

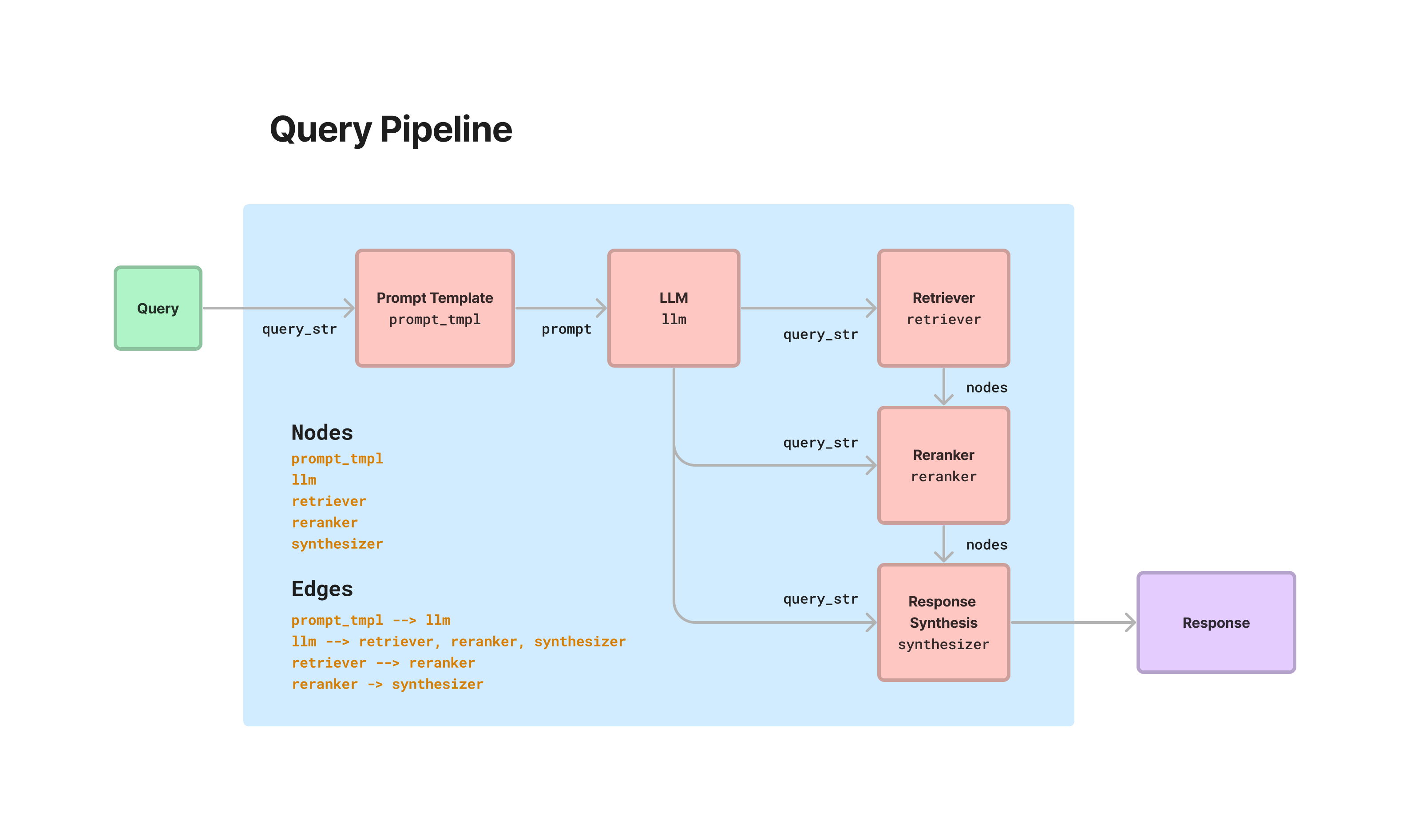
Today we introduce Query Pipelines, a new declarative API within LlamaIndex that allows you to concisely orchestrate simple-to-advanced query workflows over your data for different use cases (RAG, structured data extraction, and more).
