
Introduction
We are seeing a huge wave of developers building Retrieval Augmented Generation (RAG) applications. The RAG tech stack generally contains a retrieval pipeline, LLM and prompt, among which LLM is accessible and developers are comfortable with prompt customization. However, developers new to search and index often need extensive help to build an effective retrieval pipeline. A production-ready retrieval pipeline typically consists of the following components:
- Document loader that parses and splits the long text
- Embedding model serving as core indexing component
- A vector database that stores the vector embeddings
- Advanced components to future optimize retrieval quality, such as re-ranker model to judge semantic similarity better
It’s challenging to operate this complex tech stack. It involves managing software package dependencies, hosting services in Kubernetes clusters, and monitoring the performance of ML models. The high DevOps cost distracts developers from the most critical part of the user experience of RAG applications: prompt engineering, answer generation, and user interface.
While experienced search infrastructure engineers may still manage a complicated tech stack for its flexibility, Zilliz believes that most RAG developers could benefit from a retrieval API service that is user-friendly and allows for lighter customization.
Integrating Zilliz Cloud Pipelines and LlamaIndex brings a new approach to solving this problem. Zilliz Cloud Pipelines is a fully managed, scalable retrieval service. LlamaIndex is a flexible RAG framework that provides libraries and tools for organizing business logics such as retrieval and prompt engineering. The API service of Zilliz Cloud Pipelines is abstracted as a ManagedIndex in LlamaIndex. RAG developers using ZillizCloudPipelineIndex can easily scale the app from one user to millions of users without the hassle of setting up and maintaining the complex retrieval tech stack. It hides the technical complexity behind a few function calls, so that developers can focus on the core user experience of their RAG apps.
In this blog, we show how to use ZillizCloudPipelineIndex to build a high quality RAG chatbot. The chatbot is scalable and supports multi-tenancy through metadata filtering.
Set up
Since Zilliz Cloud Pipelines is an API service, first you need to set up a Zilliz Cloud account and create a free serverless cluster.
Now you can construct ZillizCloudPipelineIndex and get the handler to index docs and query later.
from llama_index.indices import ZillizCloudPipelineIndex
zcp_index = ZillizCloudPipelineIndex(
project_id="<YOUR_ZILLIZ_PROJECT_ID>",
cluster_id="<YOUR_ZILLIZ_CLUSTER_ID>",
token="<YOUR_ZILLIZ_API_KEY>",
)
