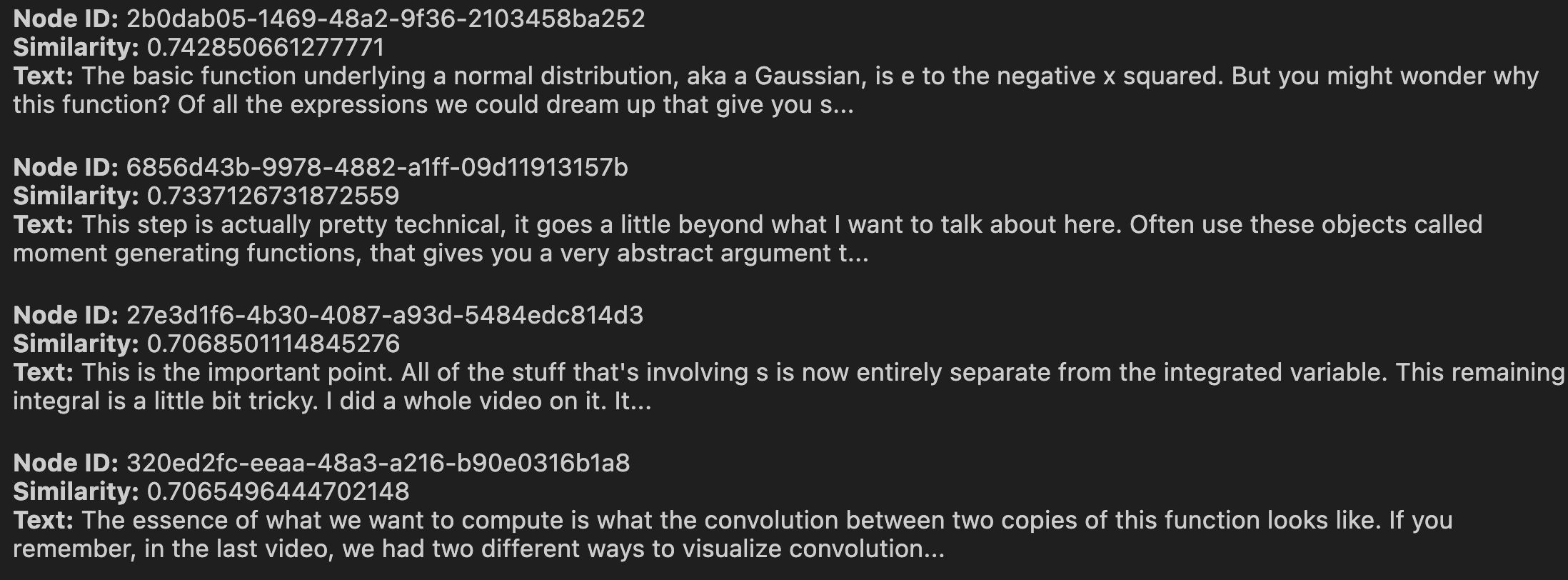
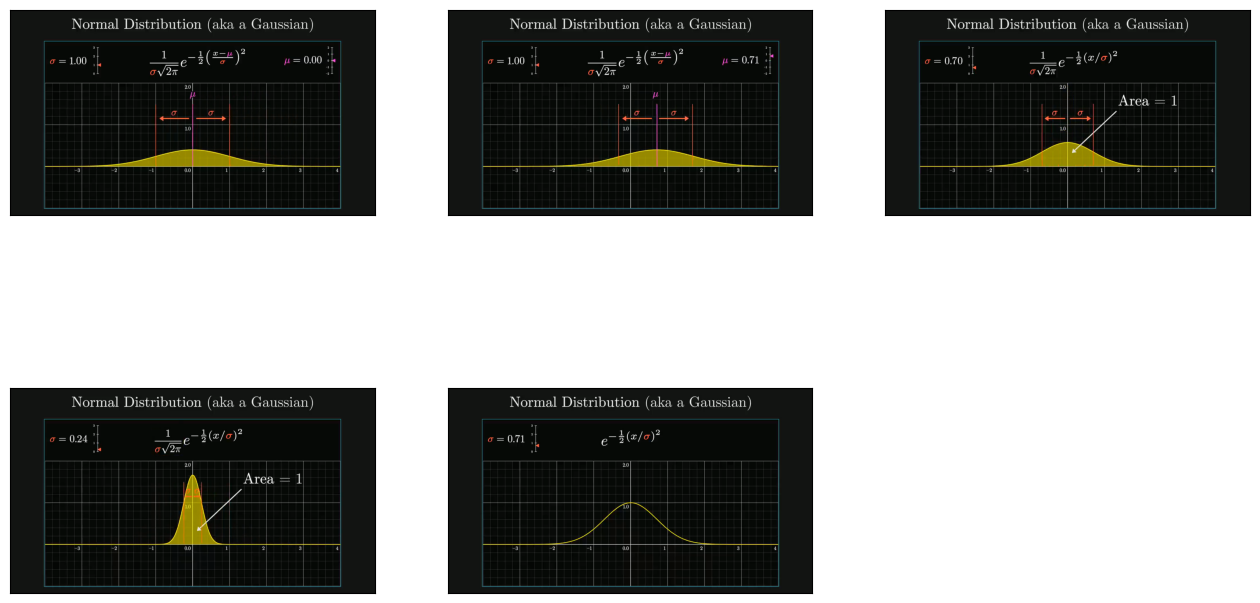
Observe that the node object displayed shows the Id of the data chunk , its similarity score and the source text of the chunk that was matched (for images we get the filepath instead of text).