At the core of all this is ourQueryPipeline abstraction. It can take in many LlamaIndex modules (LLMs, prompts, query engines, retrievers, itself). It can create a computational graph over these modules (e.g. a sequential chain or a DAG). It has callback support and native support with our observability partners.
The end goal is that it’s even easier to build LLM workflows over your data. Check out our comprehensive introduction guide, as well as our docs page for more details.
Context
Over the past year AI engineers have developed customized, complex orchestration flows with LLMs to solve a variety of different use cases. Over time some common patterns developed. At a top-level, paradigms emerged to query a user’s data — this includes RAG (in a narrow definition) to query unstructured data, and text-to-SQL to query structured data. Other paradigms emerged around use cases like structured data extraction (e.g. prompt the LLM to output JSON, and parse it), prompt chaining (e.g. chain-of-thought), and agents that could interact with external services (combine prompt chaining
There is a lot of query orchestration in RAG. Even within RAG itself there can be a lot of work to build an advanced RAG pipeline optimized for performance. Starting from the user query, we may want to run query understanding/transformations (re-writing, routing). We also may want to run multi-stage retrieval algorithms — e.g. top-k lookup + reranking. We may also want to use prompts + LLMs to do response synthesis in different ways. Here’s a great blog on advanced RAG components.
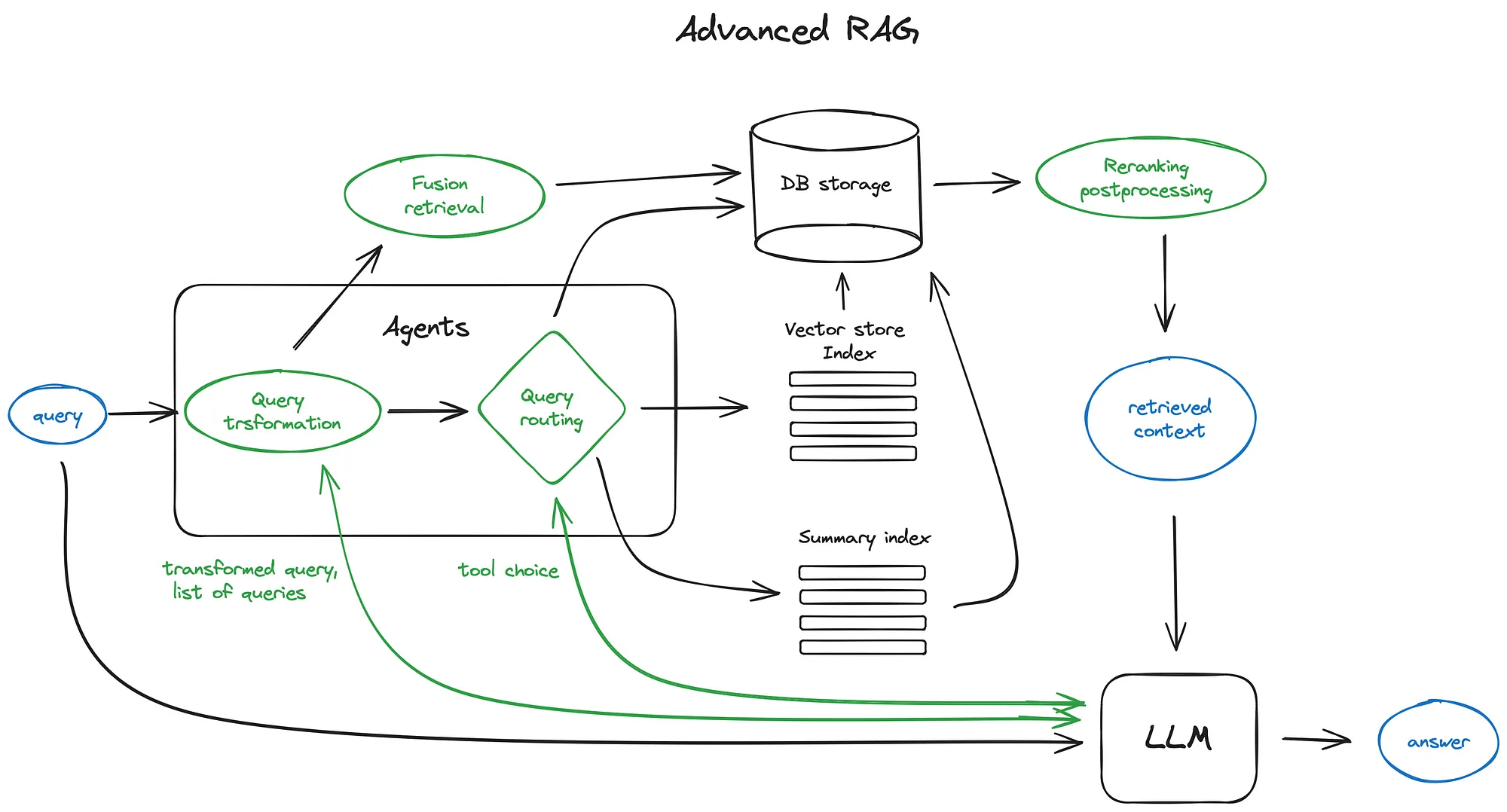
RAG has become more modular: Instead of a single way to do retrieval/RAG, developers are encouraged to pick and choose the best modules for their use cases. This sentiment is echoed in the RAG Survey paper by Gao et al.
This leads to creative new patterns like DSP, Rewrite-Retrieve-Read, or interleaving retrieval+generation multiple times.
Previous State of LlamaIndex
LlamaIndex itself has hundreds of RAG guides and 16+ Llama Pack recipes letting users setup different RAG pipelines, and has been at the forefront of establishing advanced RAG patterns.