zcp_index.create_pipelines(metadata_schema={"user_id": "VarChar", "version": "VarChar"})You can copy the Project ID, Cluster ID and API Key from your Zilliz account as follows:
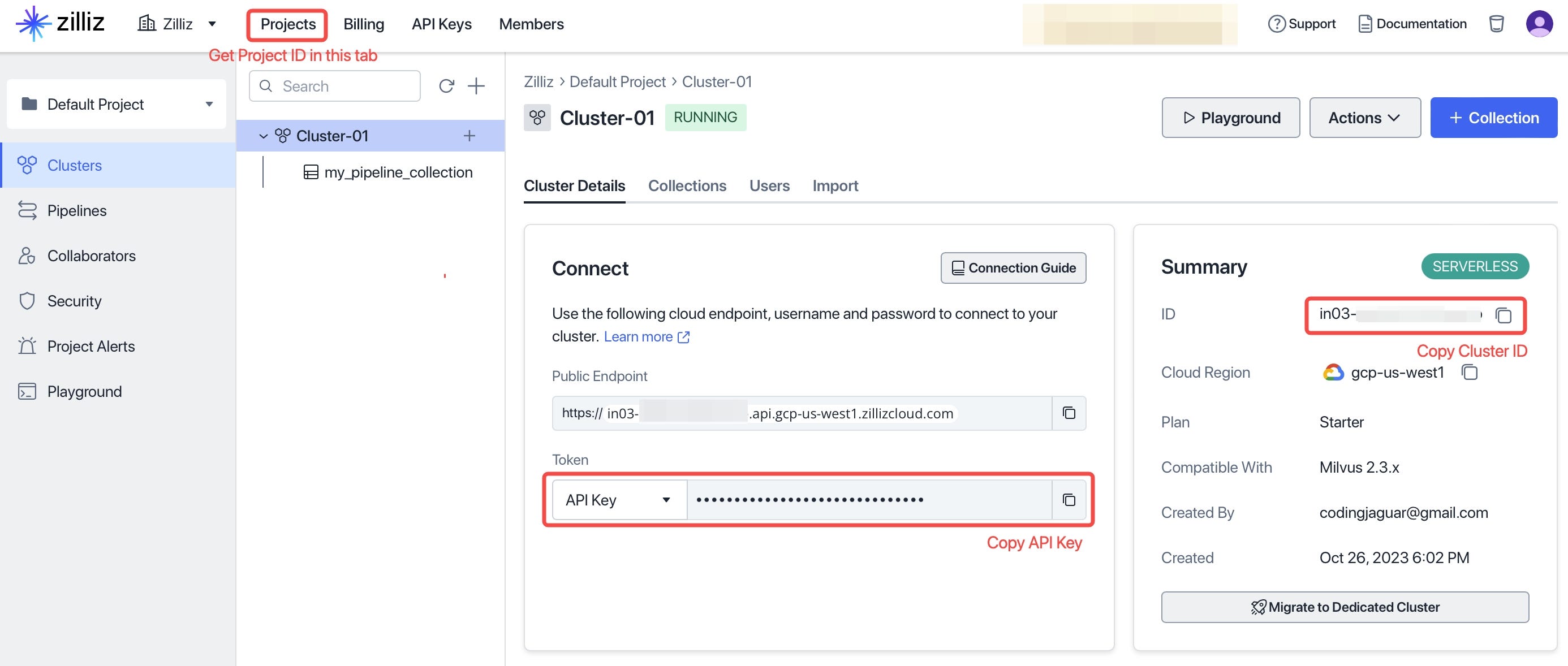

Ingest Documents
Suppose your application has multiple users, and you would like to tag each user’s document to provide isolation. Your application logic can be implemented as follows. For simplicity, here we demo ingesting public documents. Currently, Zilliz Cloud Pipelines supports documents stored and managed in AWS S3 and Google Cloud Storage. Local document upload will also be supported soon.
# user1 ingests a document, it is technical documentation for v2.3 version.
zcp_index.insert_doc_url(
url="https://publicdataset.zillizcloud.com/milvus_doc.md",
metadata={"user_id": "user1", "version": "2.3"},
)
# user2 ingests a document, it is technical documentation for v2.2 version.
zcp_index.insert_doc_url(
url="https://publicdataset.zillizcloud.com/milvus_doc_22.md",
metadata={"user_id": "user2", "version": "2.2"},
)Query
To conduct semantic search with ZillizCloudPipelineIndex, you can use it as_query_engine() by specifying a few parameters:
- search_top_k: How many text nodes/chunks to retrieve. Optional, defaults to DEFAULT_SIMILARITY_TOP_K (2).
- filters: Metadata filters. Optional, defaults to None. In this example, we set the filter to only retrieve docs of a specific user, to provide user-level data isolation.
- output_metadata: What metadata fields to return with the retrieved text node. Optional, defaults to [].
# Query the documents in ZillizCloudPipelineIndex
from llama_index.vector_stores.types import ExactMatchFilter, MetadataFilters
query_engine_for_user1 = zcp_index.as_query_engine(
search_top_k=3,
filters=MetadataFilters(
filters=[
ExactMatchFilter(key="user_id", value="user1")
] # The query would only search from documents of user1.
),
output_metadata=["user_id", "version"], # output these tags together with document text
)
question = "Can users delete entities by complex boolean expressions?"
# The chatbot will only answer with the retrieved information from user1's documents
answer = query_engine_for_user1.query(question)Thanks to the abstraction of LlamaIndex and Zilliz Cloud Pipelines, with just 30 lines of code, we can demo a RAG service that supports multi-tenancy. Most importantly, this simple RAG app could easily scale to serving millions of users without changing any code.
What to do next?
You can check out the official LlamaIndex documentation to learn about advanced customization of ZillizCloudPipelineIndex. Please ask questions at Zilliz user group or LlamaIndex discord if you have any questions. Zilliz Cloud Pipelines will soon support local file upload and more choices of embedding and re-ranker models. Get a free Zilliz Cloud account and stay tuned for more updates!