5. Reasoning and Response Generation
The final step leverages GPT4V to reason about the correlations between the input query and the augmented data. Below is the prompt template :
qa_tmpl_str = (
"""
Given the provided information, including relevant images and retrieved context from the video, \
accurately and precisely answer the query without any additional prior knowledge.\n"
"Please ensure honesty and responsibility, refraining from any racist or sexist remarks.\n"
"---------------------\n"
"Context: {context_str}\n"
"Metadata for video: {metadata_str} \n"
"---------------------\n"
"Query: {query_str}\n"
"Answer: "
"""
)The OpenAIMultiModal class from LlamaIndex enables us to incorporate image data directly into our prompt object. Thus, in the final step, we enhance the query and contextual elements within the template to produce the response as follows:
from llama_index.multi_modal_llms.openai import OpenAIMultiModal
openai_mm_llm = OpenAIMultiModal(
model="gpt-4-vision-preview", api_key=OPENAI_API_TOKEN, max_new_tokens=1500
)
response_1 = openai_mm_llm.complete(
prompt=qa_tmpl_str.format(
context_str=context_str, query_str=query_str, metadata_str=metadata_str
),
image_documents=image_documents,
)
pprint(response_1.text)The generated response captures the context pretty well and structures the answer correctly :
The video “A pretty reason why Gaussian + Gaussian = Gaussian” by 3Blue1Brown delves into the Gaussian function or normal distribution, highlighting several critical aspects:
Central Limit Theorem: It starts with the central limit theorem, illustrating how the sum of multiple random variable copies tends toward a normal distribution, improving with more variables.
Convolution of Random Variables: Explains the addition of two random variables as their distributions’ convolution, focusing on visualizing this through diagonal slices.
Gaussian Function: Details the Gaussian function, emphasizing the normalization factor for a valid probability distribution, and describes the distribution’s spread and center with standard deviation (σ) and mean (μ).
Convolution of Two Gaussians: Discusses adding two normally distributed variables, equivalent to convolving two Gaussian functions, and visualizes this using the graph’s rotational symmetry.
Rotational Symmetry and Slices: Shows the rotational symmetry of e^(-x²) * e^(-y²) around the origin, a unique Gaussian function property. It explains computing the area under diagonal slices, equating to the functions’ convolution.
Resulting Distribution: Demonstrates the convolution of two Gaussian functions yielding another Gaussian, a notable exception in convolutions usually resulting in a different function type.
Standard Deviation of the Result: Concludes that convolving two normal distributions with mean 0 and standard deviation (σ) produces a normal distribution with a standard deviation of sqrt(2) * σ.
Implications for the Central Limit Theorem: Highlights the convolution of two Gaussians’ role in the central limit theorem, positioning the Gaussian distribution as a distribution space fixed point.
The author uses visual examples and explanations throughout to clarify the mathematical concepts related to the Gaussian function and its significance in probability and statistics.
Conclusion
The Multimodal RAG architecture offers a powerful and efficient solution for processing and analyzing video content. By leveraging the capabilities of OpenAI’s GPT4V and LanceDB, this approach not only simplifies the video analysis process but also enhances its accuracy and relevance. Whether for content creation, security surveillance, or educational purposes, the potential applications of this technology are vast and varied. As we continue to explore and refine these tools, the future of video analysis looks promising, with AI-driven solutions leading the way towards more insightful and actionable interpretations of video data.
Stay tuned for upcoming projects !