We’ve also exposed low-level modules such as LLMs, prompts, embeddings, postprocessors and easy subclassability of core components like retrievers and query engines so that users can define their own workflows.
But up until now, we didn’t explicitly have an orchestration abstraction. Users were responsible for figuring out their own workflows by reading the API guides of each module, converting outputs to the right inputs, and using the modules imperatively.
Query Pipeline
As a result, our QueryPipeline provides a declarative query orchestration abstraction. You can use it to compose both sequential chains and directed acyclic graphs (DAGs) of arbitrary complexity.
You can already compose these workflows imperatively with LlamaIndex modules, but the QueryPipeline allows you to do it efficiently with fewer lines of code.
It has the following benefits:
- Express common query workflows with fewer lines of code/boilerplate: Stop writing converter logic between outputs/inputs, and figuring out the exact typing of arguments for each module!
- Greater readability: Reduced boilerplate leads to greater readability.
- End-to-end observability: Get callback integration across the entire pipeline (even for arbitrarily nested DAGs), so you stop fiddling around with our observability integrations.
- [In the future] Easy Serializability: A declarative interface allows the core components to be serialized/redeployed on other systems much more easily.
- [In the future] Caching: This interface also allows us to build a caching layer under the hood, allowing input re-use.
Usage
The QueryPipeline allows you to a DAG-based query workflow using LlamaIndex modules. There are two main ways to use it:
- As a sequential chain (easiest/most concise)
- As a full DAG (more expressive)
See our usage pattern guide for more details.
Sequential Chain
Some simple pipelines are purely linear in nature — the output of the previous module directly goes into the input of the next module.
Some examples:
- Prompt → LLM → Output parsing
- Retriever →Response synthesizer
Here’s the most basic example, chaining a prompt with LLM. Simply initialize QueryPipeline with the chain parameter.
# try chaining basic prompts
prompt_str = "Please generate related movies to {movie_name}"
prompt_tmpl = PromptTemplate(prompt_str)
llm = OpenAI(model="gpt-3.5-turbo")
p = QueryPipeline(chain=[prompt_tmpl, llm], verbose=True)Setting up a DAG for an Advanced RAG Workflow
Generally setting up a query workflow will require using our lower-level functions to build a DAG.
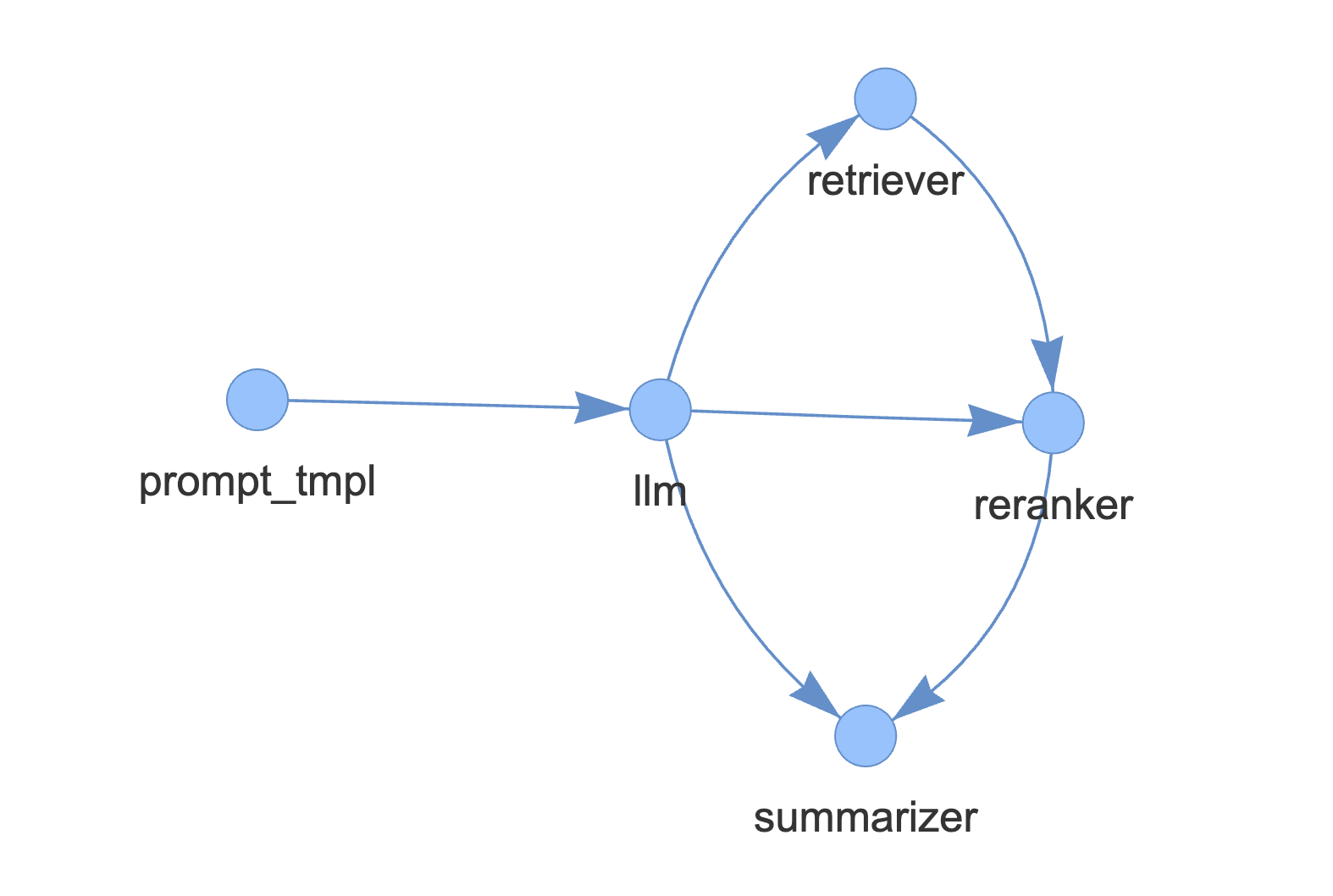
For instance, to build an “advanced RAG” consisting of query rewriting/retrieval/reranking/synthesis, you’d do something like the following.
from llama_index.postprocessor import CohereRerank
from llama_index.response_synthesizers import TreeSummarize
from llama_index import ServiceContext
# define modules
prompt_str = "Please generate a question about Paul Graham's life regarding the following topic {topic}"
prompt_tmpl = PromptTemplate(prompt_str)
llm = OpenAI(model="gpt-3.5-turbo")
retriever = index.as_retriever(similarity_top_k=3)
reranker = CohereRerank()
summarizer = TreeSummarize(
service_context=ServiceContext.from_defaults(llm=llm)
)
# define query pipeline
p = QueryPipeline(verbose=True)
p.add_modules(
{
"llm": llm,
"prompt_tmpl": prompt_tmpl,
"retriever": retriever,
"summarizer": summarizer,
"reranker": reranker,
}
)
# add edges
p.add_link("prompt_tmpl", "llm")
p.add_link("llm", "retriever")
p.add_link("retriever", "reranker", dest_key="nodes")
p.add_link("llm", "reranker", dest_key="query_str")
p.add_link("reranker", "summarizer", dest_key="nodes")
p.add_link("llm", "summarizer", dest_key="query_str")In this code block we 1) add modules, and then 2) define relationships between modules. Note that by source_key and dest_key are optional and are only required if first module has more than one output / the second module has more than one input respectively.
Running the Pipeline
If the pipeline has one “root” node and one output node, use run . Using the previous example,
output = p.run(topic="YC")
# output type is Response
type(output)If the pipeline has multiple root nodes and/or multiple output nodes, use run_multi .
output_dict = p.run_multi({"llm": {"topic": "YC"}})
print(output_dict)Defining a Custom Query Component
It’s super easy to subclass CustomQueryComponent so you can plug it into the QueryPipeline.
Check out our walkthrough for more details.
Supported Modules
Currently the following LlamaIndex modules are supported within a QueryPipeline. Remember, you can define your own!
- LLMs (both completion and chat) (
LLM) - Prompts (
PromptTemplate) - Query Engines (
BaseQueryEngine) - Query Transforms (
BaseQueryTransform) - Retrievers (
BaseRetriever) - Output Parsers (
BaseOutputParser) - Postprocessors/Rerankers (
BaseNodePostprocessor) - Response Synthesizers (
BaseSynthesizer) - Other
QueryPipelineobjects - Custom components (
CustomQueryComponent)
Check out the module usage guide for more details.
Walkthrough Example
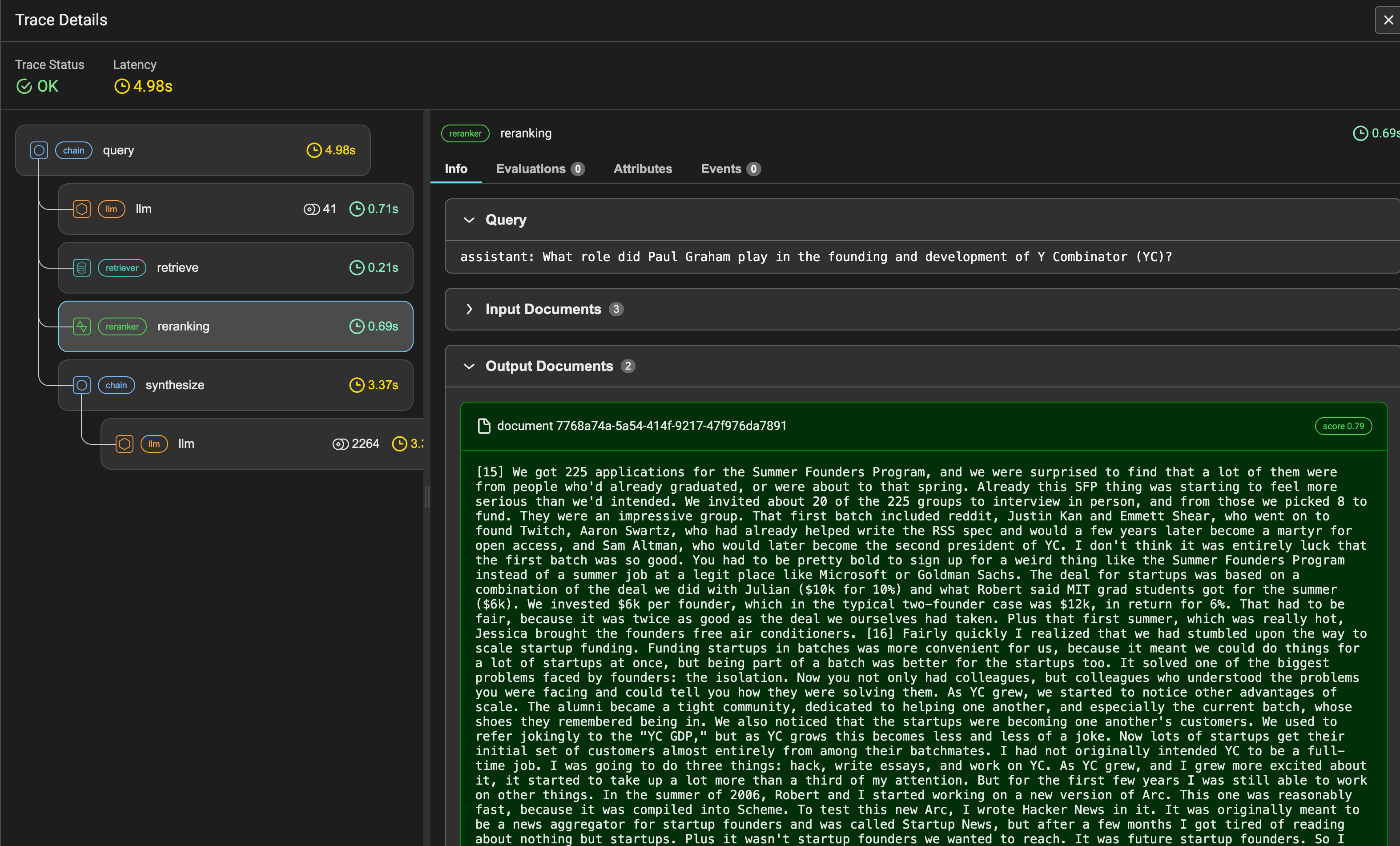
Make sure to check out our Introduction to Query Pipelines guide for full details. We go over all the steps above with concrete examples!
The notebook guide also logs traces through Arize Phoenix. You can see the full run of each QueryPipeline in the Phoenix dashboard. Our full callback support throughout every component in a QueryComponent allows you to easily integrate with any observability provider.
Related Work
The idea of a declarative syntax for building LLM-powered pipelines is not new. Related works include Haystack as well as the LangChain Expression Language. Other related works include pipelines that are setup in the no-code/low-code setting such as Langflow / Flowise.
Our main goal here was highlighted above: provide a convenient dev UX to define common query workflows over your data. There’s a lot of optimizations/guides to be done here!
FAQ
What’s the difference between a QueryPipeline and IngestionPipeline ?
Great question. Currently the IngestionPipeline operates during the data ingestion stage, and the QueryPipeline operates during the query stage. That said, there’s potentially some shared abstractions we’ll develop for both!
Conclusion + Resources
That’s it! As mentioned above we’ll be adding a lot more resources and guides soon. In the meantime check out our current guides:


